

主从分布式爬虫
为什么要用分布式爬虫
- 学习爬虫已经有一段时间了,之前的爬虫都是一个python文件就实现的,没考虑性能,效率之类的。所以作为一个合格的spider,需要学习一下分布式爬虫。
- 什么分布式爬虫?简单地说就是用多台服务器去获取数据,让这些服务器去协同,分配各自的任务。
分布式爬虫设计
最常用的一种就是主从分布式爬虫,本文将使用Redis服务器来作为任务队列。
如图:
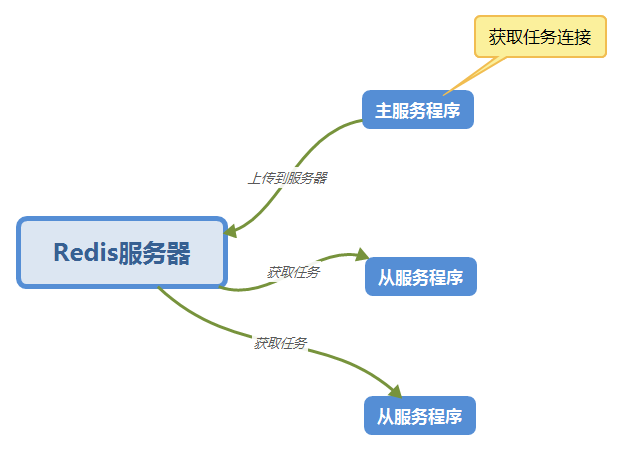
准备工作
- 安装python3和Redis
- 安装requests与Redis相关的库
pip install requests
pip install pyquery
pip install redis
代码
主函数(master.py)
import os
import requests
from pyquery import PyQuery as pq
import re
import json
import config
from cache import RedisCache
from model import Task
def parse_link(div):
'''
获取连接
'''
e = pq(div)
href = e.find('a').attr('href')
return href
def get_from_url(url):
'''
获取列表连接
'''
page = get_page(url)
e = pq(page)
items = e('.epiItem.video')
links = [parse_link(i) for i in items]
print(len(links))
links.reverse()
return links
def get_page(url):
'''
获取页面
'''
proxies = config.proxies
try:
res = requests.get(url,proxies=proxies)
# print(res.text)
except requests.exceptions.ConnectionError as e:
print('Error',e.args)
page = res.content
return page
def get_all_file(path, fileList=[]):
'''
获取目录下所有文件
'''
get_dir = os.listdir(path) #遍历当前目录,获取文件列表
for i in get_dir:
sub_dir = os.path.join(path,i) # 把第一步获取的文件加入路径
# print(sub_dir)
if os.path.isdir(sub_dir): #如果当前仍然是文件夹,递归调用
get_all_file(sub_dir, fileList)
else:
ax = os.path.abspath(sub_dir) #如果当前路径不是文件夹,则把文件名放入列表
# print(ax)
fileList.append(ax)
return fileList
def init_finish_task(path):
'''
初始化已结束任务
'''
redis_cache = RedisCache()
fileList = []
fileList = get_all_file(path, fileList)
# print(fileList)
for file in fileList:
file_name = os.path.basename(file)
task_id = file_name[:5]
# print(task_id)
redis_cache.sadd('Task:finish', task_id)
print('init_finish_task...end')
def init_task_url():
'''
初始化已结束任务url
'''
redis_cache = RedisCache()
url = config.list_url
link_list = get_from_url(url)
for link in link_list:
task_url = config.task_url_head+link
# print(task_url)
task_id = task_url[-5:]
# redis_cache.set('Task:id:{}:url'.format(task_id),task_url)
t = task_from_url(task_url)
# print('add task {}'.format(t.__dict__))
print('add task_id {}'.format(task_id))
redis_cache.set('Task:id:{}'.format(task_id), t.__dict__)
# print(t)
print('init_task_url...end')
def task_from_url(task_url):
'''
获取任务
'''
page = get_page(task_url)
e = pq(page)
task_id = task_url[-5:]
title = e('.controlBar').find('.epi-title').text().replace('/', '-').replace(':',':')
file_url = e('.audioplayer').find('audio').attr('src')
ext = file_url[-4:]
file_name = task_id+'.'+title+ext
# content = e('.epi-description').html()
t = Task()
t.id = task_id
t.title = title
t.url = task_url
t.file_name = file_name
t.file_url = file_url
# t.content = content
return t
def main():
init_task_url()
init_finish_task(config.down_folder)
if __name__ == '__main__':
main()
从函数(salver.py)
import os
import requests
from pyquery import PyQuery as pq
import re
import json
import config
from cache import RedisCache
def get_page(url):
'''
获取页面
'''
proxies = config.proxies
try:
res = requests.get(url,proxies=proxies)
# print(res.text)
except requests.exceptions.ConnectionError as e:
print('Error',e.args)
page = res.content
return page
def begin_task(task_id, file_name, file_url):
print('begin task {}'.format(task_id))
redis_cache = RedisCache()
# 添加到正在下载列表
redis_cache.sadd('Task:begin', task_id)
print('download...{}'.format(file_name))
folder = config.down_folder
path = os.path.join(folder, file_name)
download(file_url, path)
print('end task {}'.format(task_id))
def download(link, path):
redis_cache = RedisCache()
proxies = config.proxies
if os.path.exists(path):
print('file exist')
else:
try:
r = requests.get(link,proxies=proxies,stream=True)
total_length = int(r.headers['Content-Length'])
with open(path, "wb") as code:
code.write(r.content)
# 文件是否完整
length = os.path.getsize(path)
print('length={}'.format(length))
print('total_length={}'.format(total_length))
if total_length != length:
# 删除旧文件
os.remove(path)
# 重新下载
download(path, link)
else:
print('download success')
# 添加到已下载
file_name = os.path.basename(path)
content_id = file_name[:5]
redis_cache.srem('Task:begin', content_id)
redis_cache.sadd('Task:finish', content_id)
# print(r.text)
except requests.exceptions.ConnectionError as e:
print('Error',e.args)
def main():
redis_cache = RedisCache()
# 检查任务列表是否在已下载列表中
keys = redis_cache.keys('Task:id:[0-9]*')
# print(keys)
new_key = [key.decode() for key in keys]
# print(new_key)
# 按id排序
new_key = sorted(new_key,key = lambda i:int(i.split(':')[2]))
# print(new_key)
for key in new_key:
task_id = key.split(':')[2]
# print(task_id)
is_finish = redis_cache.sismember('Task:finish', task_id)
is_begin = redis_cache.sismember('Task:begin', task_id)
if is_finish==1:
print('Task {} is finish'.format(task_id))
elif is_begin==1:
print('Task {} is begin'.format(task_id))
else:
file_name = json.loads(redis_cache.get(key).decode('utf-8').replace("\'", "\""))['file_name']
file_url = json.loads(redis_cache.get(key).decode('utf-8').replace("\'", "\""))['file_url']
# print(file_url)
begin_task(task_id, file_name, file_url)
if __name__ == '__main__':
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号