【自然语言处理】: transformer原理实现
1.seq2seq
一般在我们序列模型当中,都会分为encoder和decoder两个部分,如下图所示:
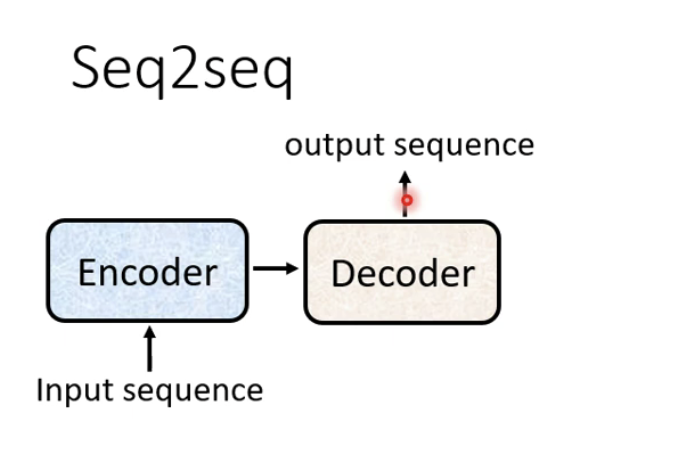
而我们的transformer变形金刚其实相当于是一种对我们seq2seq的一种升级版本,也就是在seq2seq上加上了self-attention,也就变成了我们的transformer,我们可以看到transformer的结构如下所示:
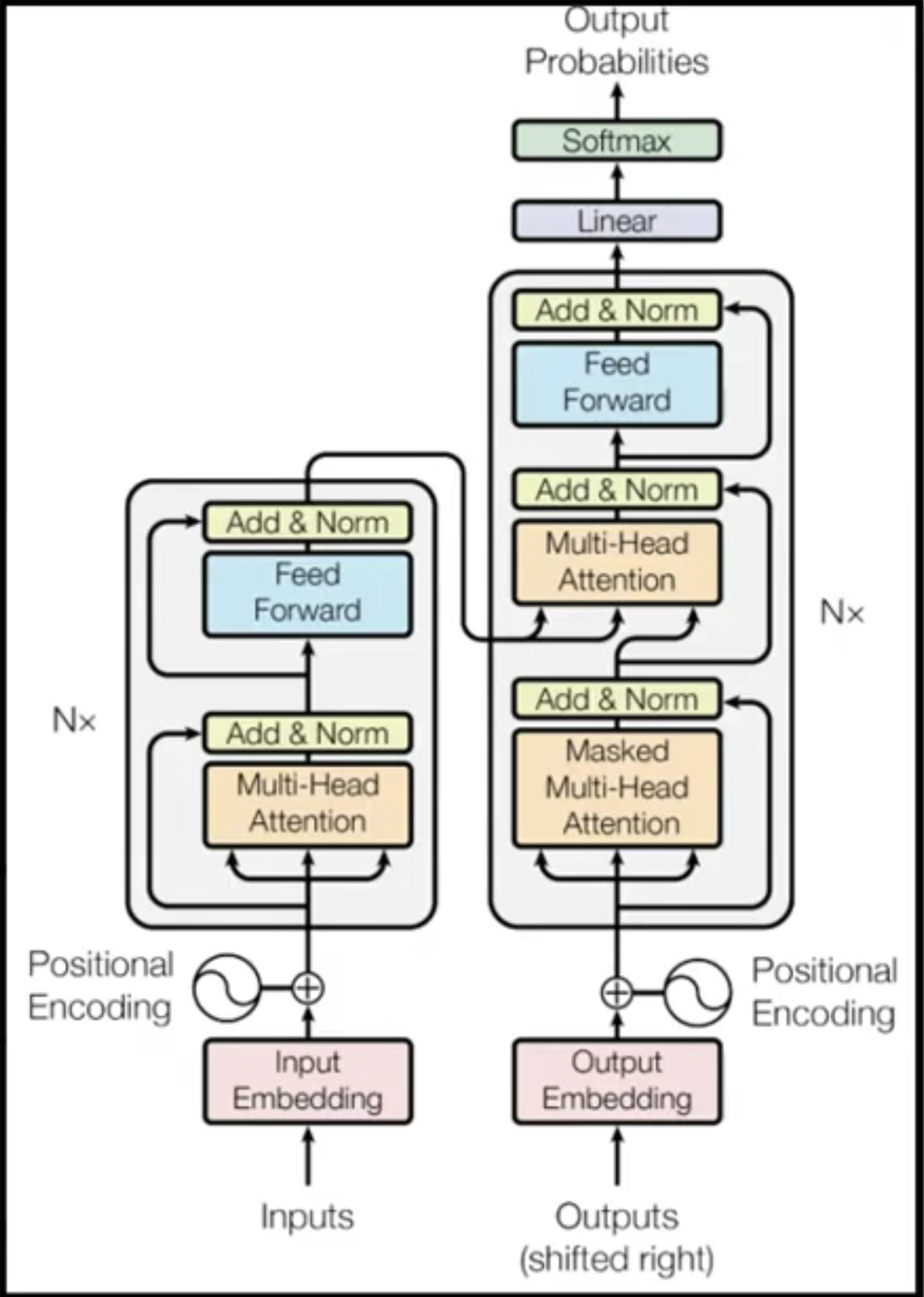
在上面这张图当中,左边的就是我们的的encoder,而右边则是我们的decoder。只是这个encoder和decoder都特别的大哈哈哈
2.Encoder的架构
encoder的架构总体来说是这样的,我们输入一排向量,然后相应的,会输出一排向量。而在我们的输入和输出之间,输入最先经过的层是一个self-attention层。

对于上图当中的第一个蓝色向量而言,首先会经过self-attention层,得到一个向量a,然后这个向量a再和之前原来初始的向量,我们成称为向量b,进行相加。得到新的向量a+b,十分类似于残差神经网络当中的一个short-cut,也就是进行一个skip connection,进行一个跳级连接。之后再进行一个layer normilization。
而这个layer normalization是什么意思呢?
也就是将我们这个layer当中所有的数值做一个正太化的处理,也就是使用公式(x-mean)/standard deviation ,就可以得到一个新的数值了。这样所有的数值也会投射到0-1的一个范围内。
做了这样的处理之后,我们看这张图的最右边,我们拿到这个normalize之后的向量c,经过一个全连接神经网络得到d,d和原来的c又进行shortcut,也就是一个risidual的连接。连接之后,再经过一个layer normilization层,这样就得到最后我们transformer encoder的一个对某一个向量的输出。
2.Decoder
如果我们把下面这张图,也就是decoder的中间,将其遮住,那么我们就可以发现其实encoder和decoder的结构几乎是一样的,如下所示: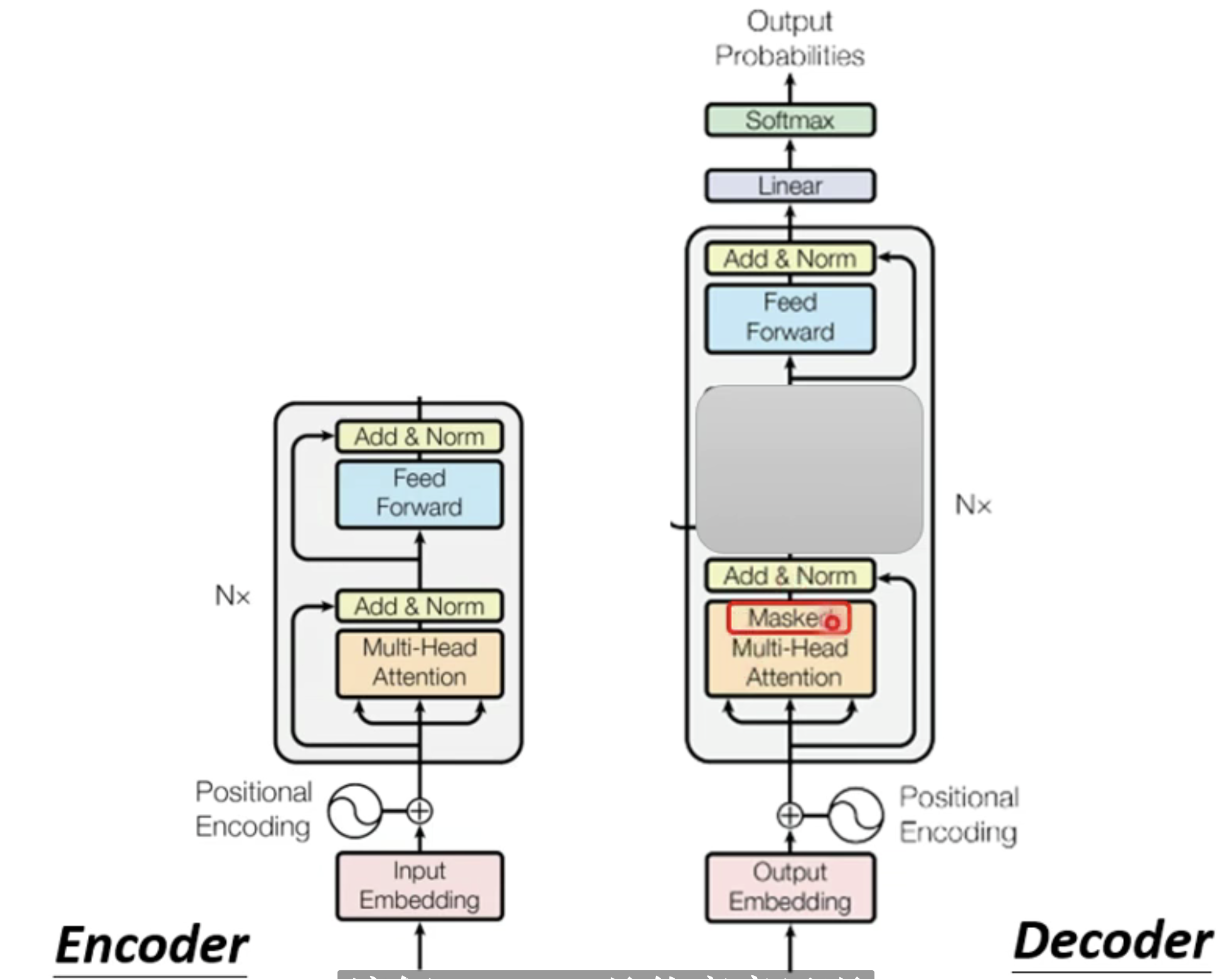
我们除了在最下方的一个attenton机制,这里加入的是masked multi head attention,而非普通的multi-head attention.
masked attention和我们普通self attention不同的地方也就是后面一个向量的输出只会考虑到前面向量的输入,而不会考虑到后面的的输入。这个其实是和RNN的道理是相似的,也很有道理。因为我们的self-attention是考虑到的整个input的输入。
然后我们的encoder是如何和decoder进行连接的呢?我们的encoder的资讯最后是传递到了decoder的中间的multihead attention进行了一个这样的连接。同时,decoder中间的multihead
attention和自己的输入,从masked multi head attention也进行了一个连接。因此我们的decoder中间层拥有了encoder传递过来的两个信息,以及masked multi head attention传递过来的一个信息,最终进行我们的训练。局部的流程图如下图所示:

整体的流程图如下所示:
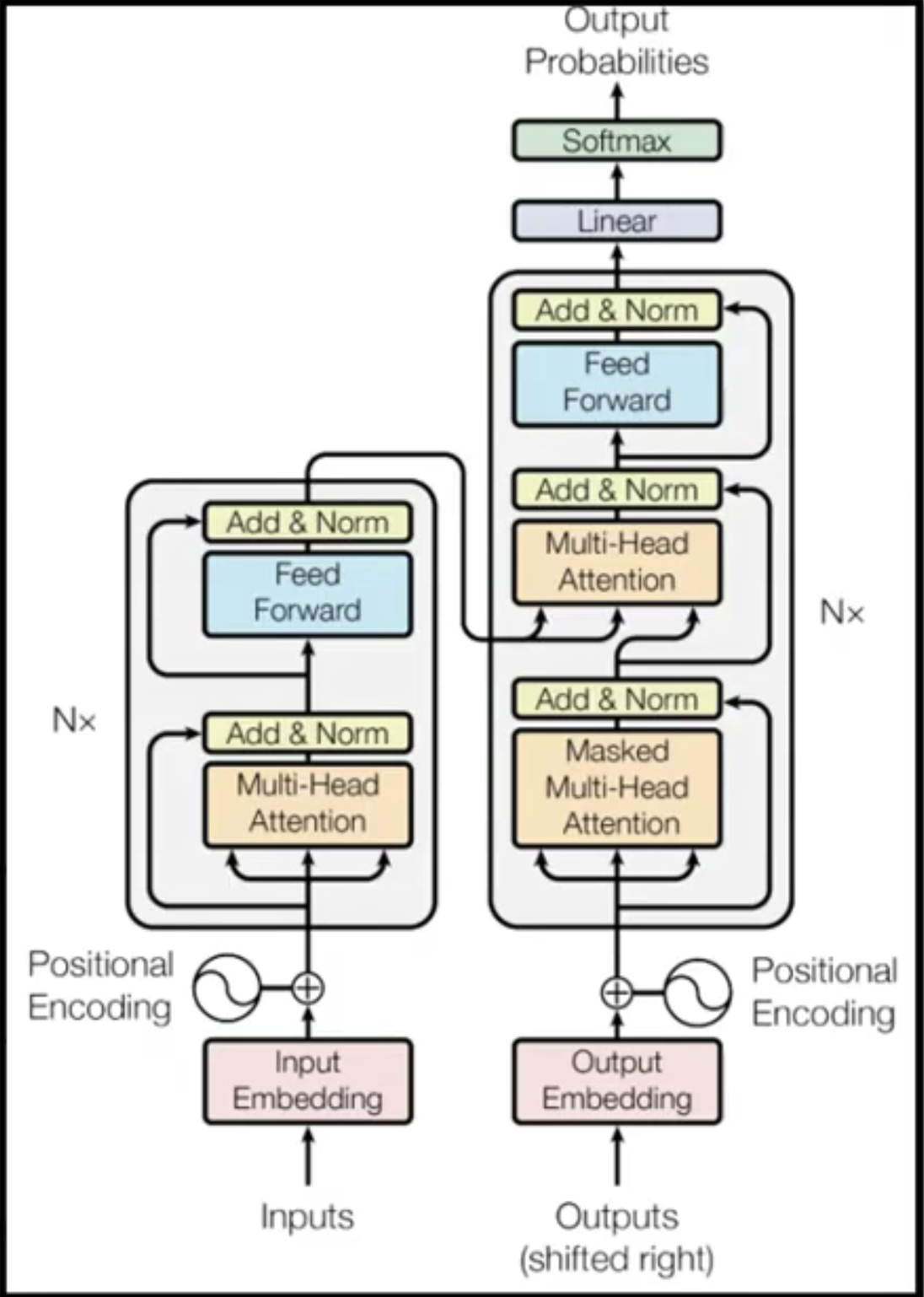
这就是tranformer的原理啦,希望大家看了之后有所收获!如有不足,也请大家多多指正!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号