
GAN生成对抗网络-ACGAN原理与基本实现-条件生成对抗网络05
ACGAN介绍









案例一
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import glob
gpu = tf.config.experimental.list_physical_devices(device_type='GPU')
tf.config.experimental.set_memory_growth(gpu[0], True)
import tensorflow.keras.datasets.mnist as mnist
(train_image, train_label), (_, _) = mnist.load_data()

train_image = train_image / 127.5 - 1
train_image = np.expand_dims(train_image, -1)
dataset = tf.data.Dataset.from_tensor_slices((train_image, train_label))
AUTOTUNE = tf.data.experimental.AUTOTUNE

BATCH_SIZE = 256
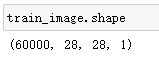
image_count = train_image.shape[0]
noise_dim = 50
dataset = dataset.shuffle(image_count).batch(BATCH_SIZE)
def generator_model():
seed = layers.Input(shape=((noise_dim,)))
label = layers.Input(shape=(()))
x = layers.Embedding(10, 50, input_length=1)(label)
x = layers.Flatten()(x)
x = layers.concatenate([seed, x])
x = layers.Dense(3*3*128, use_bias=False)(x)
x = layers.Reshape((3, 3, 128))(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.Conv2DTranspose(64, (3, 3), strides=(2, 2), use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x) # 7*7
x = layers.Conv2DTranspose(32, (3, 3), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x) # 14*14
x = layers.Conv2DTranspose(1, (3, 3), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.Activation('tanh')(x)
model = tf.keras.Model(inputs=[seed,label], outputs=x)
return model
def discriminator_model():
image = tf.keras.Input(shape=((28,28,1)))
x = layers.Conv2D(32, (3, 3), strides=(2, 2), padding='same', use_bias=False)(image)
x = layers.BatchNormalization()(x)
x = layers.LeakyReLU()(x)
x = layers.Dropout(0.5)(x)
x = layers.Conv2D(32*2, (3, 3), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.LeakyReLU()(x)
x = layers.Dropout(0.5)(x)
x = layers.Conv2D(32*4, (3, 3), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.LeakyReLU()(x)
x = layers.Dropout(0.5)(x)
x = layers.Flatten()(x)
x1 = layers.Dense(1)(x) # 真假输出
x2 = layers.Dense(10)(x) # 分类输出
model = tf.keras.Model(inputs=image, outputs=[x1, x2])
return model
generator = generator_model()
discriminator = discriminator_model()
# 损失函数
binary_cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True) # 真假损失
category_cross_entropy = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) # 交叉熵损失 多输出分类损失
def discriminator_loss(real_output, real_cat_out, fake_output, label): # 接收真图 和 真实图片的分类 假图 加label
real_loss = binary_cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = binary_cross_entropy(tf.zeros_like(fake_output), fake_output)
cat_loss = category_cross_entropy(label, real_cat_out)
total_loss = real_loss + fake_loss + cat_loss
return total_loss
def generator_loss(fake_output, fake_cat_out, label):
fake_loss = binary_cross_entropy(tf.ones_like(fake_output), fake_output)
cat_loss = category_cross_entropy(label, fake_cat_out)
return fake_loss + cat_loss
generator_optimizer = tf.keras.optimizers.Adam(1e-5)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-5)
@tf.function
def train_step(images, labels):
batchsize = labels.shape[0]
noise = tf.random.normal([batchsize, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator((noise, labels), training=True)
real_output, real_cat_out = discriminator(images, training=True)
fake_output, fake_cat_out = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output, fake_cat_out, labels)
disc_loss = discriminator_loss(real_output, real_cat_out, fake_output, labels)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
noise_dim = 50
num = 10
noise_seed = tf.random.normal([num, noise_dim])
cat_seed = np.random.randint(0, 10, size=(num, 1))
print(cat_seed.T)

def generate_and_save_images(model, test_noise_input, test_cat_input, epoch):
print('Epoch:', epoch+1)
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model((test_noise_input, test_cat_input), training=False)
predictions = tf.squeeze(predictions)
fig = plt.figure(figsize=(10, 1))
for i in range(predictions.shape[0]):
plt.subplot(1, 10, i+1)
plt.imshow((predictions[i, :, :] + 1)/2, cmap='gray')
plt.axis('off')
# plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
def train(dataset, epochs):
for epoch in range(epochs):
for image_batch, label_batch in dataset:
train_step(image_batch, label_batch)
if epoch%10 == 0:
generate_and_save_images(generator,
noise_seed,
cat_seed,
epoch)
generate_and_save_images(generator,
noise_seed,
cat_seed,
epoch)
EPOCHS = 200
train(dataset, EPOCHS)


generator.save('generate_acgan.h5')
num = 10
noise_seed = tf.random.normal([num, noise_dim])
cat_seed = np.arange(10).reshape(-1, 1)
print(cat_seed.T)
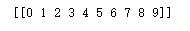

案例二


import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import glob
import random
# 显存自适应分配
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu,True)
gpu_ok = tf.test.is_gpu_available()
print("tf version:", tf.__version__)
print("use GPU", gpu_ok) # 判断是否使用gpu进行训练
with open('s.txt', 'w') as f:
f.write('ddff')
import os
image_path = glob.glob("G:/BaiduNetdiskDownload/GAN生成对抗网络入门与实战/配套资料/face/*/*.jpg")
len(image_path)
random.seed(2020)
random.shuffle(image_path)

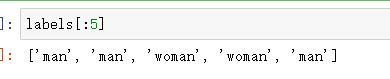
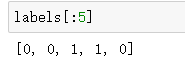
labels = [p.split("\\")[1] for p in image_path]
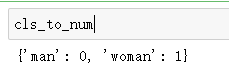
cls_to_num = dict((name, i) for i, name in enumerate(np.unique(labels)))
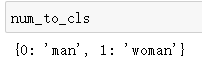
num_to_cls = {num: c for c, num in cls_to_num.items()}
labels = [cls_to_num.get(name) for name in labels]
image_path = np.array(image_path)
labels = np.array(labels)
# 编写图片加载函数预处理
@tf.function
def load_images(path):
img = tf.io.read_file(path)
img = tf.image.decode_jpeg(img, channels=3)# 解码
img = tf.image.resize(img, [80, 80])# 把图片resize成80*80的大小
img = tf.image.random_crop(img, [64, 64, 3])# 随机裁剪成64*64的大小 图像增强
img = tf.image.random_flip_left_right(img)# 左右翻转
img = tf.cast(img, tf.float32)/127.5 - 1# 归一化 255出127.5减1 0-1之间
return img
img_dataset = tf.data.Dataset.from_tensor_slices(image_path)# 创建image的数据集
AUTOTUNE = tf.data.experimental.AUTOTUNE
img_dataset = img_dataset.map(load_images, num_parallel_calls=AUTOTUNE)

label_dataset = tf.data.Dataset.from_tensor_slices(labels)# 创建label数据集
dataset = tf.data.Dataset.zip((img_dataset, label_dataset))
BATCH_SIZE = 128
image_count = len(image_path)
noise_dim = 50
dataset = dataset.shuffle(300).batch(BATCH_SIZE)# 因为前面已经乱序我们这里只需要小范围乱序
def generator_model():
seed = layers.Input(shape=((noise_dim,)))
label = layers.Input(shape=(()))
x = layers.Embedding(2, 50, input_length=1)(label)
x = layers.Flatten()(x)
x = layers.concatenate([seed, x])
x = layers.Dense(4*4*64*8, use_bias=False)(x)
x = layers.Reshape((4, 4, 64*8))(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.Conv2DTranspose(64*4, (5, 5), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x) # 8*8
x = layers.Conv2DTranspose(64*2, (5, 5), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x) # 16*16 通道数64*2
x = layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x) # 32*32
x = layers.Conv2DTranspose(3, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh')(x)
# 64*64*3
model = tf.keras.Model(inputs=[seed,label], outputs=x)
return model
def discriminator_model():
image = tf.keras.Input(shape=((64,64,3)))
x = layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', use_bias=False)(image)
x = layers.BatchNormalization()(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(64*2, (5, 5), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(64*4, (5, 5), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(64*8, (5, 5), strides=(2, 2), padding='same', use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.LeakyReLU()(x)
x = layers.Flatten()(x)
x1 = layers.Dense(1)(x)# 真假输出
x2 = layers.Dense(2)(x)# 分类输出
model = tf.keras.Model(inputs=image, outputs=[x1, x2])
return model
generator = generator_model()
discriminator = discriminator_model()
# 损失函数
binary_cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)# 真假损失
category_cross_entropy = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)# 交叉熵损失 多输出分类损失
# 判别器损失
def discriminator_loss(real_output, real_cat_out, fake_output, label):
real_loss = binary_cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = binary_cross_entropy(tf.zeros_like(fake_output), fake_output)
cat_loss = category_cross_entropy(label, real_cat_out)
total_loss = real_loss + fake_loss + cat_loss
return total_loss
# 生成器损失
def generator_loss(fake_output, fake_cat_out, label):
fake_loss = binary_cross_entropy(tf.ones_like(fake_output), fake_output)
cat_loss = category_cross_entropy(label, fake_cat_out)
return fake_loss + cat_loss
# 优化器
generator_optimizer = tf.keras.optimizers.Adam(1e-5)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-5)
noise_dim = 50
num = 10
noise_seed = tf.random.normal([num, noise_dim])
cat_seed = np.random.randint(0, 2, size=(num, 1))
print(cat_seed.T)
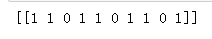
condition = [' ' + num_to_cls.get(c) + ' ' for c in cat_seed.T[0]]
print(condition)

@tf.function
def train_step(images, labels):
batchsize = labels.shape[0]
noise = tf.random.normal([batchsize, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator((noise, labels), training=True)
real_output, real_cat_out = discriminator(images, training=True)
fake_output, fake_cat_out = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output, fake_cat_out, labels)
disc_loss = discriminator_loss(real_output, real_cat_out, fake_output, labels)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def generate_and_save_images(model, test_noise_input, test_cat_input, epoch):
print('Epoch:', epoch+1)
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model((test_noise_input, test_cat_input), training=False)
fig = plt.figure(figsize=(20, 2))
for i in range(predictions.shape[0]):
plt.subplot(1, 10, i+1)
plt.imshow((predictions[i, :, :, :] + 1)/2)
plt.title(condition[i])
plt.axis('off')
# plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
def train(dataset, epochs):
for epoch in range(epochs):
for image_batch, label_batch in dataset:
train_step(image_batch, label_batch)
if epoch%10 == 0:
generate_and_save_images(generator,
noise_seed,
cat_seed,
epoch)
generate_and_save_images(generator,
noise_seed,
cat_seed,
epoch)
EPOCHS = 11000
train(dataset, EPOCHS)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号