redis知识汇总
1. 什么是redis,redis有哪些特点
Redis 是基于内存的键值型(key - value)的 NoSQL 数据库(⾮关系型数据库)。key ⼀般是 String 类型,⽽ value ⽀持丰富的数据类型,包括String、Hash、List、Set、SortedSet 这五种基本类型,此外还有 GEO、BitMap、HyperLogLog 等其他类型。
Redis的特点包括:
- 读写性能优异
- 基于内存,内存的访问速度是⽐磁盘快很多的
- 采⽤单线程模型,不存在多线程的上下⽂切换,不需要考虑锁的问题
- 使⽤ IO 多路复⽤模型,让 Redis 不需要创建额外的线程来监听客户端的⼤量请求,减少性能的消耗
- 内置了多种优化过的数据结构实现,Redis ⽀持多种数据结构,包括字符串、哈希、列表、集合、有序集合等。
- 支持事务
- 允许多个命令按顺序执⾏并不会被打断
- 不⽀持回滚
- 持久化:Redis ⽀持多种持久化⽅式,包括 RDB 快照和 AOF ⽇志。
- RDB:通过创建快照来获得存储在内存⾥⾯的数据在某个时间点上的副本
- AOF:执⾏完更改数据的命令后,会将该命令记录到⽇志中
- 分布式:Redis ⽀持分布式部署,可以将数据分布在多个节点上。
- 所有操作命令都是原⼦性。
2. redis 有哪些常⻅的应⽤场景?
- 数据缓存
- 将热点数据缓存到 Redis,提⾼数据读取和系统响应速度。
- 将⽤户凭证(如 token)存⼊ Redis,实现单点登录。
- 限时业务的运⽤
- Redis 中可以使⽤ expire 命令设置⼀个键的⽣存时间,到时间后 Redis 会删除它。利⽤这⼀特性可以运⽤在限时的优惠活动信息、⼿机验证码等业务场景。
- 全局唯⼀ IDr
- Redis 由于 incrby 命令可以实现原⼦性的递增,所以可以⽤于唯⼀分布式序列号的⽣成。
- 消息队列
- 基于 List 实现:利⽤ LPUSH 和 RPOP;
- 基于 PUB/SUB 实现;
- 基于 Stream 实现。
- 共同关注
- 由于 Set ⽀持交集、并集、差集等功能,可以实现共同关注、共同爱好等功能。
- 排⾏榜
- 由于 SortedSet 是⽀持排序的,可以⽤于各种排⾏榜的场景。
- 统计活跃⽤户
- 利⽤ BitMap,以⽇期为 key,⽤户 ID 为 offset,当⽇活跃过就设置为 1。
- ⻚⾯统计 UV
- 将访问指定⻚⾯的每个⽤户 ID 添加到 HyperLogLog 中,调⽤ PFCOUNT 获取。
3. redis的持久化机制
Redis 的持久化机制主要有两种:RDB(Redis Database)和 AOF(Append Only File)。
1.RDB 持久化
RDB 持久化机制是指将 Redis 在内存中的数据以快照的形式写⼊磁盘中,可以⼿动或⾃动执⾏快照操作,将数据集的状态保存到⼀个 RDB ⽂件中。
- RDB 机制的优点在于:
- RDB 机制适合在数据集⽐较⼤时进⾏备份操作,因为它可以⽣成⼀个⾮常紧凑、经过压缩的数据⽂件,对于备份、恢复、迁移数据都很⽅便。(RDB 机制在 Redis 重启时⽐ AOF 机制更快地将 Redis 恢复到内存中。)
- RDB 机制的缺点在于:
- RDB 机制可能会出现数据丢失,因为数据是周期性地进⾏备份,⼀旦 Redis 出现问题并且上⼀次备份之后还没有进⾏过数据变更,那么这部分数据将会丢失。
- RDB 机制会造成⼀定的 IO 压⼒,当数据集⽐较⼤时,进⾏备份操作可能会阻塞 Redis 服务器进程。
应用场景:RDB 适合⽤于数据集⽐较⼤,数据恢复速度⽐较快的场景,例如备份、灾难恢复等;
2.AOF 持久化机制
AOF 持久化机制是指将 Redis 在内存中的操作命令以追加的形式写⼊到磁盘中的 AOF ⽂
件,AOF ⽂件记录了 Redis 在内存中的操作过程,只要在 Redis 重启后重新执⾏ AOF ⽂件中
的操作命令即可将数据恢复到内存中。
- AOF 机制的优点在于:
- AOF 机制⽐ RDB 机制更加可靠,因为 AOF ⽂件记录了 Redis 执⾏的所有操作命令,可以确保数据不丢失。
- AOF 机制在恢复⼤数据集时更加稳健,因为 AOF ⽂件记录了数据的操作过程,可以确保每⼀次操作都被正确地执⾏。
- AOF 机制的缺点在于:
- AOF 机制⽣成的 AOF ⽂件⽐ RDB ⽂件更⼤,当数据集⽐较⼤时,AOF ⽂件会⽐ RDB⽂件占⽤更多的磁盘空间。
- AOF 机制对于数据恢复的时间⽐ RDB 机制更加耗时,因为要重新执⾏ AOF ⽂件中的所有操作命令。
应用场景:AOF 适合⽤于数据集⽐较⼩,数据完整性⽐较重要的场景,例如⾦融、电商等⾏业。
3.RDB + AOF 混合使⽤
除了 RDB 和 AOF 外,Redis 还⽀持混合持久化机制,即同时使⽤ RDB 和 AOF 两种持久化机制,以此来发挥它们的优点。
在混合持久化机制中,使⽤ AOF 持久化机制保存每次写操作,使⽤ RDB 持久化机制保存指定时间点的数据快照,以此来达到数据恢复速度和数据完整性的平衡。
应⽤场景:
- RDB 适合⽤于数据集⽐较⼤,数据恢复速度⽐较快的场景,例如备份、灾难恢复等;
- AOF 适合⽤于数据集⽐较⼩,数据完整性⽐较重要的场景,例如⾦融、电商等⾏业。
4. redis的数据结构
- String(字符串):Redis 中最基本的数据类型,可以存储任何形式的数据,例如整数、浮点数、⼆进制数据等。
- Hash(哈希):Redis 中的⼀种键值对类型,可以存储多个键值对,每个键值对⼜是⼀个键值对结构。
- List(列表):Redis 中的⼀个有序列表类型,可以存储多个元素,每个元素都有⼀个索引,⽀持多种列表操作,例如插⼊、删除、查找等。
- Set(集合):Redis 中的⼀种⽆序集合类型,可以存储多个元素,每个元素都是唯⼀的,⽀持多种集合操作,例如交集、并集、差集等。
- Sorted Set(有序集合):Redis 中的⼀种有序集合类型,可以存储多个元素,每个元素都有⼀个分值,⽀持根据分值进⾏排序和查询等操作。
Redis 的基础数据结构有三种:字符串、列表和哈希,其他的数据类型都是基于这三种数据结构进⾏扩展和衍⽣的。例如,Redis 的 Set 数据类型就是基于字符串实现的。
除了基础数据结构之外,Redis 还提供了多种⾼级数据结构,例如:
- HyperLogLog:⼀种基数估计算法,⽤于估计⼀个数据集合的基数。
- GeoHash:⼀种地理位置编码算法,可以对地理位置信息进⾏编码和查询。
- Pub/Sub:⼀种消息队列机制,可以实现消息的订阅和发布。
- Bitmaps:⼀种位图数据结构,可以进⾏⾼效的位运算,⽤于统计⽤户在线时⻓、⽹站访
问量等。 - Lua 脚本:Redis 中可以使⽤ Lua 脚本进⾏扩展和定制,可以实现⼀些复杂的业务逻辑和算法
5. redis缓存更新策略
缓存更新是redis为了节约内存而设计出来的一个东西,主要是因为内存数据宝贵,当我们向redis插入太多数据,此时就可能会导致缓存中的数据过多,所以redis会对部分数据进行更新,或者把他叫为淘汰更合适。
内存淘汰: redis自动进行,当redis内存达到咱们设定的max-memery的时候,会自动触发淘汰机制,淘汰掉一些不重要的数据(可以自己设置策略方式)
超时剔除: 当我们给redis设置了过期时间ttl之后,redis会将超时的数据进行删除,方便咱们继续使用缓存
主动更新: 我们可以手动调用方法把缓存删掉,通常用于解决缓存和数据库不一致问题

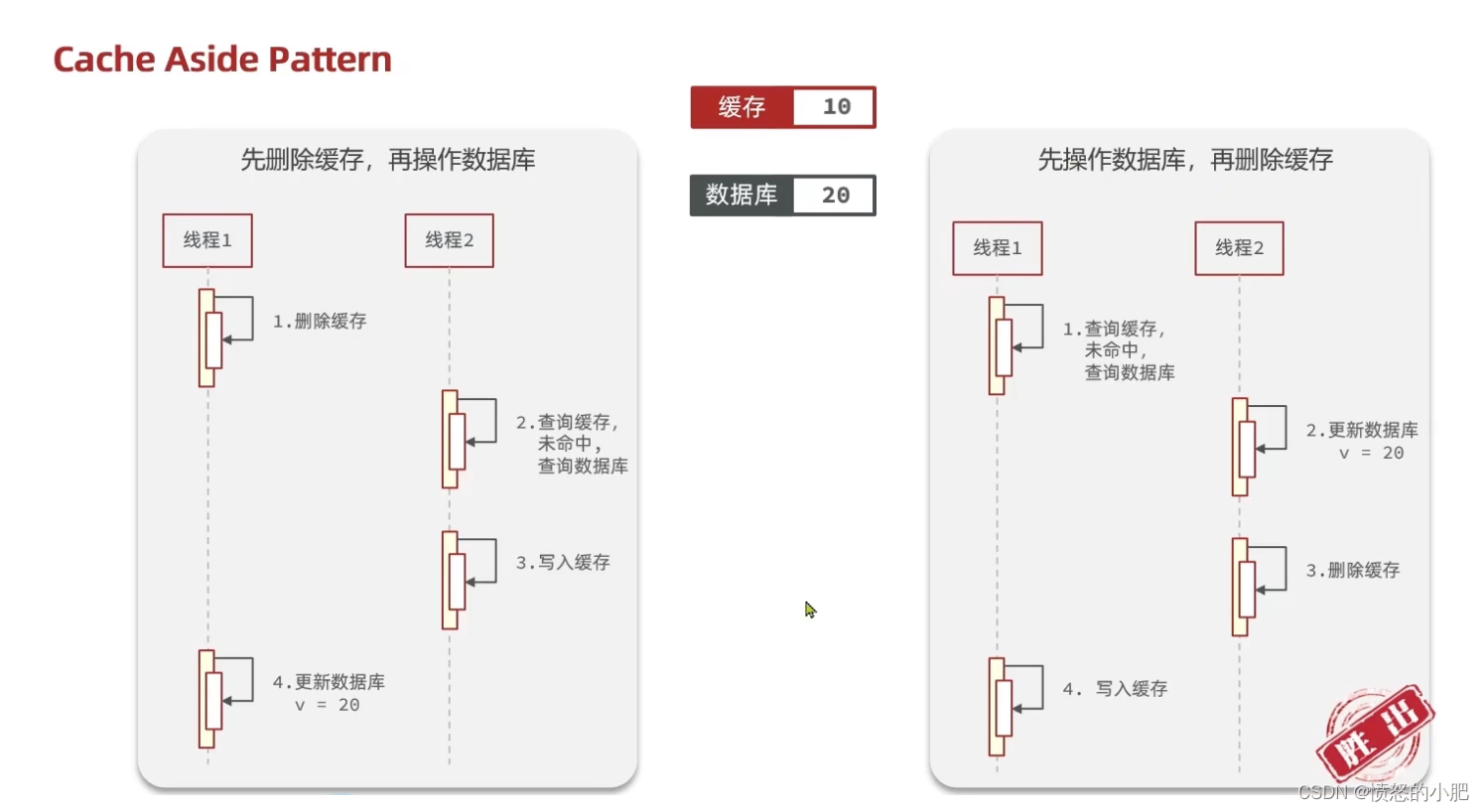
先操作缓存还是先操作数据库?
- 先删除缓存,再操作数据库
- 先操作数据库,再删除缓存
6. redis 使用过程中遇到的问题
缓存穿透
缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见的解决方案有两种:
- 缓存空对象
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成短期的不一致
- 布隆过滤
- 优点:内存占用较少,没有多余key
- 缺点:
- 实现复杂
- 存在误判可能
缓存空对象思路分析: 当我们客户端访问不存在的数据时,先请求redis,但是此时redis中没有数据,此时会访问到数据库,但是数据库中也没有数据,这个数据穿透了缓存,直击数据库,我们都知道数据库能够承载的并发不如redis这么高,如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,简单的解决方案就是哪怕这个数据在数据库中也不存在,我们也把这个数据存入到redis中去,这样,下次用户过来访问这个不存在的数据,那么在redis中也能找到这个数据就不会进入到缓存了
布隆过滤: 布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中,假设布隆过滤器判断这个数据不存在,则直接返回
这种方式优点在于节约内存空间,存在误判,误判原因在于:布隆过滤器走的是哈希思想,只要哈希思想,就可能存在哈希冲突
缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
常见的解决方案有两种:
- 互斥锁
- 逻辑过期
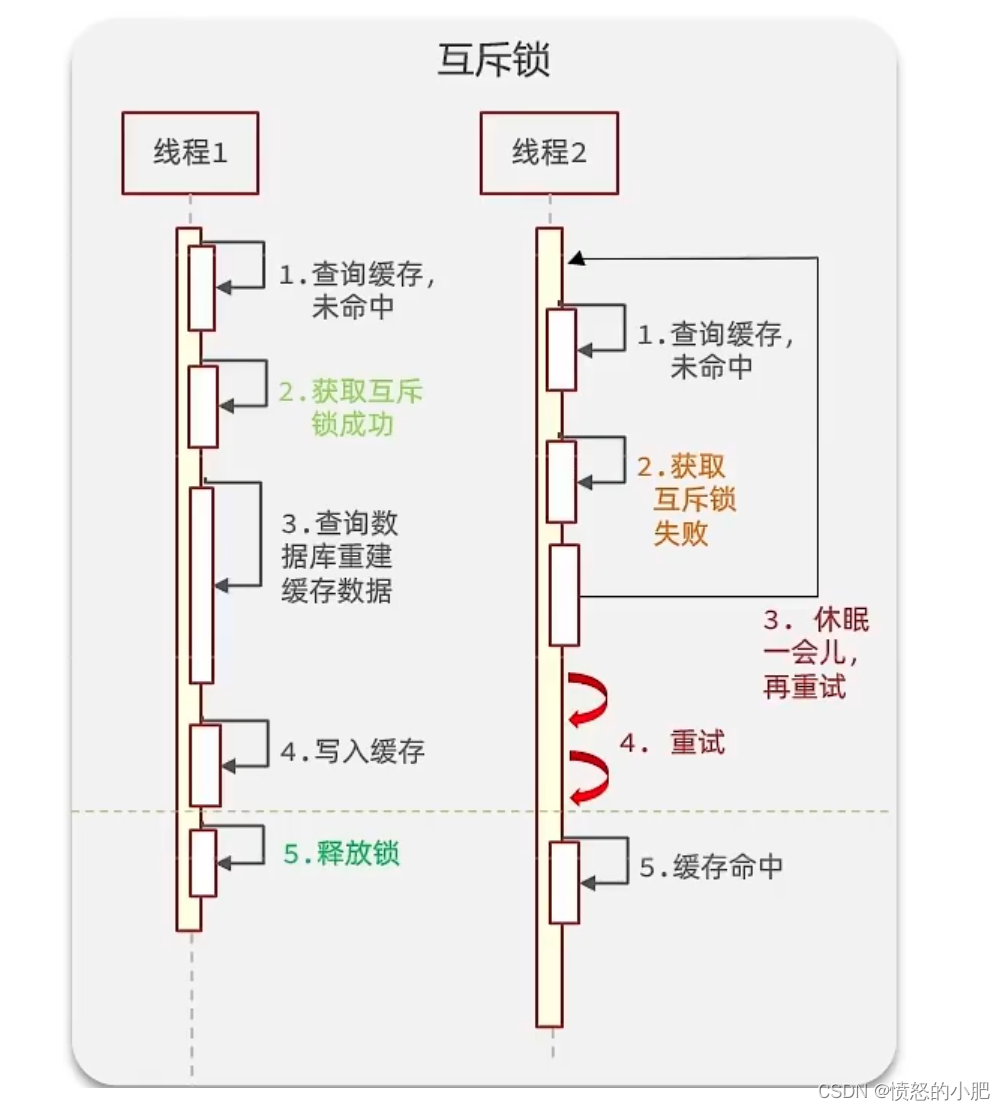
解决方案一、使用锁来解决:
因为锁能实现互斥性。假设线程过来,只能一个人一个人的来访问数据库,从而避免对于数据库访问压力过大,但这也会影响查询的性能,因为此时会让查询的性能从并行变成了串行,我们可以采用tryLock方法 + double check来解决这样的问题。
假设现在线程1过来访问,他查询缓存没有命中,但是此时他获得到了锁的资源,那么线程1就会一个人去执行逻辑,假设现在线程2过来,线程2在执行过程中,并没有获得到锁,那么线程2就可以进行到休眠,直到线程1把锁释放后,线程2获得到锁,然后再来执行逻辑,此时就能够从缓存中拿到数据了。
解决方案二、逻辑过期方案
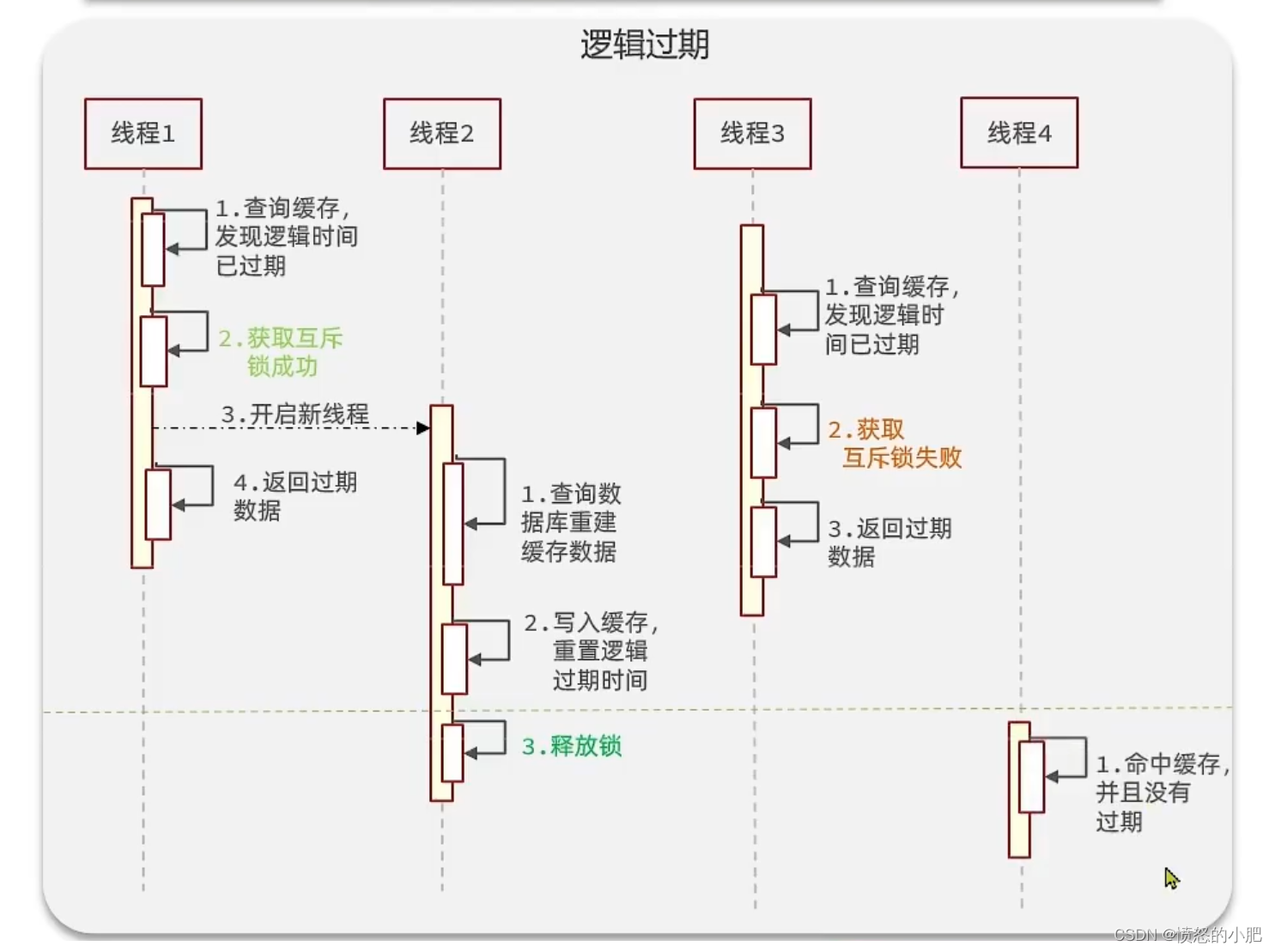
方案分析:我们之所以会出现这个缓存击穿问题,主要原因是在于我们对key设置了过期时间,假设我们不设置过期时间,其实就不会有缓存击穿的问题,但是不设置过期时间,这样数据不就一直占用我们内存了吗,我们可以采用逻辑过期方案。
我们把过期时间设置在 redis的value中,注意:这个过期时间并不会直接作用于redis,而是我们后续通过逻辑去处理。假设线程1去查询缓存,然后从value中判断出来当前的数据已经过期了,此时线程1去获得互斥锁,那么其他线程会进行阻塞,获得了锁的线程他会开启一个 线程去进行 以前的重构数据的逻辑,直到新开的线程完成这个逻辑后,才释放锁, 而线程1直接进行返回,假设现在线程3过来访问,由于线程线程2持有着锁,所以线程3无法获得锁,线程3也直接返回数据,只有等到新开的线程2把重建数据构建完后,其他线程才能走返回正确的数据。
这种方案巧妙在于,异步的构建缓存,缺点在于在构建完缓存之前,返回的都是脏数据。
互斥锁方案: 由于保证了互斥性,所以数据一致,且实现简单,因为仅仅只需要加一把锁而已,也没其他的事情需要操心,所以没有额外的内存消耗,缺点在于有锁就有死锁问题的发生,且只能串行执行性能肯定受到影响
逻辑过期方案: 线程读取过程中不需要等待,性能好,有一个额外的线程持有锁去进行重构数据,但是在重构数据完成前,其他的线程只能返回之前的数据,且实现起来麻烦

 浙公网安备 33010602011771号
浙公网安备 33010602011771号