
深度学习-Tensorflow2.2-深度学习基础和tf.keras{1}-优化函数,学习速率,反向传播,网络优化与超参数选择,Dropout 抑制过拟合概述-07
多层感知器:

优化使用梯度下降算法






学习速率




学习速率选取原则

反向传播



SGD


RMSprop


Adam



learning_rate=0.01
# -*- coding: utf-8 -*-
# -*- coding: utf-8 -*-
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 修改警告级别,不显示警告
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 下载数据集并划分为训练集和测试集
(train_image,train_lable),(test_image,test_label) = tf.keras.datasets.fashion_mnist.load_data()
# 归一化
train_image=train_image/255
test_image=test_image/255
# 建立模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28))) # 28*28
model.add(tf.keras.layers.Dense(128,activation="relu"))
model.add(tf.keras.layers.Dense(10,activation="softmax"))
# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss="sparse_categorical_crossentropy",
metrics=["acc"]
)
#使用训练集训练模型
model.fit(train_image,train_lable,epochs=5)
# # 使用测试集进行评价
# model.evaluate(test_image,test_label)

learning_rate=0.001
# -*- coding: utf-8 -*-
# -*- coding: utf-8 -*-
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 修改警告级别,不显示警告
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 下载数据集并划分为训练集和测试集
(train_image,train_lable),(test_image,test_label) = tf.keras.datasets.fashion_mnist.load_data()
# 归一化
train_image=train_image/255
test_image=test_image/255
# 建立模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28))) # 28*28
model.add(tf.keras.layers.Dense(128,activation="relu"))
model.add(tf.keras.layers.Dense(10,activation="softmax"))
# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss="sparse_categorical_crossentropy",
metrics=["acc"]
)
#使用训练集训练模型
model.fit(train_image,train_lable,epochs=5)
# # 使用测试集进行评价
# model.evaluate(test_image,test_label)

网络优化与超参数选择



如何提高网络得拟合能力



# -*- coding: utf-8 -*-
# -*- coding: utf-8 -*-
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 修改警告级别,不显示警告
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 下载数据集并划分为训练集和测试集
(train_image,train_lable),(test_image,test_label) = tf.keras.datasets.fashion_mnist.load_data()
# 归一化
train_image=train_image/255
test_image=test_image/255
# 建立模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28))) # 28*28
model.add(tf.keras.layers.Dense(128,activation="relu"))
model.add(tf.keras.layers.Dense(128,activation="relu")) # 增加隐藏层提高拟合能力
model.add(tf.keras.layers.Dense(128,activation="relu"))
model.add(tf.keras.layers.Dense(10,activation="softmax"))
# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss="sparse_categorical_crossentropy",
metrics=["acc"]
)
#使用训练集训练模型
model.fit(train_image,train_lable,epochs=10)
# # 使用测试集进行评价
# model.evaluate(test_image,test_label)
Dropout 抑制过拟合与网络超参数总原则

为什么说Dropout可以解决过拟合









增加层数,直到过拟合
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# 下载数据集并划分为训练集和测试集
(train_image,train_lable),(test_image,test_label) = tf.keras.datasets.fashion_mnist.load_data()
# 归一化
train_image=train_image/255
test_image=test_image/255
# 建立模型
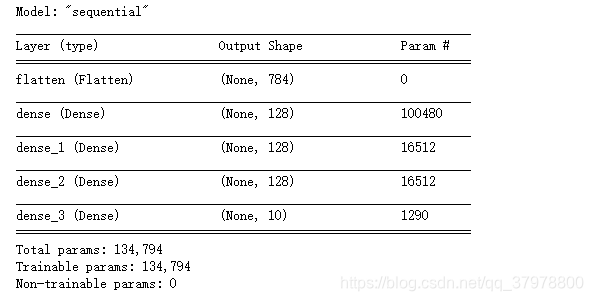
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28))) # 28*28
model.add(tf.keras.layers.Dense(128,activation="relu"))
model.add(tf.keras.layers.Dense(128,activation="relu"))# 增加隐藏层提高拟合能力
model.add(tf.keras.layers.Dense(128,activation="relu"))
model.add(tf.keras.layers.Dense(10,activation="softmax"))
model.summary()
# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss="sparse_categorical_crossentropy",
metrics=["acc"]
)
# 使用训练集训练模型 并验证测试集
history = model.fit(train_image,train_lable,
epochs=10,
validation_data=(test_image,test_label))

history.history.keys() # [训练集'loss', 'acc', 测试集'val_loss', 'val_acc']

# 如下图过拟合现象,在训练集上一直在下降,在测试集上到7层的时候反而上升了
plt.plot(history.epoch,history.history.get("loss"),label="loss")
plt.plot(history.epoch,history.history.get("val_loss"),label="val_loss")
plt.legend()

# 通过正确率绘图反映模型在训练集上正确率一直在上升,在测试集上反而下降了
plt.plot(history.epoch,history.history.get("acc"),label="acc")
plt.plot(history.epoch,history.history.get("val_acc"),label="val_acc")
plt.legend()


使用Dropout 抑制过拟合
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# 下载数据集并划分为训练集和测试集
(train_image,train_lable),(test_image,test_label) = tf.keras.datasets.fashion_mnist.load_data()
# 归一化
train_image=train_image/255
test_image=test_image/255
# 建立模型 (3层128个隐藏单元)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28))) # 28*28
model.add(tf.keras.layers.Dense(128,activation="relu"))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(128,activation="relu"))# 增加隐藏层提高拟合能力
model.add(tf.keras.layers.Dropout(0.5)) # 添加Dropout层抑制过拟合,随机丢弃50%数据
model.add(tf.keras.layers.Dense(128,activation="relu"))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10,activation="softmax"))
# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss="sparse_categorical_crossentropy",
metrics=["acc"]
)
# 使用训练集训练模型 并验证测试集
history = model.fit(train_image,train_lable,
epochs=10,
validation_data=(test_image,test_label))


plt.plot(history.epoch,history.history.get("loss"),label="loss")
plt.plot(history.epoch,history.history.get("val_loss"),label="val_loss")
plt.legend()

plt.plot(history.epoch,history.history.get("acc"),label="acc")
plt.plot(history.epoch,history.history.get("val_acc"),label="val_acc")
plt.legend()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号