Tigergraph高性能图数据库深入调研
TigerGraph图
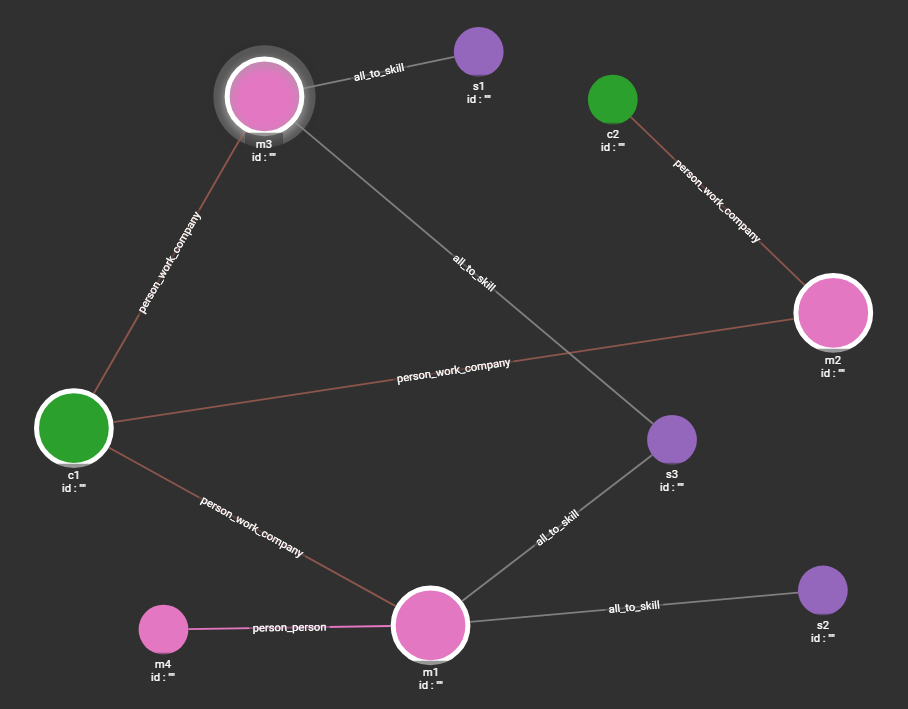
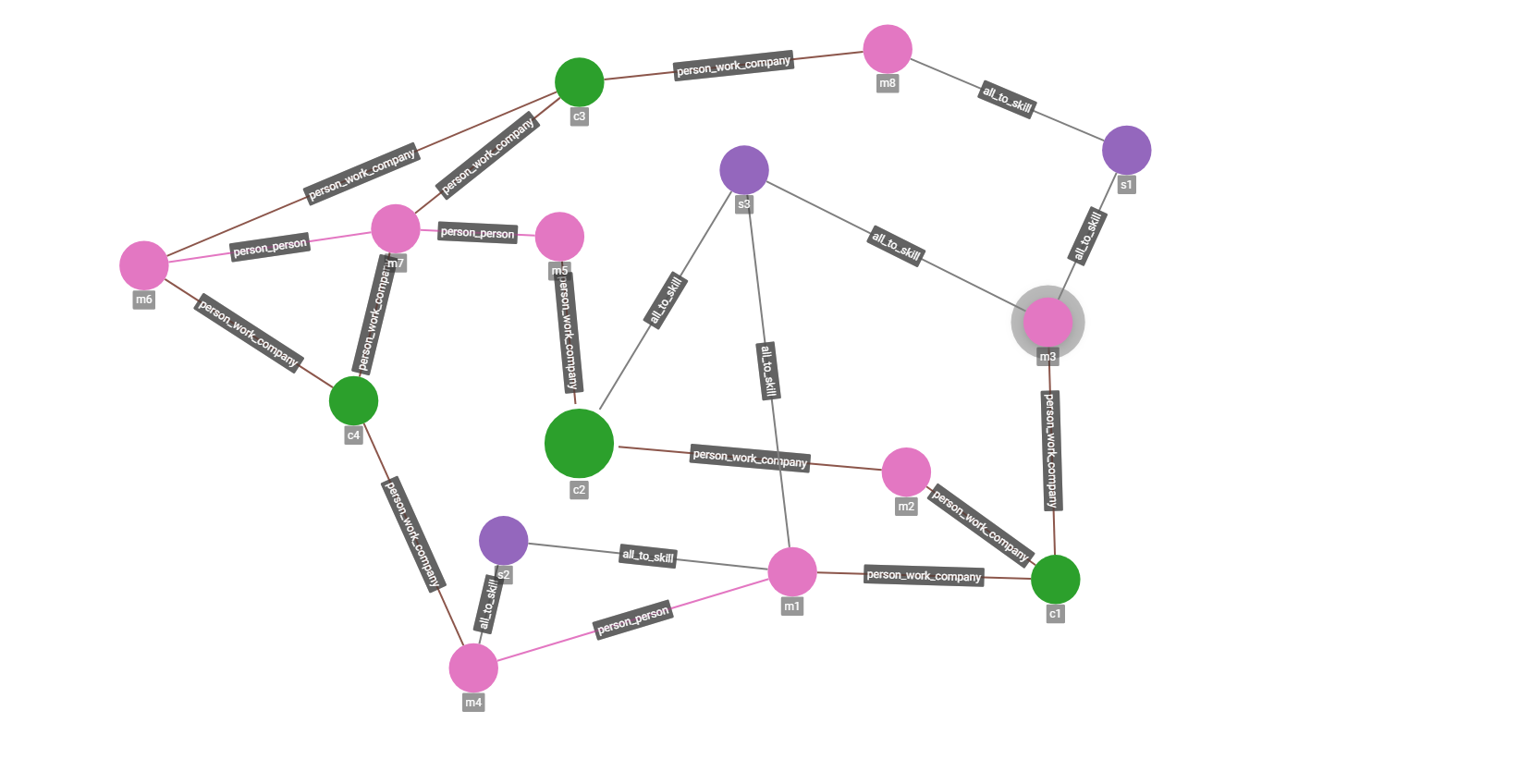
Git开源项目
https://github.com/geektcp/tigergraph-gql
概述
图数据库目前发展到第三代
第一代以neo4j为代表
第二代以Amazon Neptune为代表
第三代以tigergraph,arangodb为代表
系统架构
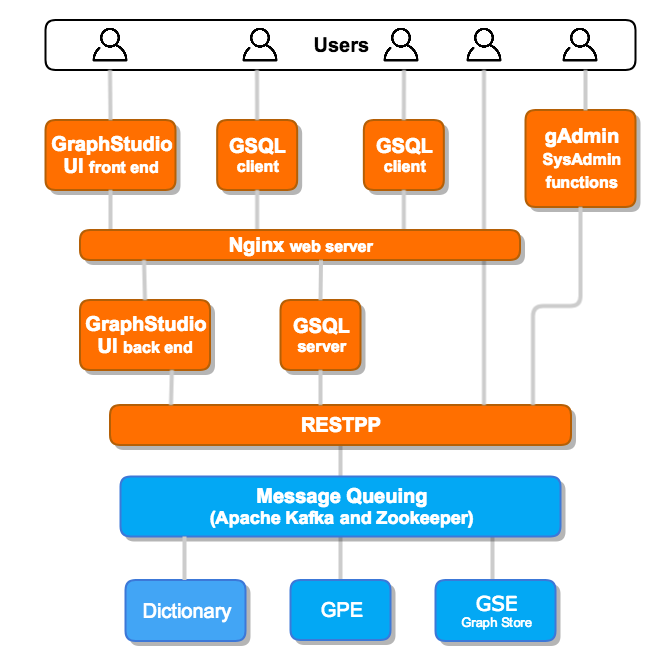
名词解释
基本概念
gadmin: 管理命令,类似mysqladmin
gbar: 备份和存储命令,backup and resotre
GSQL Shell: 用于执行sql语句,类似mysql数据库的mysql命令
GraphStudio UI: 可视化控制台
GPE:图数据库计算引擎
Graph Store: 内置的一个基于内存的数据存储组件
DICT : 数据分片,类似arangodb的内部的分片机制
GSE : 存储引擎,GSE通过GPE接收操作数据,对Graph Store进行增删改查
GSQL Language:图数据库SQL,类似arangodb的aql
GSQL: 一个内部接口,GSQL Shell调用了这个接口执行图SQL
HA: tigergraph支持高可用
IDS: GSE的内部组件,用于把顶点表、边表转换成图
IUM: 安装,升级,维护
MultiGraph: 复杂图架构,支持多个子图
Native Parallel Graph:并行图架构,支持并行存储和分析,高并发,高伸缩性
Nginx :tigergraph的前端
REST++ or RESTPP:rest api,增加、删除和查询,没有编辑
SSO :
TigerGraph Platform
TigerGraph System
Kakfa
Zookeeper
图查询计算逻辑
边的方向性
tiger的边分为有向边,无相边。
有向边和无相边的区别是:界面上有向边有明显箭头,无向边就是直线。
有向边又有单向边,双向边。
无向边由于指定了边的起点类型和终点类型,而任何顶点的类型只能有一个,无所无向边其实还是有方向的。
只有起点和终点类型都是*的时候,才是真正的无向边。
单向边无法反向遍历。
无相边和双向边都可以反向遍历。
无向边的反向遍历结果相同。
双向边的反向遍历结果中边的类型不同。
双向边和有向边的本质差别
双向边其实无向边效果差不多。
双向边和有向边的本质差别在于查询方向。双向边可以指定两个方向查询,有向边根本不能反方向查询。
原因是tiger的查询语法范式定死了格式。
SELECT t FROM vSetVarName:s – ((eType1|eType2):e) -> (vType1|vType2):t
第一个横杠-前面必须是顶点集合(冒号后面是别名,别名可以省略)
依据这个范式,最精简的写法是:
source = SELECT s FROM source:s -()-> ;
举例说明:
source = SELECT t FROM source:s -(:e)-> :t
上面的写法无法写成(因为dest是顶点集合,不是顶点类型):
dest = SELECT t FROM :s -(:e)-> dest:t
tiger和arango边的方向性
arangodb里面的边都是有向边,但是遍历方向是可以指定的,也是支持反向遍历。
FOR vertext[] IN []
FOR v,e,p in[1..3]
OUTBOUND|INBOUND|ANY startVertex [EDGES]
FILTER ...
tiger的GSQL里面要实现arangodb的AQL中的设定方向的效果,最好的方式是创建边的时候就定下来这条边是单向边还双向边。如果是单向边,创建边的时候就定好了的出的还是进的,即OUTBOUND还是INBOUND的。
如果创建边的时候指定双向边,那么遍历就是ANY方式。
在tiger的query里面不能再直接指定边的方向性了。
另外,如果都是双向边,这是遍历默认相当于arangodb的ANY方向,如何指定方向呢?
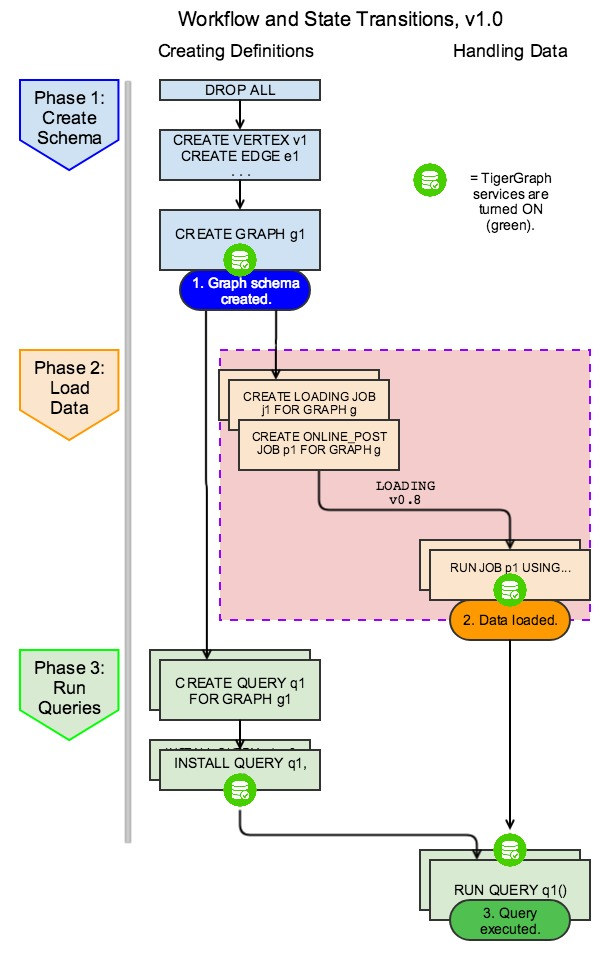
部署
安装
groupadd graph
useradd graph -g graph
visudo(添加如下一行)
graph ALL=(ALL) NOPASSWD:ALL
su - graph
wget http://dl.tigergraph.com/developer-edition/tigergraph-2.2.4-developer-patch.tar.gz
tar -zxvf tigergraph-2.2.4-developer-patch.tar.gz
cd tigergraph-2.2.4-developer
sudo ./install.sh (填入系统账号,比如当前使用graph用户,再填入安装路径即可)
卸载
官方没有提供卸载方式
建议先停掉tiger:
gadmin stop
然后注释掉crontab任务。
然后root用户下重新执行:
./install.sh -u tiger -p tiger -r /home/tiger/
./install.sh -l 40dd21b0acef8f25eca40f6a3077d458db09ea5925ba7da56894d4dcd8928d9c9340876800
gadmin --set license.key 40dd21b0acef8f25eca40f6a3077d458db09ea5925ba7da56894d4dcd8928d9c9340876800
启动和关闭
关闭tigergraph:
gadmin stop
启动tigergraph:
gadmin start
数据接入
rest导入(post)
http://192.168.1.234:9000/graph/work_graph
{
"vertices": {
"person": {
"id11": {
"id": {
"value": "sssssssss"
},
"gender": {
"value": "ttttttttttt"
}
}
}
}
}
gsql本地导入
USE GRAPH socialNet // v1.2
CREATE VERTEX engineer(PRIMARY_ID engineerId STRING, id STRING, locationId STRING, skillSet SET<INT>, skillList LIST<INT>, interestSet SET<STRING COMPRESS>, interestList LIST<STRING COMPRESS>)
CREATE VERTEX company(PRIMARY_ID clientId STRING, id STRING, country STRING)
CREATE UNDIRECTED EDGE worksFor(FROM engineer, TO company, startYear INT, startMonth INT, fullTime BOOL)
CREATE LOADING JOB loadMember FOR GRAPH socialNet {
DEFINE FILENAME f;
LOAD f
TO VERTEX engineer VALUES($0, $0, $1, _, _, SPLIT($3,"|"), SPLIT($3,"|") ),
TO TEMP_TABLE t2(id, skill) VALUES ($0, flatten($2,"|",1));
LOAD TEMP_TABLE t2
TO VERTEX engineer VALUES($0, _, _, $"skill", $"skill", _, _);
}
CREATE LOADING JOB loadCompany FOR GRAPH socialNet {
DEFINE FILENAME f;
LOAD f TO VERTEX company VALUES($0, $0, $1);
}
CREATE LOADING JOB loadMemberCompany FOR GRAPH socialNet {
DEFINE FILENAME f;
LOAD f TO EDGE worksFor VALUES($0, $1, $2, $3, $4);
}
RUN LOADING JOB loadMember USING f="./engineers"
RUN LOADING JOB loadCompany USING f="./companies"
RUN LOADING JOB loadMemberCompany USING f="./engineer_company"
数据查询
shell方式
java -jar /home/graph/tigergraph/tigergraph/dev/gdk/gsql/lib/gsql_client.jar ls
rest方式
curl -X POST \
-H "Authorization: Basic dGlnZXJncmFwaDp0aWdlcmdyYXBo" \
-H "Cookie: {"TERMINAL_WIDTH":"270","CLIENT_PATH":"/home/graph","session":"3458564839407596.1421093678"}" \
-d "LS" \
http://127.0.0.1:8123/gsql/file
curl -X POST \
-H "Authorization: Basic dGlnZXJncmFwaDp0aWdlcmdyYXBo" \
-H 'Cookie: {"TERMINAL_WIDTH":"270","CLIENT_PATH":"/home/graph","session":"3458564839407596.1421093678"}' \
-d "ls" http://127.0.0.1:8123/gsql/file
数据存储
数据导入后文件存放路径:
/home/graph/tigergraph-2.2.4/tigergraph/gstore/0/part/.mv/21/1547711697574/vertex.bin
常用命令
链接:
https://docs.tigergraph.com/admin/admin-guide/installation-and-configuration/installation-guide
系统管理
查看当前模块状态:
gadmin status
gsql --version
清空数据的三种方法:
只是清空数据(只能用于超级用户):
gsql CLEAR GRAPH STORE -HARD
清空数据和表结构(和drop all效果一样,会停掉resttpp,gse,gpe模块):
gsql --reset
删除数据和表结构(报告顶点、边、图)会停掉resttpp,gse,gpe模块:
gsql DROP ALL
关闭tigergraph:
gadmin stop
启动tigergraph:
gadmin start
查看tiger所有配置:
gadmin --dump-config
列出tiger所有日志文件路径:
gadmin log
kafka管理
查看tiger的kakfa的主题:
cd /home/tiger/tigergraph/kafka/bin/
./kafka-topics.sh --zookeeper localhost:19999 --describe
Topic:deltaQ_GPE_1Q PartitionCount:1 ReplicationFactor:1 Configs:
Topic: deltaQ_GPE_1Q Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic:post_log_Q PartitionCount:1 ReplicationFactor:1 Configs:
Topic: post_log_Q Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic:post_log_Q_RESTPP_1Q PartitionCount:1 ReplicationFactor:1 Configs:
Topic: post_log_Q_RESTPP_1Q Partition: 0 Leader: 1 Replicas: 1 Isr: 1
默认有三个topic(都是1个分区):
deltaQ_GPE_1Q
post_log_Q
post_log_Q_RESTPP_1Q
查看tiger的kafka的有哪些消费组:
cd /home/tiger/tigergraph/kafka/bin/
./kafka-consumer-groups.sh --zookeeper localhost:19999 --list
查看kafka的topic的偏离值:
cd /home/tiger/tigergraph/kafka/bin/
./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:30002 --topic deltaQ_GPE_1Q
./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:30002 --topic post_log_Q
./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:30002 --topic post_log_Q_RESTPP_1Q
经过多轮数据接入性能测试表明(实际导入的数据是6406889 ,topic的偏离值deltaQ_GPE_1Q:0:6406889):
官方的restpp接口post数据的导入方式,是通过deltaQ_GPE_1Q这个kafka的topic进行缓冲的。
kafka消息格式是字节流
消费kafka:
/home/tiger/tigergraph/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server localhost:30002 \
--topic deltaQ_GPE_1Q \
--consumer-property group.id=geektcp
如果从头开始消费,增加如下参数:
//--fromeginning
GSQL
语法
声明顶点
VERTEX<person> p1;
startpoint = to_vertex("c4", "company");
定义元组
(必须在累加器前面定义,参考C++的语法规则):
TYPEDEF TUPLE <VERTEX v, EDGE e> CHILD;
声明累加器
OrAccum @@found = false;
OrAccum @notSeen = true;
ListAccum<VERTEX> @childsVetex;
ListAccum<EDGE> @childsEdges;
赋值顶点
(和声明分开):
startpoint = to_vertex("c4", "company");
filter关键字
跟arangodb的filter不同,这不是一个通用过滤器,只能在伴随neighbors和neighborAttribute这两个函数时过滤,而且只能在ACCUM语句块中使用:
s.neighbors().filter(true),
v.@diffCountry += v.neighborAttribute("worksFor", "company", "id")
.filter(v.locationId != company.country),
JSONARRAY转LIST
JSONARRAY arr;
arr = filterObject.getJsonArray("filterEdgeType");
j = 0;
WHILE(j<arr.size()) DO
@@list += arr.getString(j);
j+=1;
END;
ACCUM关键字
用于一阶累加
POST-ACCUM关键字
用于二阶累加
一个语法糖(官方文档没有明确解释,但有这个用法,见《运算符、函数和表达式->表达式声明》):
二阶累加要调用一阶累加的变量时,加单引号即可。例如
V = SELECT s
FROM Start:s -(:e)-> :t
ACCUM t.@received_score += s.@score/(s.outdegree() +1),
t.@test += 2,
test1 = s.@score
POST-ACCUM// s.@score = (1.0-damping) + damping * s.@received_score,
s.@received_score = 0,
s.@score = 11,
@@maxDiff += abs(s.@score - s.@score'),
test2 = s.@score',
test3 = s.@score;
POST-ACCUM 里面的s.@score' 其实就是 ACCUM的变量s.@score
语法约束汇总
- 1、PRINT语句不能打印局部累加器;
- 2、仅当我们只选择了顶点集变量或顶点表达式集合中的某一部分的时候,PRINT才会打印出顶点的详细信息。 而当打印单个顶点时(即从一个变量或累加器获得数据,且它的数据类型是VERTEX),只打印顶点id。
- 3、局部变量只能在ACCUM,POST-ACCUM或UPDATE SET子句中声明,并且其作用域也仅限于该子句。 局部变量只能是基本类(例如INT,FLOAT,DOUBLE,BOOL,STRING,VERTEX),且必须在同一语句中声明的同时初始化局部变量
- 4、在局部变量的作用域内,同一级的子句中不能声明另一个相同名称的局部变量。 但是,一个新的与该变量同名的变量可以在低级别子句中(例如又嵌套了一层SELECT或UPDATE语句)使用。 即低级别的声明只在该级别工作。
- 5、声明顶点集变量时,可以选择将一组顶点类型指定给顶点集变量。 如果未明确指定顶点集变量的类型,则系统通过顶点集值隐含的类型来输出。 选择的类型可以是ANY(表示所有类型),下划线“_” (等效于ANY)或任何被明确说明的顶点类型。
- 6、在顶点集变量声明中,类型说明符跟在变量名后面,并且应该用括号括起来,如:vSetName(type)
- Ø7、通常赋值语句可以放在变量声明后的任何地方。然而,它仍然有两个限制。该限制适用于“内层”语句,即被包含在一个上层的语句块中的语句。
SELECT或UPDATE语句的正文内不允许使用全局累加器赋值
在ACCUM或POST-ACCUM子句中允许对全局变量赋值,但只有退出该子句后该值才生效。 因此,如果同一全局变量有多个赋值语句,则只有最后一个赋值语句才会生效。
ACCUM子句中不允许使用顶点属性赋值。 但是,允许对边属性赋值。 这是因为ACCUM子句是由边的集合迭代而来。
使用通用的VERTEX作为元素类型的任何累加器都不能由LOADACCUM()初始化。
- 8、每个查询都被视为一个事务(transaction)。 因此,在整个查询操作完成(确认完成)之前,对于图数据的修改不会生效。因此,某个查询中的数据更改操作不会影响同一查询中的任何其他语句。
- 10、在ACCUM子句中不允许更新顶点的属性值,因为这样的更新动作是并行运行的,同一个值可能会多次更新,从而导致输出的结果不确定。 如果顶点属性值的更新取决于边的属性值,请使用附属于顶点的累加器来保存对应的值,然后在POST-ACCUM子句中更新顶点的属性值。
- 11、元组必须在查询中的任何其他语句之前被首先定义。
- 12、申明一个顶点变量不要复制,单独一行再赋值。
- 13、evaluate传递的表达式字符串不能包含逗号。
影响是:tiger支持基础条件的复杂组合过滤条件。不过这些复杂条件要写死在存储过程里面。
- 14、tiger的逻辑运算符NOT里面不能使用顶点或者边的type字段,只能使用属性,其他运算符没有限制。
官方:NOT运算符不能与.type属性选择器结合使用。 要检查边或顶点类型是否不等于给定类型,请使用!=运算符
- 15、累加器的关键字都是区分大小写的,比如SetAccum不能写成SETACCUM
- 16、to_vertex_set允许对应的顶点不存在,to_vertex则会导致存储过程执行失败,查不出数据。
- 17、本地导入数据的语句CREATE LOADING JOB里面,加载边时,边表的表结构中的起点和终点,必须是确定,不能通配符*,如果创建边表使用了通配符*,那么无法用CREATE LOADING JOB方式导入数据。
开发
tiger的select语句其实本质上用C++语言,通过多线程,广度优先方式进行遍历。
这就是为什么全路径查询时,如果有多条路径时,结果集存在逆序。
算法
K层展开
CREATE QUERY expand_filter_pro3 (String filterStr) FOR GRAPH work_graph {
JSONOBJECT filter_object,filter_origin, filter_tmp;
INT filter_depth, filter_nodeSize, filter_sum, i, j;
BOOL filter_direction, filter_enable;
JSONARRAY filter_edges,filter_nodes,filter_origins, filter_collections,filter_value;
STRING filter_expression, filter_key;
MinAccum<INT> @accum_dis;
OrAccum @accum_visited;
ListAccum<VERTEX> @accum_path;
ListAccum<STRING> @accum_type;
OrAccum @@accum_on;
SetAccum<STRING> @@accum_edges;
SetAccum<STRING> @@accum_nodes;
ListAccum<VERTEX> @@accum_origins;
SetAccum<EDGE> @@accum_edges_result;
MapAccum<STRING, ListAccum<STRING>> @@filter_map;
ListAccum<STRING> @@filter_value;
filter_object = parse_json_object(filterStr);
filter_origins = filter_object.getJsonArray("origins");
filter_nodes = filter_object.getJsonArray("nodes");
filter_edges = filter_object.getJsonArray("edges");
filter_direction = filter_object.getBool("direction");
filter_enable = filter_object.getBool("enable");
filter_depth = filter_object.getInt("depth");
filter_nodeSize = filter_object.getInt("nodeSize");
filter_sum = filter_object.getInt("sum");
filter_expression = filter_object.getString("expression");
filter_collections = filter_object.getJsonArray("collection");
j = 0;
WHILE(j < filter_origins.size()) DO
filter_origin = filter_origins.getJsonObject(j);
@@accum_origins += to_vertex(filter_origin.getString("id"), filter_origin.getString("type"));
j += 1;
END;
j = 0;
WHILE(j < filter_edges.size()) DO
@@accum_edges += filter_edges.getString(j);
j += 1;
END;
j = 0;
WHILE(j < filter_nodes.size()) DO
@@accum_nodes += filter_nodes.getString(j);
j += 1;
END;
j = 0;
WHILE(j < filter_collections.size()) DO
filter_tmp = filter_collections.getJsonObject(j);
filter_key = filter_tmp.getString("key");
filter_value = filter_tmp.getJsonarray("value");
PRINT filter_value;
i=0;
WHILE(i < filter_value.size()) DO
@@filter_value += filter_value.getString(i);
PRINT @@filter_value;
i+=1;
END;
@@filter_map += (filter_key -> @@filter_value);
j += 1;
END;
PRINT @@filter_map;
//PRINT @@filter_map.get("company");
source = { @@accum_origins };
result = { @@accum_origins };
IF(filter_enable) THEN
source = SELECT s
FROM source:s - (:e) -> :t
ACCUM s.@accum_visited += true,
s.@accum_dis = 0,
s.@accum_path = s;
WHILE( source.size()>0 AND result.size() < filter_nodeSize) LIMIT filter_depth DO
source = SELECT t
FROM source:s -(:e)-> :t
WHERE t.@accum_visited == false
AND @@accum_edges.contains(e.type)
AND @@accum_nodes.contains(t.id)
AND s.@accum_dis < filter_sum
//AND t.city != "dongguan" OR NOT( @@filter_map.get("company").contains(t.city) AND t.sex == "female")
AND evaluate(filter_expression)
ACCUM t.@accum_dis += s.@accum_dis + 1,
t.@accum_path = s.@accum_path + [t],
t.@accum_visited += true,
@@accum_on += s.quadrant > 4,
@@accum_edges_result += e;
//HAVING t.city != "dongguan"
// OR ( t.city == "dongguan" AND t.sex == "female");
result = result UNION source;
END;
PRINT result as vertices;
PRINT @@accum_edges_result AS edges;
END;
}
最短路径
CREATE QUERY shortest_path(VERTEX startpoint, VERTEX endpoint, INT depth = 5) FOR GRAPH work_graph {
OrAccum @@found = false;
OrAccum @notSeen = true;
ListAccum<VERTEX> @childsVetex;
ListAccum<EDGE> @childsEdges;
ListAccum<VERTEX> @@vertexes;
ListAccum<EDGE> @@edges;
MapAccum<VERTEX, ListAccum<VERTEX>> @@mapVertex;
MapAccum<VERTEX, ListAccum<EDGE>> @@mapEdge;
ListAccum<VERTEX> @@tmppoint;
ListAccum<VERTEX> @@tmpkeys;
String msg;
Start = { startpoint };
result = SELECT v
FROM Start:v
ACCUM v.@notSeen = false;
WHILE NOT @@found LIMIT depth DO
Start = SELECT t
FROM Start:s - (:e) -> :t
WHERE t.@notSeen
ACCUM t.@notSeen = false,
t.@childsVetex += s,
t.@childsEdges += e,
if t == endpoint THEN
@@found += true
END
POST-ACCUM
@@mapVertex += (t -> t.@childsVetex),
@@mapEdge += (t -> t.@childsEdges);
END;
@@tmppoint += endpoint;
@@vertexes += endpoint;
WHILE true LIMIT 10 DO
@@tmpkeys.clear();
FOREACH key in @@tmppoint DO
IF(@@mapVertex.containsKey(key)) THEN
@@tmpkeys += @@mapVertex.get(key);
@@vertexes += @@mapVertex.get(key);
@@edges += @@mapEdge.get(key);
END;
END;
@@tmppoint = @@tmpkeys;
IF(@@mapVertex.containsKey(startpoint)) THEN
BREAK;
END;
END;
IF @@found THEN
PRINT @@edges;
PRINT @@vertexes;
ELSE
msg = "Can't find shortest path within max depth";
PRINT msg ;
PRINT depth;
END;
}
全路径
CREATE QUERY full_path() FOR GRAPH work_graph {
VERTEX startpoint;
VERTEX endpoint;
INT graph_depth, result_depth;
OrAccum @@found_start = FALSE;
OrAccum @@found_end = FALSE;
AndAccum @@found = TRUE;
OrAccum @notSeen = TRUE;
SetAccum<VERTEX> @nextVetexes;
SetAccum<EDGE> @nextEdges;
SetAccum<VERTEX> @lastVetexes;
SetAccum<EDGE> @lastEdges;
SetAccum<VERTEX> @@vertexes;
SetAccum<EDGE> @@edges;
MapAccum<VERTEX, SetAccum<VERTEX>> @@mapVertex;
MapAccum<VERTEX, SetAccum<EDGE>> @@mapEdge;
MapAccum<VERTEX, SetAccum<VERTEX>> @@mapVertexReverse;
MapAccum<VERTEX, SetAccum<EDGE>> @@mapEdgeReverse;
SetAccum<VERTEX> @@tmppoint;
SetAccum<VERTEX> @@tmpkeys;
SetAccum<VERTEX> @@startlist;
SetAccum<VERTEX> @@endlist;
graph_depth = 6;
result_depth = graph_depth * 2;
startpoint = to_vertex("p7", "persons");
endpoint = to_vertex("s4", "skill");
@@startlist += startpoint;
@@endlist += endpoint;
Start (ANY) = {@@startlist};
result = SELECT v
FROM Start:v
ACCUM v.@notSeen = FALSE;
WHILE TRUE LIMIT graph_depth DO
Start = SELECT t
FROM Start:s - (:e) -> :t
WHERE t.@notSeen // and e.type !="all_to_skill"
ACCUM t.@notSeen = FALSE,
t.@lastVetexes += s,
t.@lastEdges += e,
s.@nextVetexes += t,
s.@nextEdges += e
POST-ACCUM
@@mapVertex += (t -> t.@lastVetexes),
@@mapEdge += (t -> t.@lastEdges),
@@mapVertexReverse += (s -> s.@nextVetexes),
@@mapEdgeReverse += (s -> s.@nextEdges);
END;
@@tmppoint += endpoint;
@@vertexes += endpoint;
WHILE TRUE LIMIT result_depth DO
@@tmpkeys.clear();
FOREACH key in @@tmppoint DO
IF(@@mapVertex.containsKey(key)) THEN
@@tmpkeys += @@mapVertex.get(key);
@@vertexes += @@mapVertex.get(key);
@@edges += @@mapEdge.get(key);
END;
IF(@@mapVertexReverse.containsKey(key)) THEN
@@tmpkeys += @@mapVertexReverse.get(key);
@@vertexes += @@mapVertexReverse.get(key);
@@edges += @@mapEdgeReverse.get(key);
END;
END;
@@tmppoint = @@tmpkeys;
END;
FOREACH point in @@startlist DO
IF(@@vertexes.contains(point)) THEN
@@found_start += TRUE;
END;
END;
FOREACH point in @@endlist DO
IF(@@vertexes.contains(point)) THEN
@@found_end += TRUE;
END;
END;
@@found += @@found_start;
@@found += @@found_end;
PRINT @@found;
PRINT @@edges;
PRINT @@vertexes;
}
社区发现
louvain算法
pagerank
标签传播
高级过滤
余弦相似
循环三角
其他算法
高级过滤
高级过滤条件只能在结果集里面进行
因为高级过滤条件里面包含不只一个条件,如果只是查出一部分结果就进行过滤,那么这个filter要执行多次,这其实是低效的。每次查出一部分结果,比如多层展开,遍历第一层就解析过滤条件然后过滤一次,第二层又来一遍,效率很低。
传统关系型数据库的过滤条件where语句不是结果集里过滤的,而是查询过程中过滤。相当于图查询的每层展开过滤。
传统关系型数据库的复杂嵌套sql是从结果集里面过滤的,相当于图查询的结果集过滤。
常见问题
问题1:tiger的字符串转json报错
tiger的存储过程中解析json,不能直接一步到位,想这样是语法是对的,但无法正常编译:
JSONOBJECT json;
json = parse_json_object( jsonStr );
param = json.getJsonObject("param");
PRINT param.getJsonObject("options").getString("edges");
正确的写法:
JSONOBJECT options;
options = json.getJsonObject("options");
PRINT options.getString("direction");
问题2:tiger的sql里面引入文件,当tiger使用集群模式时,文件是放在哪个节点还是每个节点都要有?
这要看是否启用HA,如果没有,那么文件锁每个节点都存放对应分片。
如果有HA,假定副本是两个,那么每个分片会在两个节点存放。
开发包和企业版差别
tiger分为两个版本:Developer Edition 和 Enterprise Edition
开发版只支持单点模式,并且不支持版本升级;
企业版支持单点和集群模式
|
序号 |
功能 |
开发版 |
企业版 |
|
1 |
集群 |
否 |
是 |
|
2 |
多图 |
否 |
是 |
|
3 |
修改图 |
否 |
是 |
|
4 |
节点数无限 |
否 |
根据license |
|
5 |
高可用 |
否 |
是 |
|
6 |
权限认证 |
否 |
是 |
|
7 |
数据备份 |
否 |
是 |
|
8 |
|
|
|
|
9 |
|
|
|
|
10 |
|
|
|
|
11 |
|
|
|
|
12 |
|
|
|
|
13 |
|
|
|
|
14 |
|
|
|
|
15 |
|
|
|
|
16 |
|
|
|
|
17 |
|
|
|
|
18 |
|
|
|
|
19 |
|
|
|
|
20 |
|
|
|
参考文档
下载地址:
http://dl.tigergraph.com/developer-edition/tigergraph-2.2.4-developer-patch.tar.gz
官方文档:
https://docs.tigergraph.com/
官方开发文档:
https://www.tigergraph.com/developers/?utm_campaign=2018%20Developer%20Edition&utm_source=hs_automation&utm_medium=email&utm_content=63627934&_hsenc=p2ANqtz-9WiQx4ts5owPLxV7gy_d4JLvaLUTpa3axLLBObsV6c00DSzrw_gV9txh6Gr1af1RBpIeqBag9VWrvl2rxHlTTAHWTdLA&_hsmi=63627934
GQL:
https://doc.tigergraph.com/GSQL-101.html?utm_campaign=2018%20Developer%20Edition&utm_source=hs_automation&utm_medium=email&utm_content=63627934&_hsenc=p2ANqtz-9WiQx4ts5owPLxV7gy_d4JLvaLUTpa3axLLBObsV6c00DSzrw_gV9txh6Gr1af1RBpIeqBag9VWrvl2rxHlTTAHWTdLA&_hsmi=63627934
用户手册:
https://doc.tigergraph.com/TigerGraph-Platform-Knowledge-Base-and-FAQs.html?utm_campaign=2018%20Developer%20Edition&utm_source=hs_automation&utm_medium=email&utm_content=63627934&_hsenc=p2ANqtz-9WiQx4ts5owPLxV7gy_d4JLvaLUTpa3axLLBObsV6c00DSzrw_gV9txh6Gr1af1RBpIeqBag9VWrvl2rxHlTTAHWTdLA&_hsmi=63627934
web使用手册:
https://doc.tigergraph.com/TigerGraph-Platform-Overview.html?utm_campaign=2018%20Developer%20Edition&utm_source=hs_automation&utm_medium=email&utm_content=63627934&_hsenc=p2ANqtz-9WiQx4ts5owPLxV7gy_d4JLvaLUTpa3axLLBObsV6c00DSzrw_gV9txh6Gr1af1RBpIeqBag9VWrvl2rxHlTTAHWTdLA&_hsmi=63627934
tigergraph基础架构:
https://doc.tigergraph.com/TigerGraph-Platform-Overview.html?utm_campaign=2018%20Developer%20Edition&utm_source=hs_automation&utm_medium=email&utm_content=63627934&_hsenc=p2ANqtz-9WiQx4ts5owPLxV7gy_d4JLvaLUTpa3axLLBObsV6c00DSzrw_gV9txh6Gr1af1RBpIeqBag9VWrvl2rxHlTTAHWTdLA&_hsmi=63627934
rest api:
https://docs.tigergraph.com/dev/restpp-api/restpp-requests
构建测试数据:
https://docs.tigergraph.com/dev/gsql-ref/querying/appendix/example-graphs#socialnet
技术不在于多么高超先进巧妙,而在于要有现实价值!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号