
UDW 云数据仓库
产品简介
UDW(UCloud Data Warehouse)是大规模并行处理数据仓库产品,提供Greenplum和Udpg两种可选的类型。Greenplum是EMC开源的数据仓库,Udpg是基于PostgreSQL开发的大规模并行、完全托管的PB级数据仓库服务。UDW支持JSON类型,可用通过SQL让数据分析更简单、高效,为互联网、物联网、金融、电信等行业提供丰富的业务分析能力
云数据仓库UDW的特性
- 海量存储分析:支持百GB到上PB级别的数据存储和分析
- 实时分析:通过准实时、实时的数据加载,实现对数据仓库的实时更新,从而对业务进行实时分析
- 简单易用:丰富的OLAP SQL语法及函数,用sql让数据分析变得简单、高效
- 多种数据存储方式:行存储、列存储、HDFS外部表、ufile外部表让存储多样化
- 线性扩展:通过增加节点可以线性的提高系统的存储和计算能力
- 稳定可靠:除了硬件raid之外,所有的数据都是双机热备,同时还会定期的冷备
- 支持JSON类型:让JSON格式的数据处理更方便
云数据仓库UDW使用场景
- 整合BI系统:UDW的OLAP分析能力,可以给报表多维分析提供有效的性能保障,并且可以实现从百GB到上PB平滑扩展。
- 对接监控系统:可以通过对监控数据的实时加载和分析、找出监控指标的异常。
- 分析业务数据:实时对业务数据分析、可以帮用户快速做出决策。
- 汇总不同来源的数据:把mysql、日志等不同来源的数据汇总到UDW、结合业务数据和日志对业务进行汇总、深度分析。
利用UHadoop和UDW构建大数据服务平台
在分析构建大数据服务平台之前,我们先看看大数据应用场景,常见的大数据应用场景如下:
- 离线/批量分析:离线/批量分析一般对实时性要求不高,大部分都是小时、天级别的周期性任务,这部分我们用Hive/MapReduce/UDW来实现;
- 数据仓库/数据分析查询:此类场景会有很多查询需求,并且大部分查询是临时性的,如果对实时性要求不高可以使用Hive,如果对实时性要求比较高的话可以使用Spark SQL或者UDW;
- 在线服务:在线服务一般都要快速响应,比较适合使用Hbase或者UDW来满足需求;
- 流式处理:一般要求数据不落地,实时收集、实时处理、实时决策,我们可以借助Kafka Spark Streaming来应对流失处理场景;
- 数据挖掘/机器学习:主要是在现有数据上面进行基于各种算法的计算,起到预测的效果,从而实现一些高级别数据分析的需求,我们可以利用Spark MLlib提供的丰富的机器学习库来轻松应对数据深层分析。
产品架构
云数据仓库产品架构
云数据库仓库 UDW 服务的架构图如下所示:
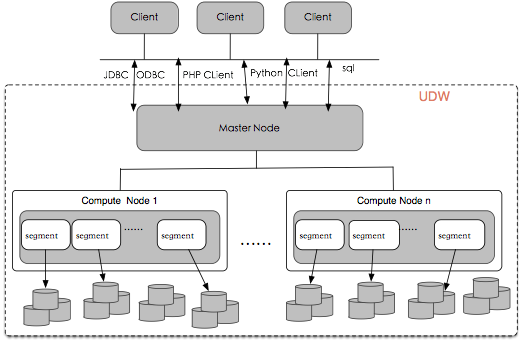
UDW 采用无共享的 MPP 架构,适用于海量数据的存储和计算。UDW 的架构如上图所示,主要有 Client、Master Node 和 Compute Node 组成。基本组成部分的功能如下:
- Client:访问 UDW 的客户端
- 支持通过 JDBC、ODBC、PHP、Python、命令行 Sql 等方式访问 UDW
- Master Node:访问 UDW 数据仓库的入口
- 接收客户端的连接请求
- 负责权限认证
- 处理 SQL 命令
- 调度分发执行计划
- 汇总 Segment 的执行结果并将结果返回给客户端
- Compute Node:
- Compute Node 管理节点的计算和存储资源
- 每个 Compute Node 由多个 Segment 组成
- Segment 负责业务数据的存储、用户 SQL 的执行

