
2020软件工程第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | <学习 git 使用,json 文本在 Python 中的处理方法,GitHub fork 仓库和 PullRequest,用 coverage 测试代码覆盖率和优化代码> |
| 学号 | <031802515> |
PSP 表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 30 | 20 |
| Analysis | 需求分析 (包括学习新技术) | 50 | 30 |
| Design Spec | 生成设计文档 | 10 | 5 |
| Design Review | 设计复审 | 10 | 10 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 15 | 15 |
| Design | 具体设计 | 30 | 30 |
| Coding | 具体编码 | 250 | 200 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 240 | 200 |
| Reporting | 报告 | 60 | 60 |
| Test Report | 测试报告 | 20 | 20 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 90 |
| 合计 | 755 | 660 |
解题思路
拿到题目后,我先下载了数据,发现看不懂。又去看了需要统计的内容,发现真的不知道题目要干什么的。于是万般不好意思下去问了大佬,大佬说让我先去学习 json 这个数据格式。于是我在 b 站上听了几节讲 json 的课,发现它就是一个记录数据的格式,用 python 写得话处理它比较方便,就打算用 python 来写。
我终于弄懂了题目的意思,就是在 GH Archive 的 json 文档中统计同一条信息中个人的 4 种事件的数量,每一个项目的 4 种事件的数量或者每一个人在每一个项目的 4 种事件的数量。之后我看到作业要求用 git 提交代码到 GitHub 并且学会用 .gitignore 指令忽略一些文件,所以我去 b 站听了助教老师的 git 教程,下载和配置了 git 。
看过老师的代码格式要求后开始打代码,代码的功能大体分为三部分,第一部分是读取文件夹里的 json 文件,第二部分是在 json 文件里查找特定数据,第三部分是对查找目标的计数。
设计实现过程
问题剖析:
首先要获得用户命令行参数,并且利用命令行参数进行数据查找。
实现过程:
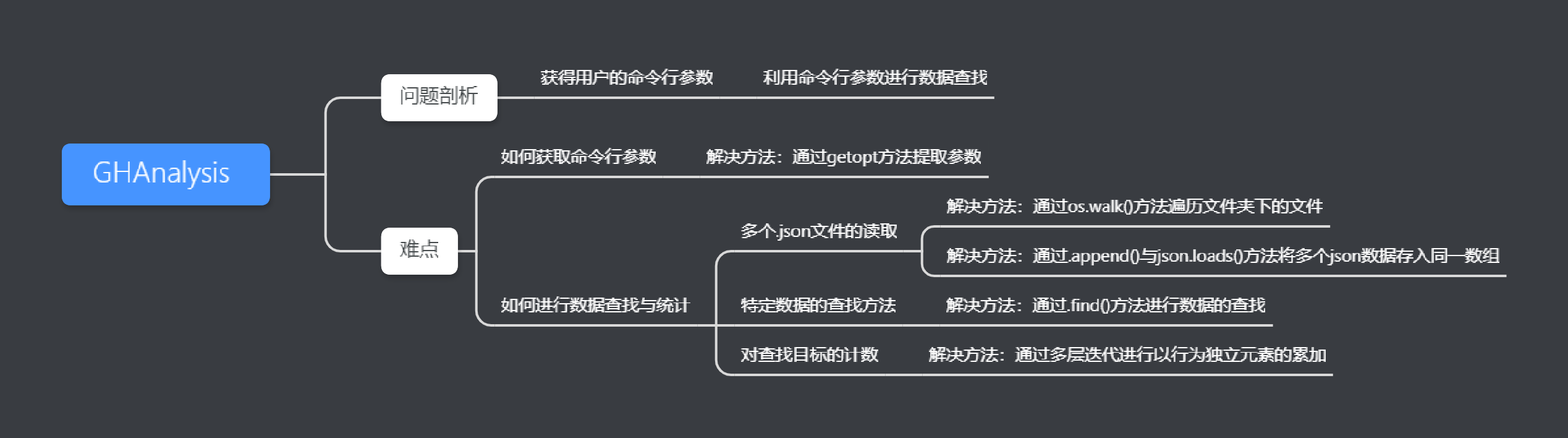
获取命令参数时通过 getopt 方法提取参数
进行数据查找与统计,多个 .json 文件读取需要用到 os.walk() 方法遍历文件夹下的文件,并且通过 .append() 与 json.loads() 方法将多个 json 数据存入同一数组。
特定数据的查找方法是通过 .find() 方法进行数据的查找。
查找目标的计数通过多层迭代进行以行为独立元素的累加。
关键函数流程图
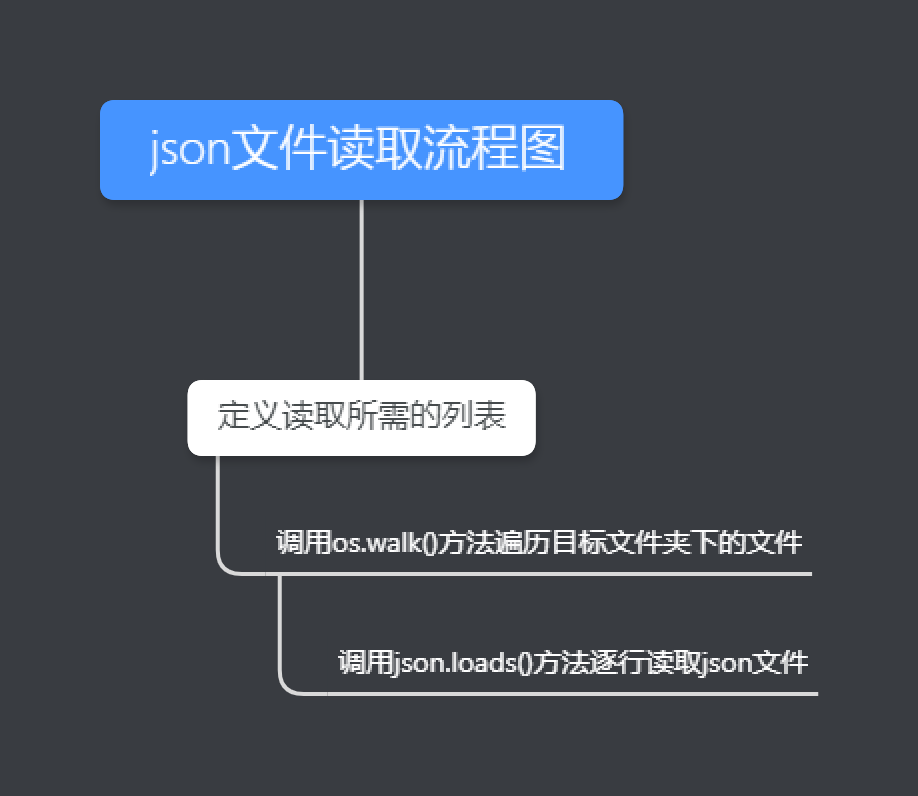
关键代码
json解析
def read(path):
global data
data = []
path_all = []
for root, dirs, files in os.walk(path):
for file in files:
path_all.append(os.path.join(root, file))
for i in range(0,len(path_all)):
with open(path_all[i],'r',encoding='utf8')as f:
for line in f:
data.append(json.loads(line))
命令行参数设置
opt,arv= getopt.getopt(sys.argv[1:],'i:u:r:e:',['user=','repo=','event=','init='])
遍历查找参数
def get_cmd():
global path,user,repo,event,judger,length
path,user,repo,event = 'djista','djista','djista','djista'
opt,arv= getopt.getopt(sys.argv[1:],'i:u:r:e:',['user=','repo=','event=','init='])
if len(opt):
length = len(opt)
for i in range(0,len(opt)):
if opt[i][0] == '-i':
path = opt[i][1]
elif opt[i][0] == '-u':
user = opt[i][1]
judger = 1
elif opt[i][0] == '-r':
repo = opt[i][1]
judger = 2
elif opt[i][0] == '-e':
event = opt[i][1]
else:
break
else:
print('Input command error')
统计计算结果
def find_data():
result = 0
#每一行数据分别存储在了对应的data[]列表中
#查找用户
for i in range(0,len(data)):
data_str = str(data[i])
if judger == 1:
if data_str.find(user) != -1:
if data_str.find(event) != -1:
result = result + 1
if judger == 2:
if length == 3:
if data_str.find(repo) != -1:
if data_str.find(event) != -1:
result = result + 1
else:
if data_str.find(repo) != -1:
if data_str.find(event) != -1:
if data_str.find(user)!= -1:
result = result + 1
print(result)
单元测试截图和解释
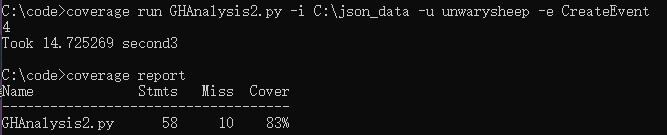
解析 24.9 Mb json 文件花费 0.68 s
此参数单元测试覆盖率 79%
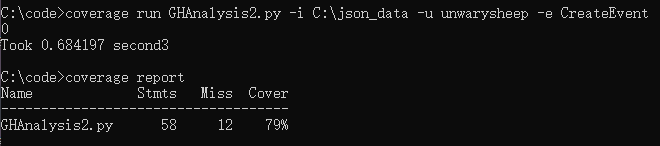
解析 998 Mb json 文件花费 14.75 s
此参数单元测试覆盖率 83%
我的程序执行结果

单元测试优化
因为运行速度较慢,所以打算写成多线程来优化代码,但是因为太菜了,写成多线程反而更慢了。
关键多线程代码
if __name__ == '__main__':
sum =[]
start_time = time.time()
get_cmd()
read_1(path)
t1 = threading.Thread(target=ooopen,args=(0,2))
t2 = threading.Thread(target=ooopen,args=(2,4))
t3 = threading.Thread(target=ooopen,args=(4,6))
t4 = threading.Thread(target=ooopen,args=(6,count))
#t3 = threading.Thread(target=find_data)
t1.start()
t2.start()
t3.start()
t4.start()
t4.join()
print(sum[0]+sum[1]+sum[2]+sum[3])
end_time = time.time() # 记录程序结束运行时间
print('Took %f second3' % (end_time - start_time))
我的代码规范连接
作业小结
- 拿到题目后因为看不懂就以为完全不会做,所以托了很多天,浪费了很多时间。
- 刚学习 json 的时候不知道怎么下手,就先看了很多 CSDN 和博客园的文章,其实对于完全没有接触过的知识直接去听课会理解的快很多。
- 刚开始对 Python 不熟悉,很多方法都要去查了之后才知道怎么用,算法方面问了很多大佬。所以还是要再熟悉 Python 才行。
- 学会了运用 coverage 测试 Python 代码覆盖率。
通过这次作业学会了很多,希望能再进一步提高自己解决问题的能力和代码熟练度。
