
pandas库学习
引言:pandas库基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
1.创建数据
pandas库创建数据主要通过两种方式:读取本地文件和手动创建数据
1.1读取本地文件(支持csv,xlsx,xls等等)
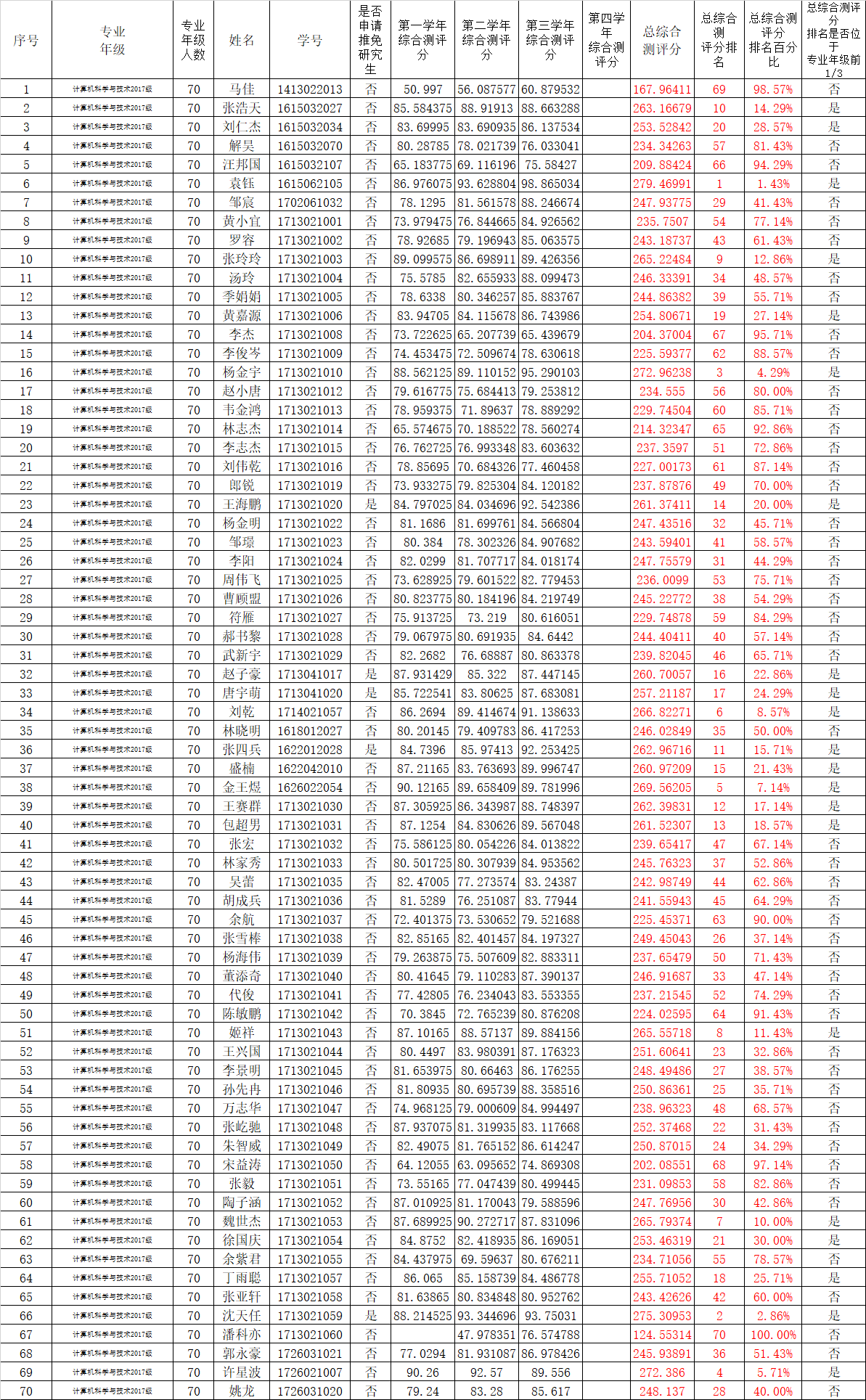
data=pandas.read_excel("learn.xls")
其中learn.xls是我放在当前目录下一个excel文件,本文将以该文件作为例子介绍pandas库。
该excel文件是某所大学官网提供的当年保研学生成绩相关公示信息。(仅供学习所用,不作商业用途)
1.2手动创建数据:
data2={ 'name':["sky","gw","cmm"], 'age':[18,20,23], 'location':["yangzhou","suzhou","suqian"] } data_pandas=pandas.DataFrame(data2)
首先创建一个data2的字典,再将字典模式转换成对应的DataFrame类型,其中DataFrame类型就相当于一个矩阵,其中每一列数据都是series类型。
打印一下:
name age location 0 sky 18 yangzhou 1 gw 20 suzhou 2 cmm 23 suqian
第一列表示序号,从0开始,其余都是字典中一一对应的key和value。
2.pandas常用函数方法:
#函数方法 print(type(data)) print(data.dtypes) print(data.shape)#矩阵的大小 print(data.columns)#列名
其中type(data)是整个数据的类型对应DataFrame,
而data.dtype对应的是每个series的类型,即每一列元素的数据类型。
结果如下:
<class 'pandas.core.frame.DataFrame'> 序号 int64 专业\n年级 object 专业年级\n人数 int64 姓名 object 学号 int64 是否申请推免研究生 object 第一学年\n综合测评分 float64 第二学年\n综合测评分 float64 第三学年\n综合测评分 float64 第四学年\n综合测评分 float64 总综合\n测评分 float64 总综合测\n评分排名 int64 总综合测评分\n排名百分比 float64 总综合测评分\n排名是否位于\n专业年级前1/3 object dtype: object (70, 14) Index(['序号', '专业\n年级', '专业年级\n人数', '姓名', '学号', '是否申请推免研究生', '第一学年\n综合测评分', '第二学年\n综合测评分', '第三学年\n综合测评分', '第四学年\n综合测评分', '总综合\n测评分', '总综合测\n评分排名', '总综合测评分\n排名百分比', '总综合测评分\n排名是否位于\n专业年级前1/3'], dtype='object')
由于我是直接导入的excel文件所以,列名中存在一些换行符即\n。
3.取数据相关方法:
其中DataFrame对象有head()和tail()方法,来获取数据集中前n行数据和后n行数据:
print(data.head(5))#前5个 print(data.tail(4))#后4个
结果如下:
序号 专业\n年级 ... 总综合测评分\n排名百分比 总综合测评分\n排名是否位于\n专业年级前1/3 0 1 计算机科学与技术2017级 ... 0.985714 否 1 2 计算机科学与技术2017级 ... 0.142857 是 2 3 计算机科学与技术2017级 ... 0.285714 是 3 4 计算机科学与技术2017级 ... 0.814286 否 4 5 计算机科学与技术2017级 ... 0.942857 否 [5 rows x 14 columns] 序号 专业\n年级 ... 总综合测评分\n排名百分比 总综合测评分\n排名是否位于\n专业年级前1/3 66 67 计算机科学与技术2017级 ... 1.000000 否 67 68 计算机科学与技术2017级 ... 0.514286 否 68 69 计算机科学与技术2017级 ... 0.057143 是 69 70 计算机科学与技术2017级 ... 0.400000 否 [4 rows x 14 columns]
因为内容过多,我选用IDE中的pycharm进行编译,中间内容被省略了;如果安装了anaconda,可以使用jy编译;
说句废话,我之所以用pycharm而不用后者,原因是pycharm查看源码比较方便,便于初学者学习。
回归正题,我们取到前5行数据和后4行数据,当然我们还可以指定获取某一行数据:
print(data.loc[0])#取第一个样本数据 print(data.loc[1:2])#取第二个和第三个样本 grade=data["总综合\n测评分"]#打印某一列数据 print(grade)
结果如下:
序号 1 专业\n年级 计算机科学与技术2017级 专业年级\n人数 70 姓名 马佳 学号 1413022013 是否申请推免研究生 否 第一学年\n综合测评分 50.997 第二学年\n综合测评分 56.0876 第三学年\n综合测评分 60.8795 第四学年\n综合测评分 NaN 总综合\n测评分 167.964 总综合测\n评分排名 69 总综合测评分\n排名百分比 0.985714 总综合测评分\n排名是否位于\n专业年级前1/3 否 Name: 0, dtype: object 序号 专业\n年级 ... 总综合测评分\n排名百分比 总综合测评分\n排名是否位于\n专业年级前1/3 1 2 计算机科学与技术2017级 ... 0.142857 是 2 3 计算机科学与技术2017级 ... 0.285714 是 0 167.964109 1 263.166793 2 253.528419 3 234.342630 4 209.884241 ... 65 275.309530 66 124.553138 67 245.938913 68 272.386000 69 248.137000
当打印第一行数据时,数据量较少内容全部展示出来,打印某一列数据也能够展示如上图,我们验证一下它的类型是否是之前介绍的series:
print(type(grade))
<class 'pandas.core.series.Series'>
确实是series类型,当然series也有不少函数方法,但是几乎都能通过DataFrame中方法实现,所以不再一一赘述。
打印几列数据时,可以把列名放入一个数组传入:
list=["总综合\n测评分","是否申请推免研究生"]#打印几列数据 listdata=data[list] print(listdata)
总综合\n测评分 是否申请推免研究生 0 167.964109 否 1 263.166793 否 2 253.528419 否 3 234.342630 否 4 209.884241 否 .. ... ... 65 275.309530 是 66 124.553138 否 67 245.938913 否 68 272.386000 否 69 248.137000 否 [70 rows x 2 columns]
4.数据预处理
细心的朋友可能发现了,这个excel表中第67行缺少数据,缺失的是第一学年的成绩,可能是因为各种原因没有完成相关学业。

这样一来我们发现他的综测总分只有124分,和别的同学差了一大截,这对于数据分析来说很致命。
当然我们有两组解决途径:
一是:当所有NaN即缺失值设为0,这种做法优点在于简单易操作,但缺点是造成数据波动很大,不利于数据分析。
二是:将缺失值设置为该列非缺失值的平均值,用均值才代替缺失值。
我采用了第二种方法通过一个函数实现:
#空值处理,用不含空值的均值填充 def deal_nan(data): cols=data.columns.tolist()#将所有列放入列表 for col in cols:#遍历每一列 if data[col].dtype != 'object':#缺失值数据类型不为object类型时用均值替代 col_is_null=pandas.isnull(data[col])#判断该列中每一行数据是否为空 validaverage=data[col][col_is_null==False].mean()#将该列中非空的值取均值 data[col].fillna(validaverage, inplace=True)#将缺失值用均值替代。 else: data[col].fillna('缺失数据', inplace=True)#object类型,用缺失数据替代 print(data["第一学年\n综合测评分"]) deal_nan(data)
通过这个函数直接完成了数据的预处理,object类型与python面向对象那个object不同,这里的object把它理解成string类型更容易理解;
fillna函数用来填充NaN值,inplace表示是否替代NaN。
直接显示下结果:
0 50.997000
1 85.584375
2 83.699950
3 80.287850
4 65.183775
...
65 88.214525
66 80.312378
67 77.029400
68 90.260000
69 79.240000
因为下标从0开始,所以对应66号,得分为80.312378,可见第一学年该专业参加考试的均分为80.312378。
我们之后的数据处理,都将用均值来填充NaN。
这组数据中,只有三年的总分,却没有平均分,所以数据比较起来差距有些大,我们不妨用三年均分来表现各个学生的学生状况,
所以我们计算并且把计算的结果放入到DataFrame这个数据集中:
averagegrade=(data["第一学年\n综合测评分"]+data["第二学年\n综合测评分"]+data["第三学年\n综合测评分"])/3 data["average"]=averagegrade; print(data["average"])
新产生的列取名‘average’打印一下:
0 55.988036
1 87.722264
2 84.509473
3 78.114210
4 69.961414
...
65 91.769843
66 68.288505
67 81.979638
68 90.795333
69 82.712333
得到了各个学生的三年综测均分。
5.数据排序筛选
这个数据集是针对学生保研情况,保研通常选取较为优秀的学生,所以我们需要根据学生三年的综测均分进行排序:
data.sort_values("average",inplace=True)#从小到大 print(data[['学号','姓名','average']])
学号 姓名 average 0 1413022013 马佳 55.988036 57 1713021050 宋益涛 67.361837 13 1713021008 李杰 68.123348 66 1713021060 潘科亦 68.288505 4 1615032107 汪邦国 69.961414 .. ... ... ... 37 1626022054 金王煜 89.854018 68 1726021007 许星波 90.795333 15 1713021010 杨金宇 90.987460 65 1713021059 沈天任 91.769843 5 1615062105 袁钰 93.156638
inplace=True表示根据排序后数据进行更新。
最好的学生放到最后那可不行,我们试试倒序:
data.sort_values("average",inplace=True,ascending=False)#从大到小 print(data[['学号','姓名','average']])
ascending=False,这个在数据库里也很常见用于倒序:
[70 rows x 3 columns] 学号 姓名 average 5 1615062105 袁钰 93.156638 65 1713021059 沈天任 91.769843 15 1713021010 杨金宇 90.987460 68 1726021007 许星波 90.795333 37 1626022054 金王煜 89.854018 .. ... ... ... 4 1615032107 汪邦国 69.961414 66 1713021060 潘科亦 68.288505 13 1713021008 李杰 68.123348 57 1713021050 宋益涛 67.361837 0 1413022013 马佳 55.988036
loc()方法不仅仅可以用于定位,还能帮助判断:
print(data.loc[data["是否申请推免研究生"]=="是"])#判断 print(data.loc[data["是否申请推免研究生"]=="是",['学号','姓名','average']])#判断打印相关数据
直接显示结果,没什么好解释的。。
序号 专业\n年级 ... 总综合测评分\n排名是否位于\n专业年级前1/3 average 65 66 计算机科学与技术2017级 ... 是 91.769843 35 36 计算机科学与技术2017级 ... 是 87.655718 22 23 计算机科学与技术2017级 ... 是 87.124702 31 32 计算机科学与技术2017级 ... 是 86.900192 32 33 计算机科学与技术2017级 ... 是 85.737291 [5 rows x 15 columns] 学号 姓名 average 65 1713021059 沈天任 91.769843 35 1622012028 张四兵 87.655718 22 1713021020 王海鹏 87.124702 31 1713041017 赵子豪 86.900192 32 1713041020 唐宇萌 85.737291
可以看到有五名学生申请了推免。
再来看看推免学生和非推免学生的均分:
all_data=data.pivot_table(index="是否申请推免研究生",values="average",aggfunc="mean") print(all_data)
pivot_table方法会根据有多少种不同的index,得到不同value,默认使用mean方法取均值,也可以手动修改sum等等方法或自定义方法。
average 是否申请推免研究生 否 80.955645 是 87.837549
pycharm排版有些问题。。。
6.函数调用
可能现在有一些需求,需要判断这些学生是否达到毕业要求,根据成绩判断其优秀或良好或不及格等等。这就需要我们自己定义函数
def learning_position(data): grade=data['average'] if grade>90 or grade==90: return '优秀' elif grade>75 or grade==75 and grade<90: return '良好' elif grade<75 and grade>60 or grade==60: return '及格' else: return '不及格' data['position']=data.apply(learning_position,axis=1) print(data)
这就是我定义的一个函数,对于三年的均分进行判别;
其中apply()函数是对该数据集调用括号内的方法,axis=1表示对数据的行进行处理,将每一行处理的结果赋给该行下position,得到一个新的列:
序号 专业\n年级 专业年级\n人数 ... 总综合测评分\n排名是否位于\n专业年级前1/3 average position 5 6 计算机科学与技术2017级 70 ... 是 93.156638 优秀 65 66 计算机科学与技术2017级 70 ... 是 91.769843 优秀 15 16 计算机科学与技术2017级 70 ... 是 90.987460 优秀 68 69 计算机科学与技术2017级 70 ... 是 90.795333 优秀 37 38 计算机科学与技术2017级 70 ... 是 89.854018 良好 .. .. ... ... ... ... ... ... 4 5 计算机科学与技术2017级 70 ... 否 69.961414 及格 66 67 计算机科学与技术2017级 70 ... 否 68.288505 及格 13 14 计算机科学与技术2017级 70 ... 否 68.123348 及格 57 58 计算机科学与技术2017级 70 ... 否 67.361837 及格 0 1 计算机科学与技术2017级 70 ... 否 55.988036 不及格
由于之前已经完成了逆序排序,并且inplace=True,所以现在再来看成绩单,学生属性就很鲜明了。
好了终于更完了,该数据集还会运用于matplotlib的学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号