Kubernetes组件介绍
一、APIserver
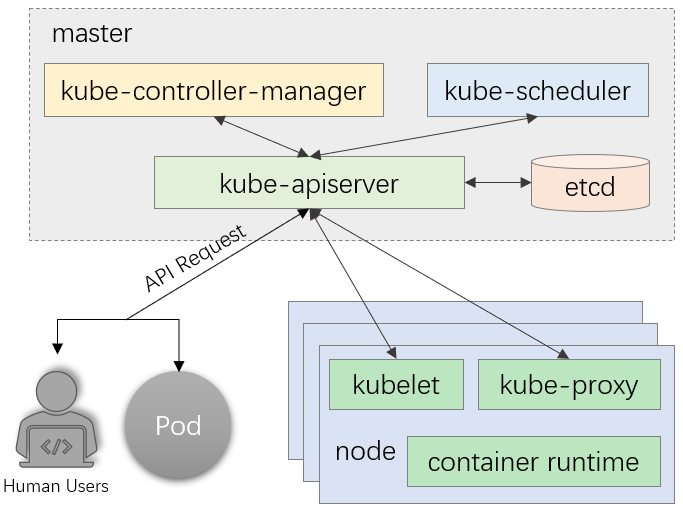
1、API Server是Kubernetes集群的网关,是能够与etcd通信惟一入口
(1)kube-controller-manager、kube-scheduler、kubelet、kube-proxy,以及后续部署的集群插件CoreDNS、Project Calico等,彼此间互不通信,彼此间的所有协作均经由API Server的REST API进行,它们都是API Server的客户端
(2)确保对API Server的安全访问至关重要
a、客户端对API Server的访问应经过身份验证及权限检查;
• 认证 Authentication;
• 授权 Authorization;
• 准入 Admission(Mutating & Valiating)。
b、为防止中间人攻击,各类客户端与API Server间的通信都应使用TLS进行加密
2、提供其他模块之间的数据交互和通信的枢纽(其他模块通过 APIServer 查询或修改数据,只有 APIServer 才直接操作 etcd)。
3、APIServer 提供 etcd 数据缓存以减少集群对 etcd 的访问
二、etcd
etcd 是 CoreOS 基于 Raft 开发的分布式 key-value 存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)。
1、主要功能
• 基本的 key-value 存储;
• 监听机制;
• key 的过期及续约机制,用于监控和服务发现;
• 原子 CAS 和 CAD,用于分布式锁和 leader 选举。
2、使用场景
1)键值对存储
etcd 是一个键值存储的组件,其他的应用都是基于其键值存储的功能展开。
• 采用kv型数据存储,一般情况下比关系型数据库快。
• 支持动态存储(内存)以及静态存储(磁盘)。
• 分布式存储,可集成为多节点集群。
• 存储方式,采用类似目录结构。(B+tree)
只有叶子节点才能真正存储数据,相当于文件。
叶子节点的父节点一定是目录,目录不能存储数据。
2)服务注册与发现
a、强一致性、高可用的服务存储目录。
• 基于 Raft 算法的 etcd 天生就是这样一个强一致性、高可用的服务存储目录。
b、 一种注册服务和服务健康状况的机制。
• 用户可以在 etcd 中注册服务,并且对注册的服务配置 key TTL,定时保持服务的心跳以达到监控健康状态的效果
3)消息发布与订阅
• 在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅。
• 即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者。
• 通过这种方式可以做到分布式系统配置的集中式管理与动态更新。
• 应用中用到的一些配置信息放到etcd上进行集中管理。
• 应用在启动的时候主动从etcd获取一次配置信息,同时,在etcd节点上注册一个Watcher并等待,以后每次配置有更新的时候,etcd都会实时通知订阅者,以此达到获取最新配置信息的目的。
3、Raft协议
http://thesecretlivesofdata.com/raft/ 动画演示
1)选举方法
• 初始启动时,节点处于follower状态并被设定一个election timeout,如果在这一时间周期内没有收到来自 leader 的 heartbeat,节点将发起选举:将自己切换为 candidate 之后,向集群中其它 follower节点发送请求,询问其是否选举自己成为 leader。
• 当收到来自集群中过半数节点的接受投票后,节点即成为 leader,开始接收保存 client 的数据并向其它的 follower 节点同步日志。如果没有达成一致,则candidate随机选择一个等待间隔(150ms ~300ms)再次发起投票,得到集群中半数以上follower接受candidate将成为leader
• leader节点依靠定时向 follower 发送heartbeat来保持其地位。
• 任何时候如果其它 follower 在 election timeout 期间都没有收到来自 leader 的 heartbeat,同样会将自己的状态切换为 candidate 并发起选举。每成功选举一次,新 leader 的任期(Term)都会比之前leader 的任期大1。
2)日志复制
当接Leader收到客户端的日志(事务请求)后先把该日志追加到本地的Log中,然后通过heartbeat把该Entry同步给其他Follower,Follower接收到日志后记录日志然后向Leader发送ACK,当Leader收到大多数(n/2+1)Follower的ACK信息后将该日志设置为已提交并追加到本地磁盘中,通知客户端并在下个heartbeat中Leader将通知所有的Follower将该日志存储在自己的本地磁盘中。
3)安全性
安全性是用于保证每个节点都执行相同序列的安全机制,如当某个Follower在当前Leadercommit Log时变得不可用了,稍后可能该Follower又会被选举为Leader,这时新Leader可能会用新的Log覆盖先前已committed的Log,这就是导致节点执行不同序列;Safety就是用于保证选举出来的Leader一定包含先前 committed Log的机制;
选举安全性(Election Safety):每个任期(Term)只能选举出一个Leader
Leader完整性(Leader Completeness):指Leader日志的完整性,当Log在任期Term1被Commit后,那么以后任期Term2、Term3…等的Leader必须包含该Log;Raft在选举阶段就使用Term的判断用于保证完整性:当请求投票的该Candidate的Term较大或Term相同Index更大则投票,否则拒绝该请求
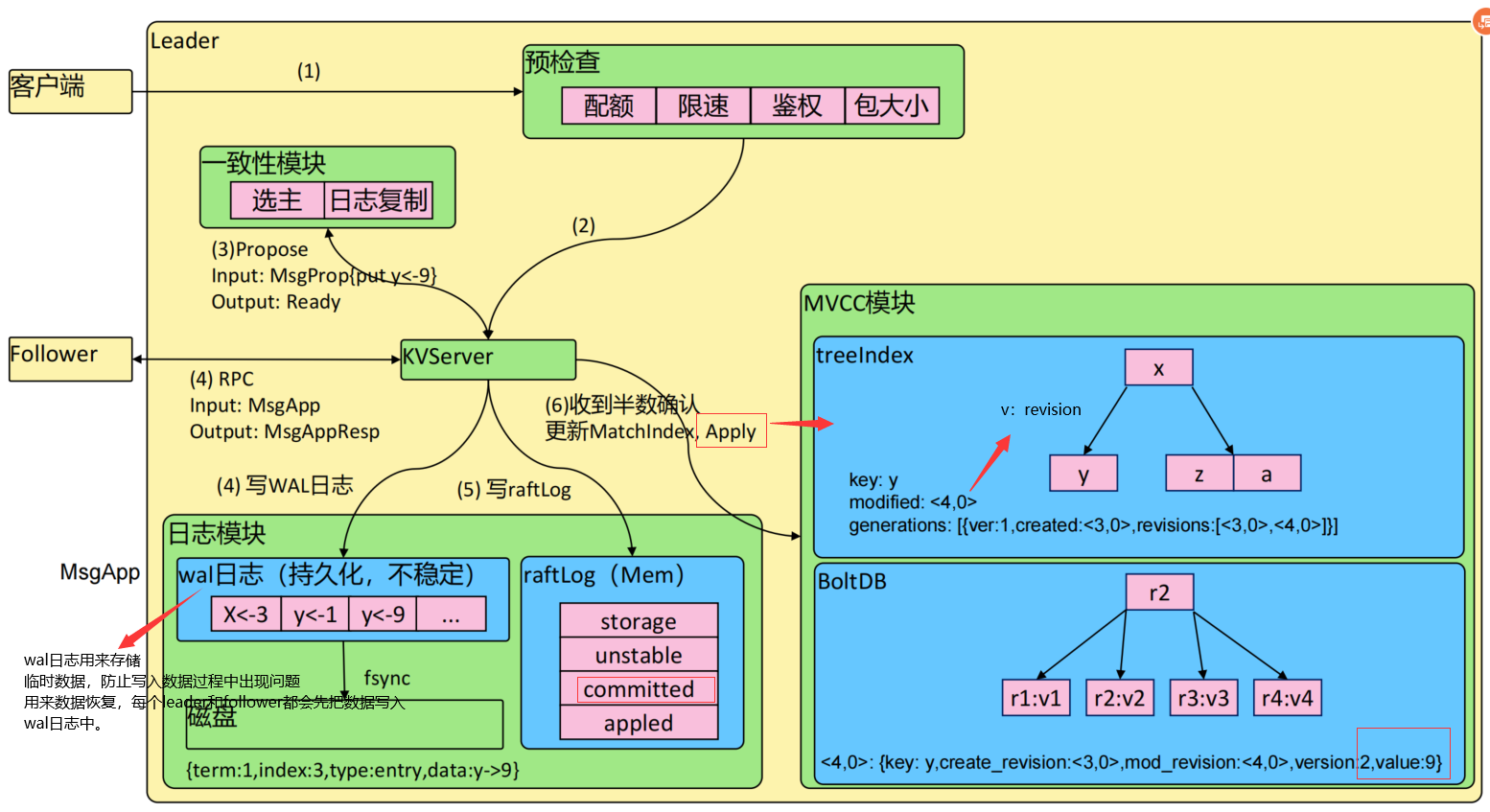
4)wal日志
wal日志是二进制的,解析出来后是以上数据结构LogEntry。其中第一个字段type,只有两种,一种是0表示Normal,1表示ConfChange(ConfChange表示 Etcd 本身的配置变更同步,比如有新的节点加入等)。第二个字段是term,每个term代表一个主节点的任期,每次主节点变更term就会变化。第三个字段是index,这个序号是严格有序递增的,代表变更序号。第四个字段是二进制的data,将raft request对象的pb结构整个保存下。etcd 源码下有个tools/etcddump-logs,可以将wal日志dump成文本查看,可以协助分析Raft协议。
Raft协议本身不关心应用数据,也就是data中的部分,一致性都通过同步wal日志来实现,每个节点将从主节点收到的data apply到本地的存储,Raft只关心日志的同步状态,如果本地存储实现的有bug,比如没有正确的将data apply到本地,也可能会导致数据不一致。
4、存储机制
etcd v3 store 分为两部分,一部分是内存中的索引,kvindex,是基于Google开源的一个Golang的btree实现的,另外一部分是后端存储。按照它的设计,backend可以对接多种存储,当前使用的boltdb。boltdb是一个单机的支持事务的kv存储,etcd 的事务是基于boltdb的事务实现的。etcd 在boltdb中存储的key是reversion,value是 etcd 自己的key-value组合,也就是说 etcd 会在boltdb中把每个版本都保存下,从而实现了多版本机制。
reversion主要由两部分组成,第一部分main rev,每次事务进行加一,第二部分sub rev,同一个事务中的每次操作加一。
etcd 提供了命令和设置选项来控制compact,同时支持put操作的参数来精确控制某个key的历史版本数。
内存kvindex保存的就是key和reversion之前的映射关系,用来加速查询。
5、Watch机制
etcd v3 的watch机制支持watch某个固定的key,也支持watch一个范围(可以用于模拟目录的结构的watch),所以 watchGroup 包含两种watcher,一种是 key watchers,数据结构是每
个key对应一组watcher,另外一种是 range watchers, 数据结构是一个 IntervalTree,方便通过区间查找到对应的watcher。
同时,每个 WatchableStore 包含两种 watcherGroup,一种是synced,一种是unsynced,前者表示该group的watcher数据都已经同步完毕,在等待新的变更,后者表示该group的
watcher数据同步落后于当前最新变更,还在追赶。
当 etcd 收到客户端的watch请求,如果请求携带了revision参数,则比较请求的revision和store当前的revision,如果大于当前revision,则放入synced组中,否则放入unsynced组。同时 etcd 会启动一个后台的goroutine持续同步unsynced的watcher,然后将其迁移到synced组。也就是这种机制下,etcd v3 支持从任意版本开始watch,没有v2的1000条历史event表限制的问题(当然这是指没有compact的情况下)
三、Controller Manager
1、工作负载型控制器:
1)Pod是运行应用的原子单元,其生命周期管理和健康状态监测由kubelet负责完成,而诸如更新、扩缩容和重建等应用编排功能需要由专用的控制器实现
ReplicaSet和Deployment
DaemonSet
StatefulSet
Job和CronJob
2)工作负载型控制器也通过标签选择器筛选Pod标签从而完成关联
3)工作负载型控制器的工作重心
a、确保选定的Pod精确符合期望的数量
数量不足时依据Pod模板创建,超出时销毁多余的对象
b、按配置定义进行扩容和缩容
c、依照策略和配置进行应用更新
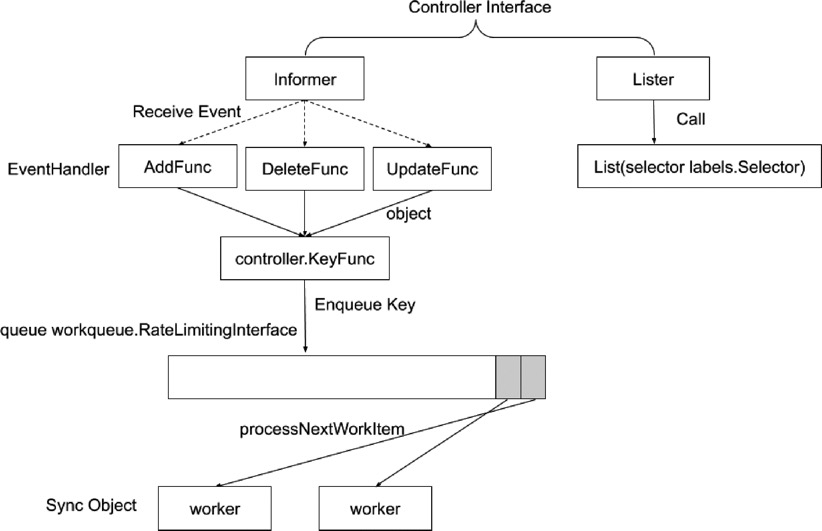
2、Controller Manager作用
1)Controller Manager 是集群的大脑,是确保整个集群动起来的关键;
2)作用是确保 Kubernetes 遵循声明式系统规范,确保系统的真实状态(ActualState)与用户定义的期望状态(Desired State)一致;
3)Controller Manager 是多个控制器的组合,每个 Controller 事实上都是一个control loop,负责侦听其管控的对象,当对象发生变更时完成配置;
4)Controller 配置失败通常会触发自动重试,整个集群会在控制器不断重试的机制下确保最终一致性( Eventual Consistency)。
工作流程:
四、Scheduler
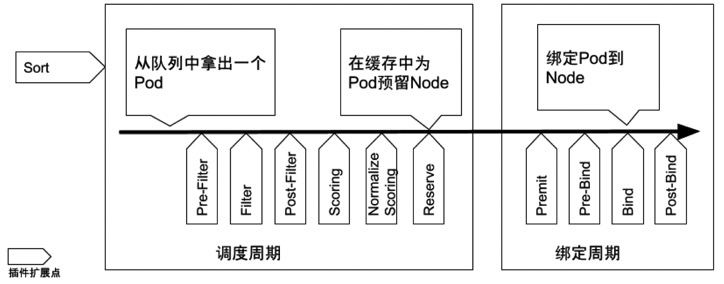
特殊的 Controller,工作原理与其他控制器无差别。Scheduler 的特殊职责在于监控当前集群所有未调度的 Pod,并且获取当前集群所有节点的健康状况和资源使用情况,为待调度 Pod 选择最佳计算节点,完成调度。
调度阶段分为:
Predict:过滤不能满足业务需求的节点,如资源不足、端口冲突等。
Priority:按既定要素将满足调度需求的节点评分,选择最佳节点。
Bind:将计算节点与 Pod 绑定,完成调度。
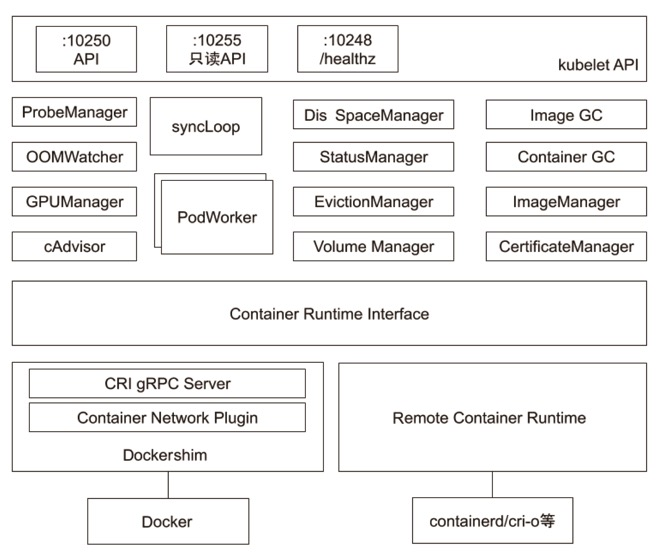
五、Kubelet
Kubernetes 的初始化系统(init system)
1、从不同源获取 Pod 清单,并按需求启停 Pod 的核心组件:
Pod 清单可从本地文件目录,给定的 HTTPServer 或 Kube-APIServer 等源头获取;
Kubelet 将运行时,网络和存储抽象成了 CRI,CNI,CSI。
2、负责汇报当前节点的资源信息和健康状态;
3、负责 Pod 的健康检查和状态汇报。
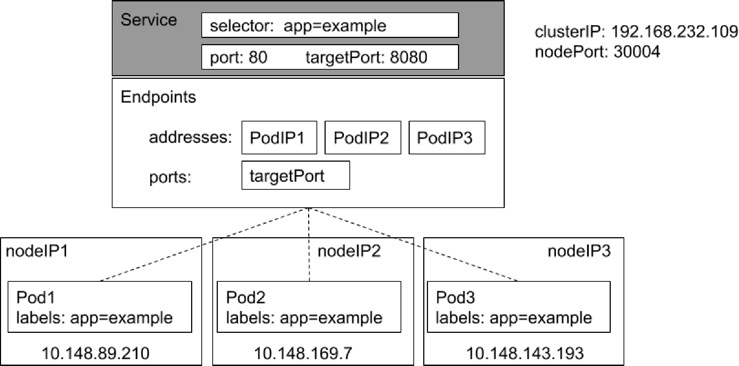
六、Kube-Proxy
1、监控集群中用户发布的服务,并完成负载均衡配置。
2、每个节点的 Kube-Proxy 都会配置相同的负载均衡策略,使得整个集群的服务发现建立在分布式负载均衡器之上,服务调用无需经过额外的网络跳转(Network Hop)。
3、 负载均衡配置基于不同插件实现:
• userspace。
• 操作系统网络协议栈不同的 Hooks 点和插件:
• iptables;
• ipvs。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?