--config.file="prometheus.yml" #指定配置文件
--web.listen-address="0.0.0.0:9090" #指定监听地址
--storage.tsdb.path="data/" #指定数存储目录
--storage.tsdb.retention.size=B, KB, MB, GB, TB, PB, EB #指定block大小,默认512MB
--storage.tsdb.retention.time= #数据保存时长,默认15天
--query.timeout=2m #最大查询超时时间
-query.max-concurrency=20 #最大查询并发数
--web.read-timeout=5m #最大空闲超时时间
--web.max-connections=512 #最大并发连接数
--web.enable-lifecycle #启用API动态加载配置功能
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
After=network.target
[Service]
Restart=on-failure
WorkingDirectory=/apps/prometheus/
ExecStart=/apps1/prometheus/prometheus --config.file=/apps1/prometheus/prometheus.yml --web.enable-lifecycle
[Install]
WantedBy=multi-user.target
#执行以下命令
systemctl daemon-reload
systemctl start prometheus.service
systemctl enable prometheus.service

部署node_exporter(虚拟机、物理机上)
二进制部署node_exporter:
mkdir /apps
cd /apps
tar xvf node_exporter-1.5.0.linux-amd64.tar.gz
ln -sv /apps/node_exporter-1.5.0.linux-amd64 /apps/node_exporter
ll /apps/node_exporter/
vim /etc/systemd/system/node-exporter.service
[Unit]
Description=Prometheus Node Exporter
After=network.target
[Service]
ExecStart=/apps/node_exporter/node_exporter
[Install]
WantedBy=multi-user.target
systemctl daemon-reload && systemctl restart node-exporter && systemctl enable node-exporter.service
prometheus数据简介:
metric: 指标,有各自的metric name, 是一个key value(键值)格式组成的某个监控项数据。
node_load1 0.21
labels:标签,用于对相同名称的指标进行删选,一个指标可以同时有多个不同的标签。
node_network_receive_packets_total{device="eth0"} 109464
node_network_receive_packets_total{device="lo"} 178
samples:样本,存在于TSDB中的数据,有三部分组成:
指标(包含metric name和labels) 值(value, 指标数据) 时间戳(指标写入的时间)
series:序列,有多个samples组成的时间序列数据
node节点指标数据收集
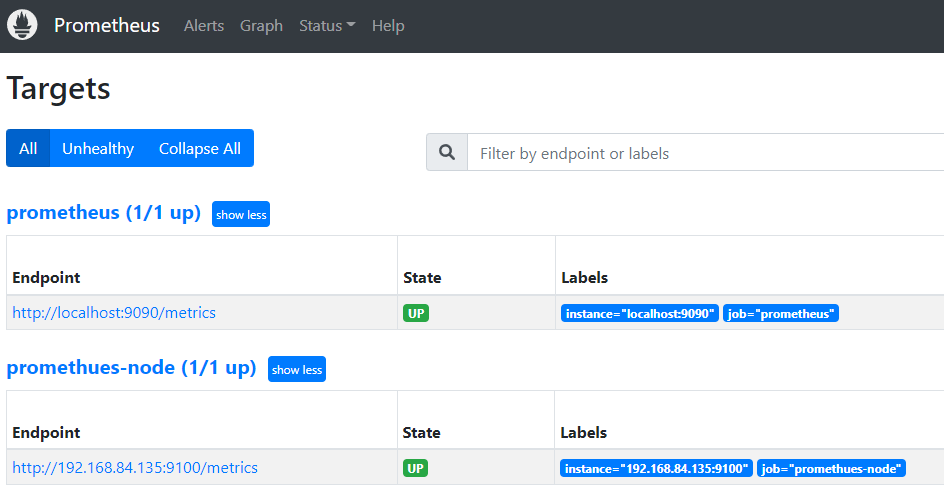
配置prometheus server收集node-exporter指标数据:
vim /apps1/prometheus/prometheus.yml
- job_name: 'promethues-node'
static_configs:
- targets: ["192.168.84.135:9100"]
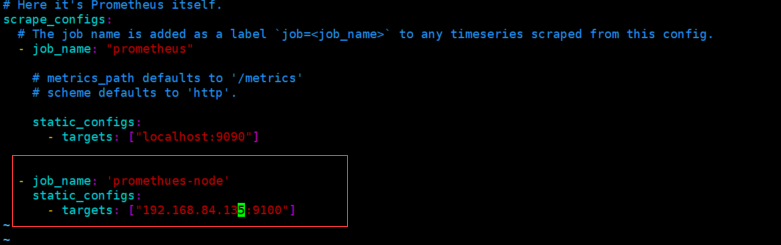
systemctl restart prometheus.service
node节点常见指标:
node_boot_time:系统自启动以后的总结时间
node_cpu:系统CPU使用量
node_disk*:磁盘IO
node_filesystem*:系统文件系统用量
node_load1:系统CPU负载
node_memory*:内存使用量
node_network*:网络带宽指标
node_time:当前系统时间
go_*:node exporter中go相关指标
process_*:node exporter自身进程相关运行指标
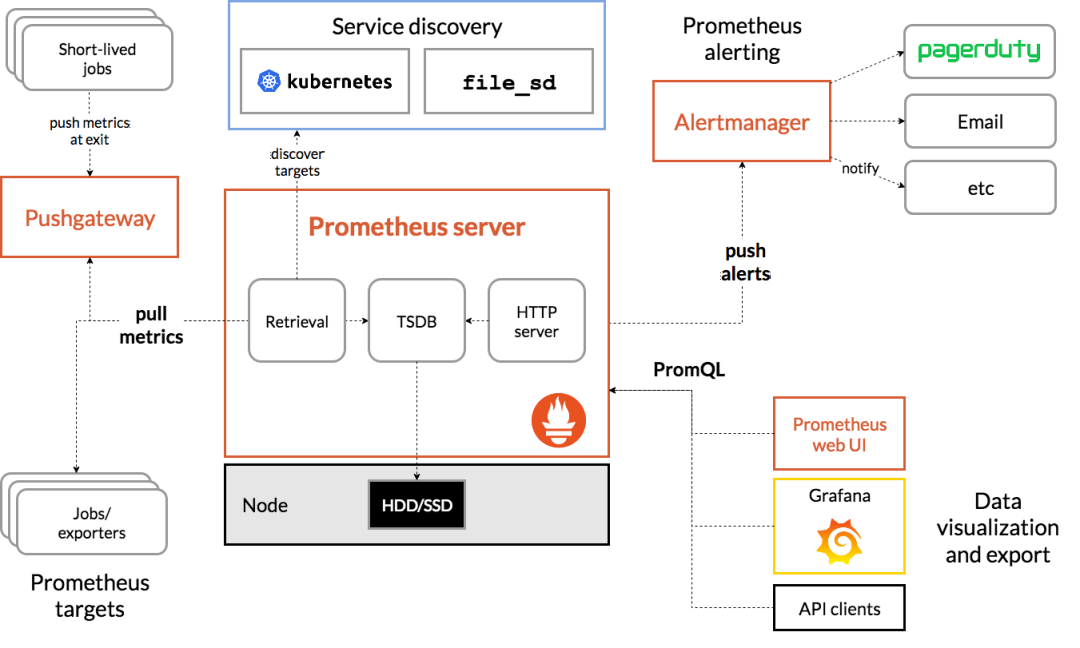
grafana 部署及使用
grafana简介
(1)grafana是一个可视化组件,用于接收客户端浏览器的请求并连接到prometheus查询数据,最后经过渲染并在浏览器进行体系化显示,需要注意的是,grafana查询数据类似于zabbix一样需要自定义模板,模板可以手动制作也可以导入已有模板。
(2)https://grafana.com/ #官网
(3)https://grafana.com/grafana/dashboards/ #模板下载
grafana安装:
(1)下载地址:https://grafana.com/grafana/download?pg=get&plcmt=selfmanaged-box1-cta1
(2)下载相关依赖:sudo apt-get install -y adduser libfontconfig1
(4)开始安装:dpkg -i grafana-enterprise_9.3.1_amd64.deb
(5)vim /etc/grafana/grafana.ini
[server]
# Protocol (http, https, h2, socket)
protocol = http
# The ip address to bind to, empty will bind to all interfaces
http_addr = 0.0.0.0
# The http port to use
http_port = 3000
(6)systemctl restart grafana-server && systemctl enable grafana-server
(7)登录grafana web界面:
默认账户:admin
默认密码:admin
grafana 的使用:
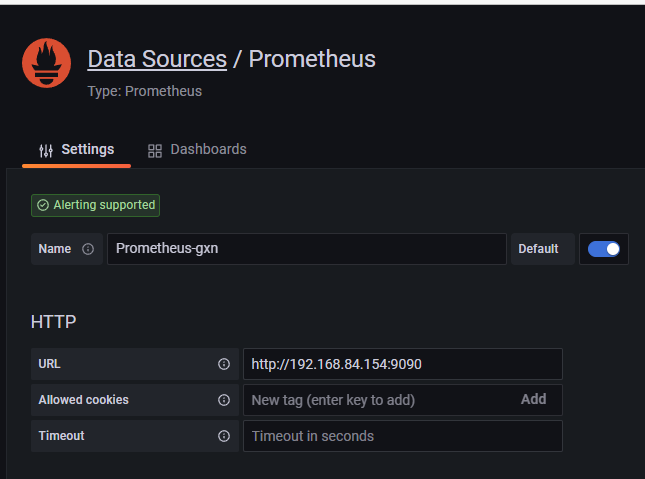
(1)添加数据源:Configuration-->data source-->add datasource-->prometheus
(2)导入模板:https://grafana.com/grafana/dashboards
Dashboards-->import-->模板id 11074/8919
PromQL 语句的简单使用
Prometheus提供一个函数式的表达式语言PromQL (Prometheus Query Language),可以使用户实时地查找和聚合时间序列数据,表达式计算结果可以在图表中展示,也可以在Prometheus表达式浏览器中以表格形式展示,或者作为数据源, 以HTTP API的方式提供给外部系统使用。
https://prometheus.io/docs/prometheus/latest/querying/basics
PromQL查询数据类型:
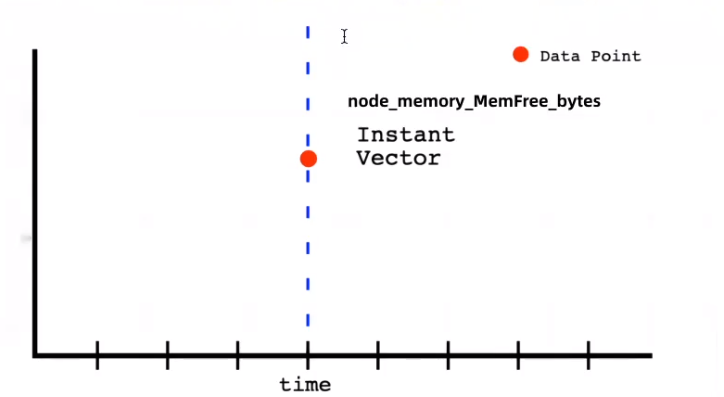
(1)Instant Vector:瞬时向量/瞬时数据,是对目标实例查询到的同一个时间戳的一组时间序列数据(按照时间的推移对数据进存储和展示),每个时间序列包含单个数据样本,比如node_memory_MemFree_bytes查询的是当前剩余内存(可用内存)就是一个瞬时向量,该表达式的返回值中只会包含该时间序列中的最新的一个样本值,而相应的这样的表达式称之为瞬时向量表达式,以下是查询node节点可用内存的瞬时向量表达式。
命令: curl 'http://192.168.84.154:9090/api/v1/query' --data 'query=node_memory_MemFree_bytes' --data time=时间戳
结果:{"status":"success","data":{"resultType":"vector","result":[{"metric":{"__name__":"node_memory_MemFree_bytes","instance":"192.168.84.135:9100","job":"promethues-node"},"value":[1670833382.876,"3130011648"]}]}}
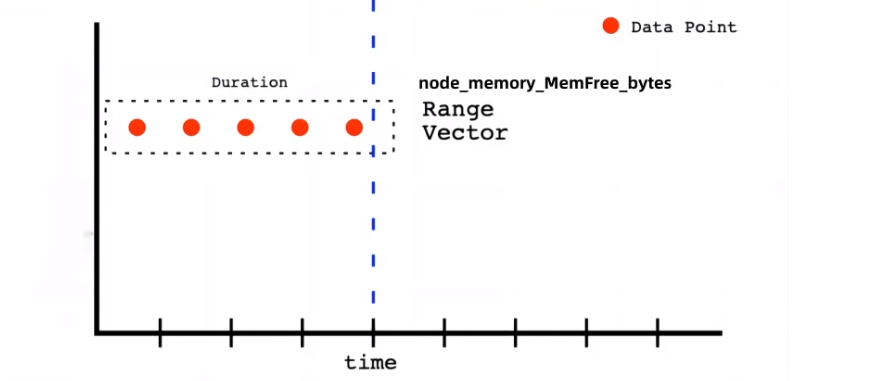
(2)Range Vector:范围向量/范围数据,是指在任何一个时间范围内,抓取的所有度量指标数据.比如最近一天的网卡流量趋势图、或最近5分钟的node节点内容可用字节数等,以下是查询node节点可用内存的范围向量表达式:
命令:curl 'http://192.168.84.154:9090/api/v1/query' --data 'query=node_memory_MemFree_bytes{instance="192.168.84.135:9100"}[5m]'
结果:{"status":"success","data":{"resultType":"matrix","result":[{"metric":{"__name__":"node_memory_MemFree_bytes","instance":"192.168.84.135:9100","job":"promethues-node"},"values":[[1670833503.334,"3130011648"],[1670833518.333,"3130011648"], [1670833533.333,"3130011648"],[1670833548.333,"3130011648"],[1670833563.333,"3130011648"],[1670833578.334,"3130011648"],[1670833593.333,"3130011648"],[1670833608.333,"3130011648"],[1670833623.334,"3130011648"], [1670833638.333,"3130011648"],[1670833653.334,"3130011648"],[1670833668.334,"3130011648"],[1670833683.333,"3130011648"],[1670833698.333,"3130011648"],[1670833713.333,"3130011648"],[1670833728.333,"3130011648"],[1670833743.333,"3130011648"],[1670833758.334,"3130011648"],[1670833773.333,"3130011648"],[1670833788.333,"3130011648"]]}]
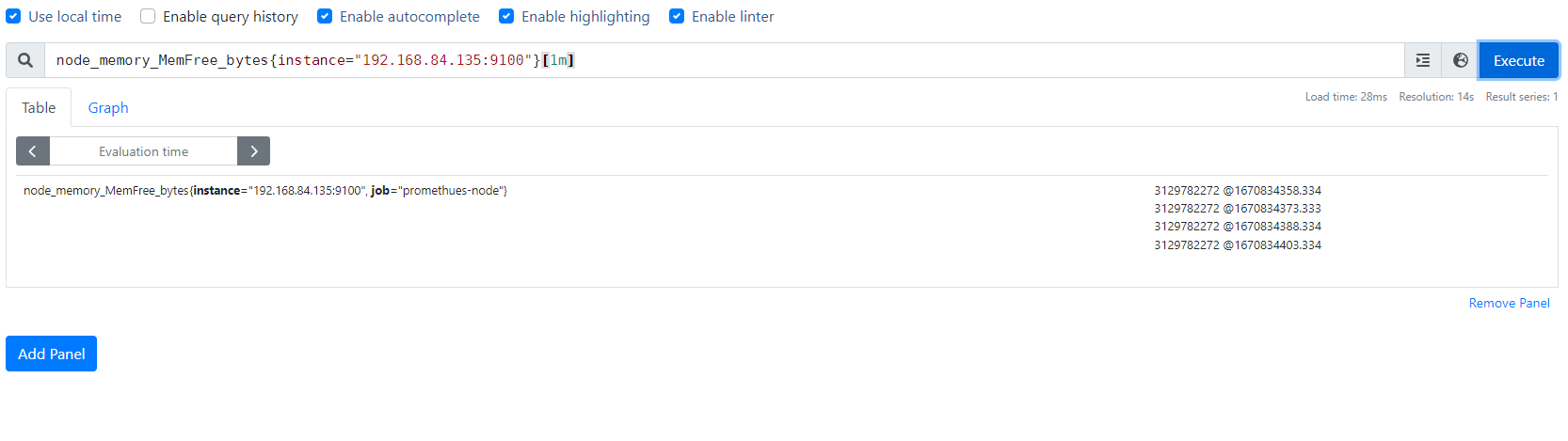
(3)scalar:标量/纯量数据,是一个浮点数类型的数据值,使用node_load1获取到时一个瞬时向量后,在使用prometheus的内置函数scalar()将瞬时向量转换为标量,例如:scalar(sum(node_load1))
命令:curl 'http://192.168.84.154:9090/api/v1/query' --data' query=scalar(sum(node_load1{instance="192.168.84.135:9100"}))'
(4)string:简单的字符串类型的数据,目前未使用,(a simple string value; currently unused)
https://prometheus.io/docs/prometheus/latest/querying/basics
prometheus指标数据类型:
Counter:计数器
Gauge:仪表盘
Histogram:累积直方图
Summary:摘要
(1)Counter:计数器,Counter类型代表一个累积的指标数据,在没有被重启的前提下只增不减(生活中的电表、水表),比如磁盘I/O总数、Nginx/API的请求总数、网卡流经的报文总数等。
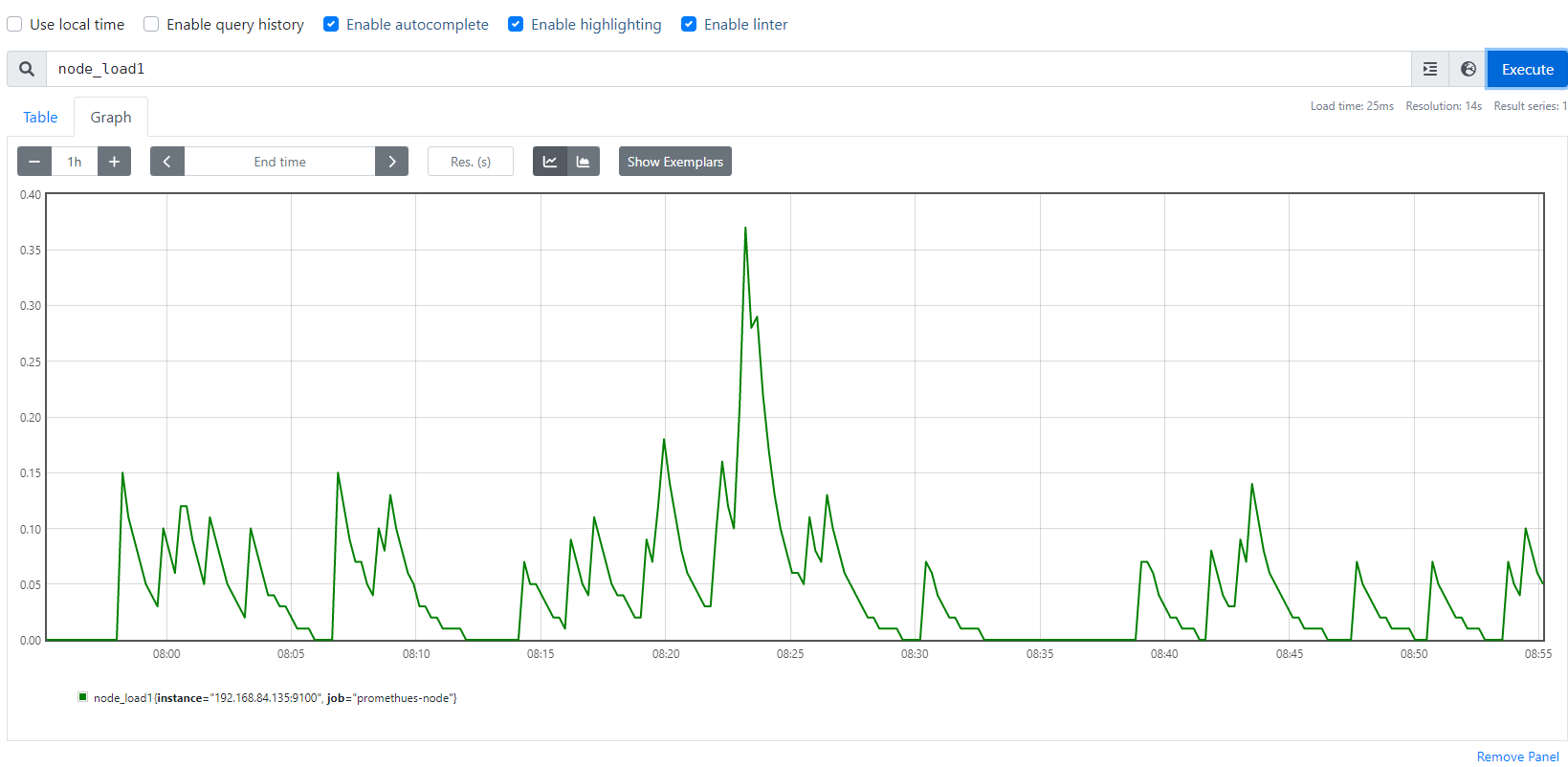
(2)Gauge:仪表盘,Gauge类型代表一个可以任意变化的指标数据,值可以随时增高或减少,如带宽速率、CPU负载、内存利用率、nginx 活动连接数等。
(3)Histogram:累积直方图,Histogram会在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),假如每分钟产生一个当前的活跃连接数,那么一天24小时*60分钟=1440分钟就会产生1440个数据,查看数据的每间隔的绘图跨度为2小时,那么2点的柱状图(bucket)会包含0点到2点即两个小时的数据,而4点的柱状图(bucket)则会包含0点到4点的数据,而6点的柱状图(bucket)则会包含0点到6点的数据,可用于统计从当天零点开始到当前时间的数据统计结果,如http请求成功率、丢包率等,比如ELK的当天访问IP计。
(4)Summary:摘要图,也是一组数据,默认统计选中的指标的最近10分钟内的数据的分位数,可以指定数据统计时间范围,基于分位数(Quantile),亦称分位点,是指用分割点(cut point)将随机数据统计并划分为几个具有相同概率的连续区间,常见的为四分位,四分位数是将数据样本统计后分成四个区间,将范围内的数据进行百分比的占比统计,从0到1,表示是0%~100%,(0%~25%,%25~50%,50%~75%,75%~100%),利用四分位数,可以快速了解数据的大概统计结果。
如下统计的是 0、0.25、0.5、0.75、1的数据量分别是多少。
go_gc_duration_seconds
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 1.8479e-05
go_gc_duration_seconds{quantile="0.25"} 6.5059e-05 #25%以内的go_gc_duration_seconds的持续时间
go_gc_duration_seconds{quantile="0.5"} 9.3605e-05 #50%以内的go_gc_duration_seconds的持续时间
go_gc_duration_seconds{quantile="0.75"} 0.000133103 #75%以内的go_gc_duration_seconds的持续时间
go_gc_duration_seconds{quantile="1"} 0.004022673 #100%以内的go_gc_duration_seconds的持续时间
go_gc_duration_seconds_sum 1.446781088 #数据总和
go_gc_duration_seconds_count 7830 #数据个数
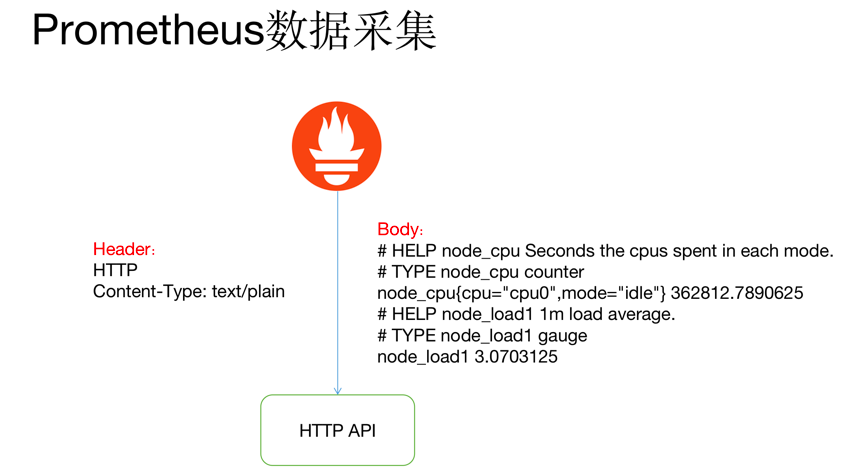
node-exporter指标数据格式:
#没有标签的
#metric_name metric_value
# TYPE node_load15 gauge
node_load15 0.1
#一个标签的
#metric_name{label1_name="label1-value"} metric_value
# TYPE node_network_receive_bytes_total counter
node_network_receive_bytes_total{device="eth0"} 1.44096e+07
#多个标签的
#metric_name{label1_name="label1-value","labelN_name="labelN-value} metric_value
# TYPE node_filesystem_files_free gauge
node_filesystem_files_free{device="/dev/sda2",fstype="xfs",mountpoint="/boot"} 523984
PromQL查询指标数据示例:
node_memory_MemTotal_bytes #查询node节点总内存大小
node_memory_MemFree_bytes #查询node节点剩余可用内存
node_memory_MemTotal_bytes{instance="192.168.84.135:9100"} #基于标签查询指定节点的总内存
node_memory_MemFree_bytes{instance="192.168.84.135:9100"} #基于标签查询指定节点的可用内存
node_disk_io_time_seconds_total{device="sda"} #查询指定磁盘的每秒磁盘io
node_filesystem_free_bytes{device="/dev/sda1",fstype="xfs",mountpoint="/"} #查看指定磁盘的磁盘剩余空间
# HELP node_load1 1m load average. #CPU负载
# TYPE node_load1 gauge
node_load1 0.1
# HELP node_load15 15m load average.
# TYPE node_load15 gauge
node_load15 0.17
# HELP node_load5 5m load average.
# TYPE node_load5 gauge
node_load5 0.13
PromQL标签匹配:
基于标签对指标数据进行匹配:
= :选择与提供的字符串完全相同的标签,精确匹配。
!= :选择与提供的字符串不相同的标签,去反。
=~ :选择正则表达式与提供的字符串(或子字符串)相匹配的标签。
!~ :选择正则表达式与提供的字符串(或子字符串)不匹配的标签。
#查询格式<metric name>{<label name>=<label value>, ...}
node_load1{instance="192.168.84.135:9100"}
node_load1{job="promethues-node"}
node_load1{job="promethues-node",instance="192.168.84.135:9100"} #精确匹配
node_load1{job="promethues-node",instance!="192.168.84.135:9100"} #取反
node_load1{instance=~"192.168.84.135.*:9100$"} #包含正则且匹配
node_load1{instance!~"192.168.84.135:9100"} #包含正则且取反
PromQL 时间范围:
对指标数据进行时间范围指定:
s - 秒
m - 分钟
h - 小时
d - 天
w - 周
y - 年
#瞬时向量表达式,选择当前最新的数据
node_memory_MemTotal_bytes{}
#区间向量表达式,选择以当前时间为基准,查询所有节点
node_memory_MemTotal_bytes指标5分钟内的数据
node_memory_MemTotal_bytes{}[5m]
#区间向量表达式,选择以当前时间为基准,查询指定节点
node_memory_MemTotal_bytes指标5分钟内的数据
node_memory_MemTotal_bytes{instance="192.168.84.135:9100"}[5m]
PromQL 运算符:
对指标数据进行数学运算:
+ 加法
- 减法
* 乘法
/ 除法
% 模
^ 幂(N次方)
node_memory_MemFree_bytes/1024/1024 #将内存进行单位从字节转行为兆
node_disk_read_bytes_total{device="sda"} + node_disk_written_bytes_total{device="sda"} #计算磁盘读写数据量
(node_disk_read_bytes_total{device="sda"} + node_disk_written_bytes_total{device="sda"}) / 1024 / 1024 #单位转换
PromQL 聚合运算:
对指标数据进行进行聚合运算:
max() #最大值
min() #最小值
avg() #平均值
计算每个节点的最大的流量值:
max(node_network_receive_bytes_total) by (instance)
计算每个节点最近五分钟每个device的最大流量
max(rate(node_network_receive_bytes_total[5m])) by (device)
sum() #求数据值相加的和(总数)
sum(prometheus_http_requests_total)
{} 2495 #最近总共请求数为2495次,用于计算返回值的总数(如http请求次数)
count() #统计返回值的条数
count(node_os_version)
{} 2 #一共两条返回的数据,可以用于统计节点数、pod数量等
abs() #返回指标数据的值
abs(sum(prometheus_http_requests_total{handler="/metrics"}))
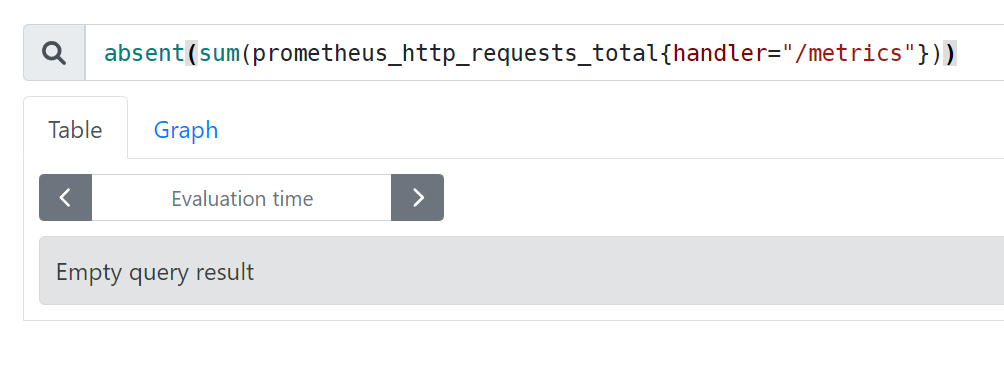
absent() #如果监指标有数据就返回空,如果监控项没有数据就返回1,可用于对监控项设置告警通知(如果返回值等于1就触发告警通知)
absent(sum(prometheus_http_requests_total{handler="/metrics"}))
stddev() #标准差
stddev(prometheus_http_requests_total) #5+5=10,1+9=10,1+9这一组的数据差异就大,在系统是数据波动较大,不稳定
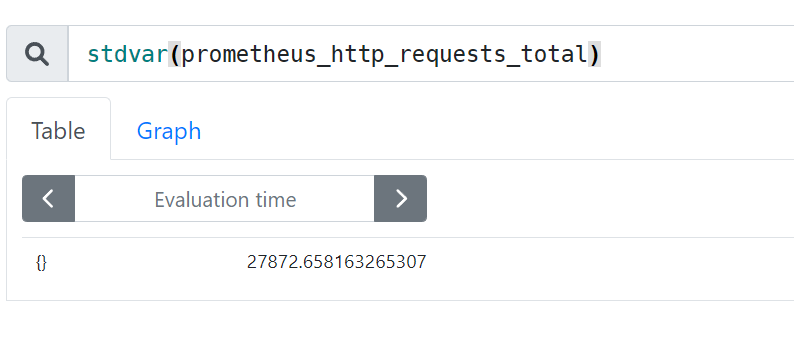
stdvar() #求方差
stdvar(prometheus_http_requests_total)
topk() #样本值排名最大的N个数据
#取从大到小的前6个
topk(6, prometheus_http_requests_total)
bottomk() #样本值排名最小的N个数据
#取从小到大的前6个
bottomk(6, prometheus_http_requests_total)
rate() #rate函数是专门搭配counter数据类型使用函数,rate会取指定时间范围内所有数据点,算出一组速率,然后取平均值作为结果,适合用于计算数据相对平稳的数据。
rate(prometheus_http_requests_total[5m])
rate(apiserver_request_total{code=~"^(?:2..)$"}[5m])
rate(node_network_receive_bytes_total[5m])
irate() #函数也是专门搭配counter数据类型使用函数,irate取的是在指定时间范围内的最近两个数据点来算速率,适合计算数据变化比较大的数据,显示的数据相对比较准确,所以官网文档说:irate适合快速变化的计数器(counter),而rate适合缓慢变化的计数器(counter)。
irate(prometheus_http_requests_total[5m])
irate(node_network_receive_bytes_total[5m])
irate(apiserver_request_total{code=~"^(?:2..)$"}[5m])
#by,在计算结果中,只保留by指定的标签的值,并移除其它所有的
sum(rate(node_network_receive_packets_total{instance=~".*"}[10m])) by (instance)
sum(rate(node_memory_MemFree_bytes[5m])) by (increase)
#without,从计算结果中移除列举的instance,job标签,保留其它标签
sum(prometheus_http_requests_total) without (instance,job)
部署prometheus serve
环境准备:三台部署prometheus(一台主server和两台联邦server)、两台部署node_exporter
配置prometheus联邦节点收集node-exporter指标数据:
联邦节点1-192.168.84.136:
/apps/prometheus# vim prometheus.yml
- job_name: "prometheus-idc1"
static_configs:
- targets: ["192.168.84.137:9100"]
/apps/prometheus# vim prometheus.yml
- job_name: "prometheus-idc2"
static_configs:
- targets: ["192.168.84.153:9100"]
systemctl restart prometheus.service
验证prometheus targets状态:
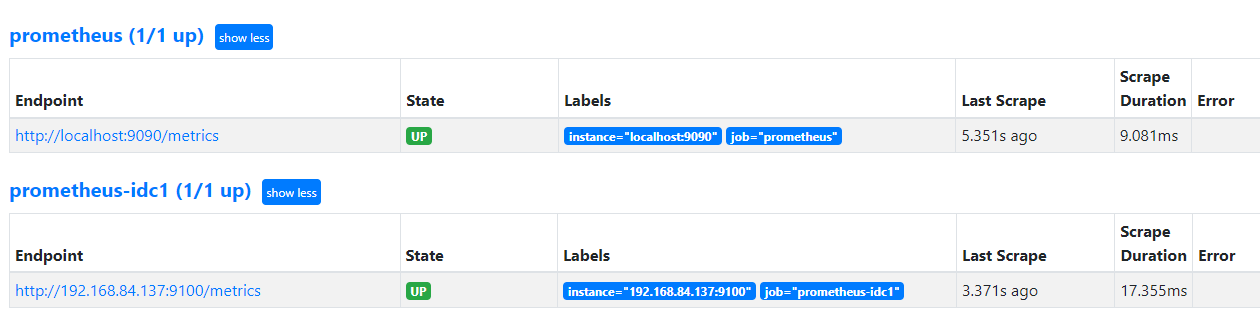
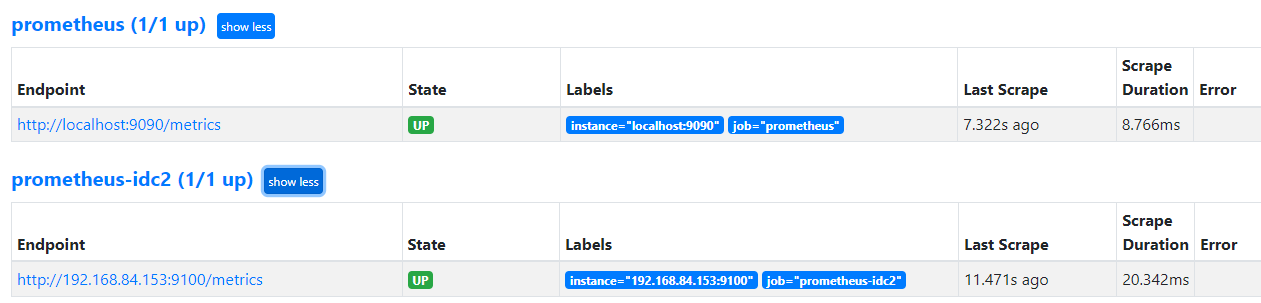
配置prometheus 通过联邦节点收集的node-exporter指标数据:
# vim /apps/prometheus/prometheus.yml
- job_name: 'prometheus-federate-1.136'
scrape_interval: 10s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
- '{__name__=~"node.*"}'
static_configs:
- targets:
- '192.168.84.136:9090'
- job_name: 'prometheus-federate-2.135'
scrape_interval: 10s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
- '{__name__=~"node.*"}'
static_configs:
- targets:
- '192.168.84.135:9090'
验证prometheus 通过联邦节点收集的node-exporter指标数据:
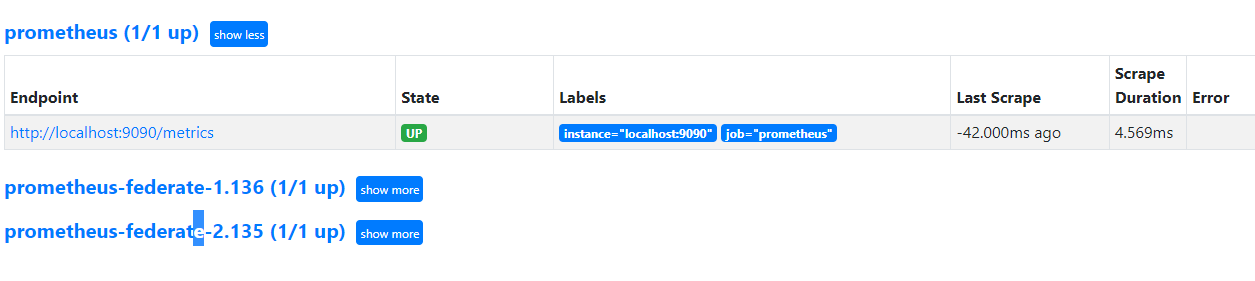
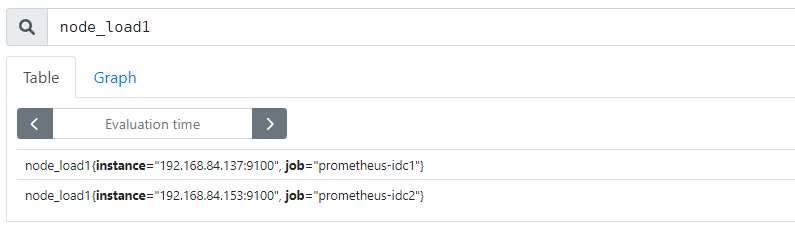
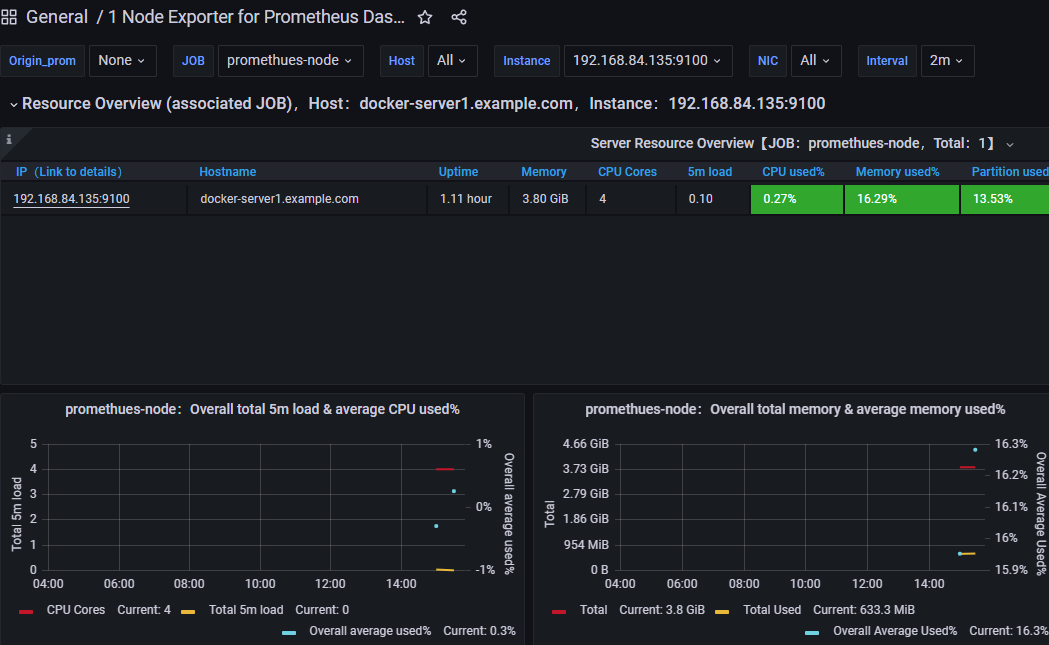
grafana 验证数据:





 浙公网安备 33010602011771号
浙公网安备 33010602011771号