

三角形的生命——英伟达的逻辑流水线
自从突破性的 Fermi 架构发布近 5 年以来,可能是时候刷新其下的主要图形架构了。Fermi 是第一个实现完全可扩展图形引擎的 NVIDIA GPU,其核心架构可以在 Kepler 和 Maxwell 中找到。下面的文章,尤其是下面的“压缩管道知识”图片应该作为基于各种公共材料的入门,例如关于 GPU 架构的白皮书或 GTC 教程。本文重点关注 GPU 工作原理的图形观点,尽管一些原则(例如着色器程序代码如何执行)对于计算来说是相同的。
管道架构图

GPU 是超级并行工作分配器
为什么这么复杂?在图形中,我们必须处理产生大量可变工作负载的数据放大。每个drawcall可能会生成不同数量的三角形。裁剪后的顶点数量与我们最初的三角形不同。在背面和深度剔除之后,并非所有三角形都需要屏幕上的像素。三角形的屏幕尺寸可能意味着它需要数百万像素或根本不需要。
因此,现代 GPU 让它们的基元(三角形、线、点)遵循逻辑流水线,而不是物理流水线。在 G80 统一架构之前(想想 DX9 硬件、ps3、xbox360)之前,流水线在芯片上以不同的阶段表示,工作会一个接一个地运行。G80 本质上为顶点和片段着色器计算重用了一些单元,具体取决于负载,但它仍然有一个用于基元/光栅化等的串行过程。借助 Fermi,流水线变得完全并行,这意味着芯片通过重用芯片上的多个引擎来实现逻辑流水线(三角形经过的步骤)。
假设我们有两个三角形 A 和 B。他们的部分工作可能在不同的逻辑流水线步骤中。A 已经被转换并且需要被光栅化。它的一些像素可能已经在运行像素着色器指令,而其他像素则被深度缓冲区(Z-cull)拒绝,其他像素可能已经被写入帧缓冲区,有些可能实际上正在等待。除此之外,我们可以获取三角形 B 的顶点。因此,虽然每个三角形都必须经过逻辑步骤,但它们中的许多可以在其生命周期的不同步骤中被主动处理。作业(在屏幕上获取 drawcall 的三角形)被分成许多较小的任务,甚至可以并行运行的子任务。每个任务都计划到可用的资源,
想象一条呈扇形散开的河流。并行管道流,彼此独立,每个人都在自己的时间线上,有些可能比其他分支更多。如果我们根据三角形对 GPU 的单元进行颜色编码,或者它当前正在处理的 drawcall,它将是多色闪烁灯 :)
GPU架构

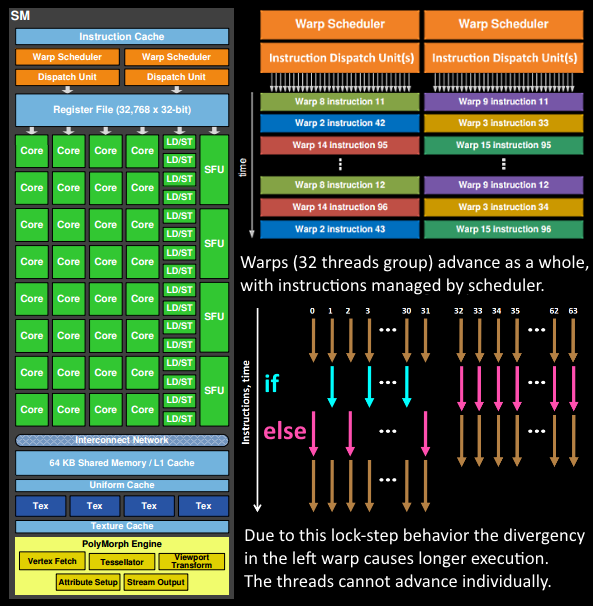
由于 Fermi NVIDIA 具有类似的原理架构。有一个Giga Thread Engine管理所有正在进行的工作。GPU 被划分为多个GPC(图形处理集群),每个 GPC 具有多个SM(流式多处理器)和一个Raster Engine。在这个过程中有很多互连,最显着的是允许跨 GPC 或其他功能单元(如ROP(渲染输出单元)子系统)迁移工作的Crossbar 。
程序员想到的工作(着色器程序执行)是在 SM 上完成的。它包含许多对线程进行数学运算的核心。例如,一个线程可以是顶点着色器或像素着色器调用。这些核心和其他单元由Warp 调度程序驱动,它们管理一组 32 个线程作为 warp 并将要执行的指令交给调度单元。代码逻辑由调度程序处理,而不是在内核本身内部,它只会看到类似“将寄存器 4234 与寄存器 4235 相加并存储在 4230 中”的内容从调度员。与核心非常智能的 CPU 相比,核心本身相当愚蠢。GPU 将智能提升到更高的水平,它执行整个集成(或多个,如果你愿意的话)的工作。
这些单元中有多少实际上在 GPU 上(每个 GPC 有多少个 SM,多少个 GPC..)取决于芯片配置本身。正如您在上面看到的,GM204 有 4 个 GPC,每个 4 个 SM,但 Tegra X1 有 1 个 GPC 和 2 个 SM,两者都采用 Maxwell 设计。SM 设计本身(核心数量、指令单元、调度程序......)也随着时间的推移而发生了变化(见第一张图片),并帮助芯片变得如此高效,它们可以从高端台式机扩展到笔记本电脑移动的。
逻辑管道
为简单起见,省略了一些细节。我们假设 drawcall 引用了一些索引和顶点缓冲区,这些缓冲区已经填充了数据并存在于 GPU 的 DRAM 中,并且仅使用顶点和像素着色器(GL:fragmentsshader)。
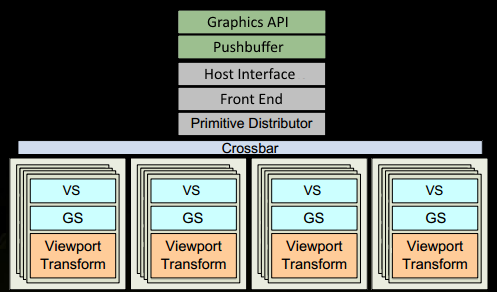
- 该程序在图形 api(DX 或 GL)中进行绘制调用。这会在某个时候到达驱动程序,该驱动程序会进行一些验证以检查事情是否“合法”,并将命令插入到pushbuffer内的 GPU 可读编码中。在 CPU 方面可能会发生很多瓶颈,这就是为什么程序员使用好 api 以及利用当今 GPU 的强大功能的技术很重要的原因。
- 在一段时间或明确的“刷新”调用之后,驱动程序已经在 pushbuffer 中缓冲了足够的工作并将其发送给 GPU 处理(操作系统的一些参与)。GPU的主机接口接收通过前端处理的命令。
- 我们通过处理 indexbuffer 中的索引并生成我们发送到多个 GPC 的三角形工作批次,在Primitive Distributor中开始我们的工作分配。
- 在 GPC 中,其中一个 SM 的Poly Morph Engine负责从三角形索引 ( Vertex Fetch ) 中获取顶点数据。
- 获取数据后,32 个线程的 warp 被安排在 SM 内,并将在顶点上工作。
- SM 的 warp 调度程序按顺序发出整个 warp 的指令。线程以锁步方式运行每条指令,如果它们不应该主动执行它,可以单独屏蔽。需要这种掩蔽可能有多种原因。例如,当当前指令是“if (true)”分支的一部分并且线程特定数据评估为“false”时,或者当一个线程达到循环的终止标准但另一个线程未达到时。因此,在着色器中有大量分支发散会显着增加扭曲中所有线程所花费的时间。线程不能单独前进,只能作为经线!然而,经线是相互独立的。
- warp 的指令可能会一次完成,也可能需要几个调度轮次。例如,与执行基本数学运算相比,SM 通常具有更少的加载/存储单元。
- 由于某些指令比其他指令需要更长的时间来完成,尤其是内存加载,warp 调度程序可能会简单地切换到另一个不等待内存的 warp。这是 GPU 如何克服内存读取延迟的关键概念,它们只是切换活动线程组。为了使这种切换非常快,调度程序管理的所有线程在寄存器文件中都有自己的寄存器。着色器程序需要的寄存器越多,线程/扭曲的空间就越少。我们可以在之间切换的扭曲越少,在等待指令完成(最重要的内存获取)时我们可以做的有用工作就越少。
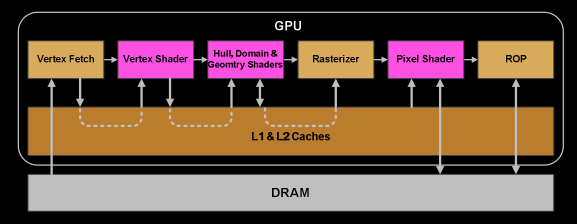
- 一旦扭曲完成了顶点着色器的所有指令,它的结果将由Viewport Transform处理。三角形被裁剪空间体积裁剪并准备好进行光栅化。我们对所有这些跨任务通信数据使用 L1 和 L2 缓存。
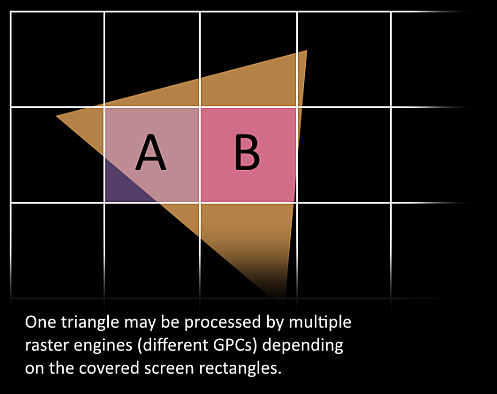
- 现在它变得令人兴奋,我们的三角形即将被切碎,并可能离开它目前所在的 GPC。三角形的边界框用于决定哪些光栅引擎需要对其进行处理,因为每个引擎都覆盖了屏幕的多个图块。它通过Work Distribution Crossbar将三角形发送到一个或多个 GPC 。我们现在有效地将我们的三角形分割成许多较小的工作。
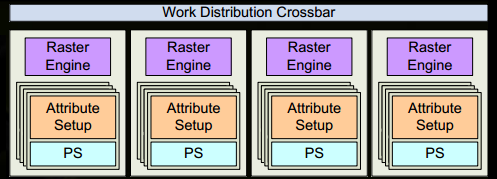
- 目标 SM 的属性设置将确保插值(例如我们在顶点着色器中生成的输出)采用像素着色器友好格式。
- GPC的光栅引擎处理它接收到的三角形,并为它负责的那些部分生成像素信息(还处理背面剔除和 Z 剔除)。
- 我们再次批量处理 32 个像素线程,或者更好地说是 8 次 2x2 像素四边形,这是我们在像素着色器中始终使用的最小单元。这个 2x2 四边形允许我们计算诸如纹理 mip 映射过滤之类的导数(四边形内纹理坐标的大变化会导致更高的 mip)。2x2 四边形中样本位置实际上并未覆盖三角形的那些线程将被屏蔽(gl_HelperInvocation)。本地 SM 的扭曲调度程序之一将管理像素着色任务。
- 与我们在顶点着色器逻辑阶段相同的扭曲调度程序指令游戏现在在像素着色器线程上执行。锁步处理特别方便,因为我们几乎可以免费访问像素四边形中的值,因为所有线程都保证将其数据计算到相同的指令点(NV_shader_thread_group)。

- 我们到了吗?几乎,我们的像素着色器已经完成了要写入渲染目标的颜色的计算,并且我们还有一个深度值。在这一点上,我们必须考虑三角形的原始 api 排序,然后再将该数据交给 ROP(渲染输出单元)子系统之一,该子系统本身具有多个 ROP 单元。这里执行深度测试,与帧缓冲区混合等。这些操作需要以原子方式进行(一次设置一种颜色/深度),以确保我们没有一个三角形的颜色和另一个三角形的深度值,当它们都覆盖相同的像素时。NVIDIA 通常应用内存压缩来降低内存带宽要求,从而增加“有效”带宽(请参阅GTX 980 pdf)。
噗!我们完成了,我们已经将一些像素写入渲染目标。我希望这些信息有助于理解 GPU 中的一些工作/数据流。它还可能有助于理解为什么与 CPU 同步确实有害的另一个副作用。必须等到一切都完成并且没有新工作提交(所有单元都空闲),这意味着在发送新工作时,需要一段时间才能再次完全加载,尤其是在大型 GPU 上。
在下图中,您可以看到我们如何渲染 CAD 模型并通过对图像有贡献的不同 SM 或 warp id 对其进行着色(NV_shader_thread_group)。结果不会是帧连贯的,因为工作分配会因帧而异。场景是使用许多绘图调用渲染的,其中几个也可以并行处理(使用 NSIGHT,您也可以看到一些绘图调用并行性)。

进一步阅读
- Fabian Giesen的图形管道之旅
- Paulius Micikevicius的性能优化指南及其背后的 GPU 架构
- Pomegranate: A Fully Scalable Graphics Architecture描述了并行阶段的概念和它们之间的工作分配。
- 植物大战僵尸必读


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程