【机器学习】:特征筛选方法
一.基于统计值的筛选方法
1.过滤法:选择特征的时候,不管模型如何,首先统计计算该特征和和label的一个相关性,自相关性,发散性等等统计指标。
优点:特征选择开销小,有效避免过拟合
缺点:没有考虑后续的学习器来选择特征,减弱了学习器的学习能力(因为某些特征可能和label算出来相关性不大,但是可能和其他特征交叉后,会和label具有很强的关联性)
2.单变量筛选法:
a:缺失值占比
b:方差
c:频数
d:信息熵
3.多变量筛选法
计算多个变量之间自己的相关性,绘制相应的相关性图,可以使用皮尔逊相关系数,斯皮尔曼相关系数等等来作为衡量。尤其是是在线性模型当中,两个共线性的模型可能对模型并不具备促进作用,反而可能会带来一些灾难性的后果。树模型则可以不考虑这种基于多变量的筛选方法。
二.基于模型验证的筛选方法
基于模型的验证集进行打分,是一种比较靠谱的方法,也是和最终模型的打分强相关的。
什么意思呢?也就是说我们每增加一些特征或者减少一些特征,我们就用来训练出一个模型,进行cv,也就是cross validation进行交叉验证,看模型的准确度是否是上升了。
我们基于这种方法对其进行改进,还有一种时间开销比较小的方法则是;排列重要性
也就是说,我们可以使用排列重要性这种方法对模型的特征进行验证和筛选。这种方法对于树模型来说基本上来说是最好的方法了。
如下图所示:
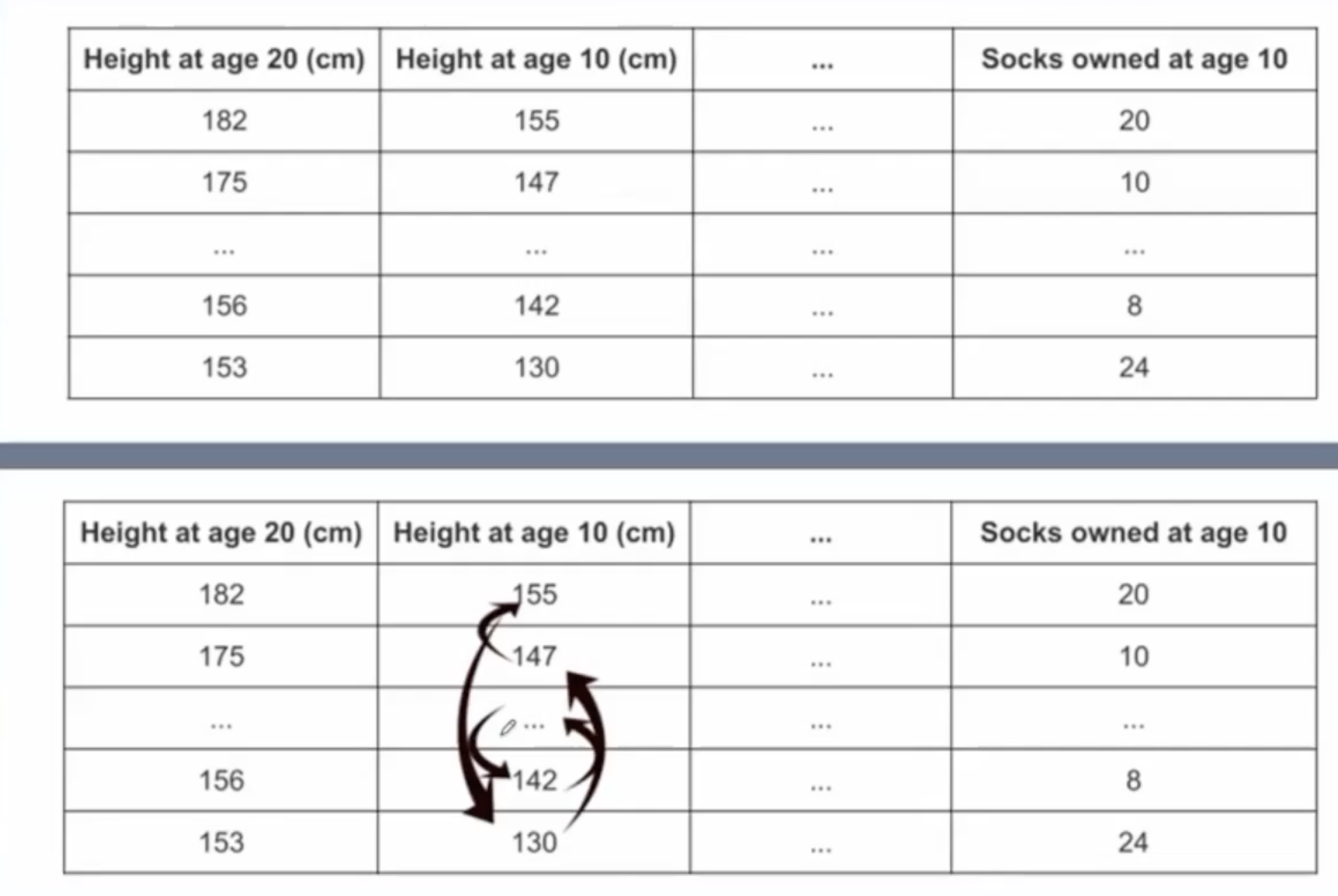
当我们已经train出一个模型之后,我们对这个模型某一个特征进行打乱,再对当前的数据进行预测,看准确度多少,如果模型的准确度下降比较多,那么说明该变量对模型的影响很大。如果准确度下降不多,则说明该变量对模型的影响不大,完全可以将其剔除。这是一个十分有效且时间复杂度比较低的一个特征筛选的方法,在我们进行特征工程的时候可以经常使用这个方法,这个方法的代码实现起来也并不是很难。
三.基于模型嵌入的筛选方法
特征选择被嵌入到学习器的训练过程当中,利用模型参数来计算特征重要性。
线性模型:使用线性模型的系数大小进行衡量(比如逻辑回归和线性回归当中某个特征的前面的系数,看是否significant)
树模型:使用特征分裂过程当中的信息增益进行衡量
深度学习:使用注意力机制的权重进行衡量
但是模型认为重要的特征,不一定重要!因为不重要的特征可能和其他特征之间具有强相关性,因此如果剔除,也可能会对模型的效果并不一定有一定的提升。模型认为不重要的,也有可能重要。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号