十万字总结机器学习面试问题
前言
真的是千呼万唤始出来emmmm,去年春招结束写了篇面试的经验分享。在文中提到和小伙伴整理了算法岗面试时遇到的常见知识点及回答,本想着授人以渔,但没想到大家都看上了我家的 !但因本人执行力不足,被大家催到现在才终于想着行动起来分享给大家,笔者在这里给各位读者一个大大的抱歉,求原谅呜呜~~相信今年参加秋招的小伙伴们一定都拿到理想的offer啦,明年准备找工作的小盆友如果觉得本文还有些用可以收藏哈。
由于篇幅限制,就先发出前半部分,后面等下回笔者得空哈~另外欢迎小伙伴们转发!转发!再转发呀!!转发请注明出处,且谢绝一切利用本文档的商业行为!!
第一章 机器学习
1.Batch Normalization
背景:由于Internal Covariate Shift(Google)效应,即深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。 也就是随是着网络加深,参数分布不断往激活函数两端移动(梯度变小),导致反向传播出现梯度消失,收敛困难。
原理:可在每层的激活函数前,加入BN,将参数重新拉回0-1正态分布,加速收敛。(理想情况下,Normalize的均值和方差应当是整个数据集的,但为了简化计算,就采用了mini_batch的操作)
*机器学习中的白化(eg.PCA)也可以起到规范化分布的作用,但是计算成本过高。

*BN不是简单的归一化,还加入了一个y = γx+β的操作,用于保持模型的表达能力。否则相当于仅使用了激活函数的线性部分,会降低模型的表达能力。

训练与测试:测试时均值和方差不再用每个mini-batch来替代,而是训练过程中每次都记录下每个batch的均值和方差,训练完成后计算整体均值和方差用于测试。
参考:https://blog.csdn.net/sinat_33741547/article/details/87158830
https://blog.csdn.net/qq_34484472/article/details/77982224
https://zhuanlan.zhihu.com/p/33173246
*BN对于Relu是否仍然有效?
有效,学习率稍微设置大一些,ReLU函数就会落入负区间(梯度为0),神经元就会永远无法激活,导致dead relu问题。BN可以将数据分布拉回来。
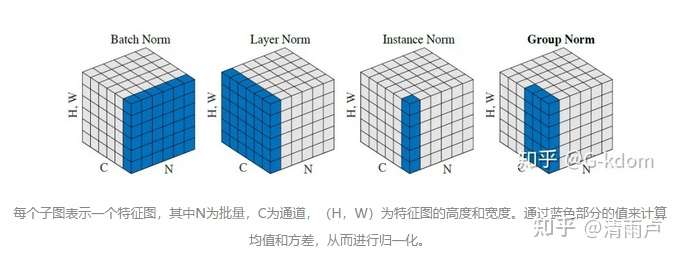
*四种主流规范化方法
Batch Normalization(BN):纵向规范化
Layer Normalization(LN):横向规范化 对于单个样本
Weight Normalization(WN):参数规范化 对于参数
Cosine Normalization(CN):余弦规范化 同时考虑参数和x数据
*多卡同步
- 原因
对于BN来说,用Batch的均值和方差来估计全局的均值和方差,但因此Batch越大越好.但一个卡的容量是有限的,有时可能batch过小,就起不到BN的归一化效果.
- 原理
利用多卡同步,单卡进行计算后,多卡之间通信计算出整体的均值和方差,用于BN计算, 等同于增大batch size 大小.
2次同步? 第一次同步获得全局均值,然后第二次计算全局方差
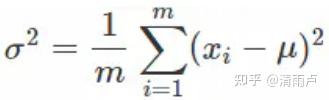
1次同步! 直接传递一次X和X2,就可直接计算出全局均值和方差.
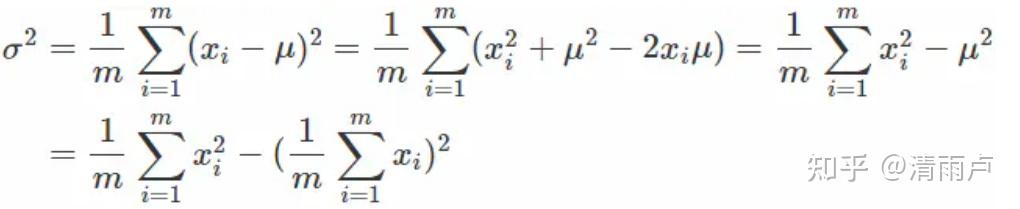
- 操作(pytorch)

注:
- 对于目标检测和分类而言,batch size 通常可以设置的比较大,因此不用多卡否则反而会因为卡间通讯,拖慢训练速度.
- 对于语义分割这种稠密的问题而言,分辨率越高效果越好,因此一张卡上容纳的batch size 比较小,需要多卡同步.
- 数据被可使用的GPU卡分割(通常是均分),因此每张卡上BN层的batch size(批次大小)实际为:Batch Size/nGpu
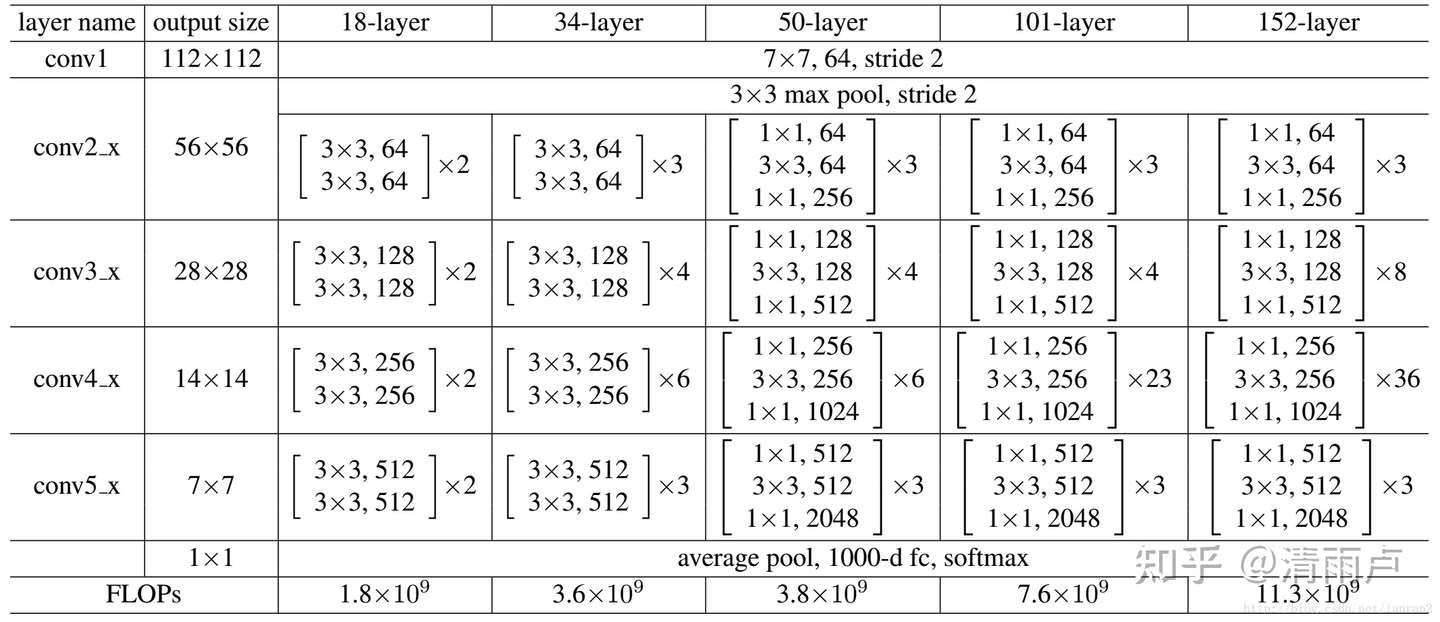
2.VGG使用使用3*3卷积核的优势是什么?
2个3x3的卷积核串联和一个5x5的卷积核拥有相同的感受野,但是,2个3x3的卷积核拥有更少的参数,对于通道为1的5x5特征图得到通道为1的输出特征图,前者有3x3x2=18个参数,后者5x5=25个参数,其次,多个3x3的卷积核比一个较大的尺寸的卷积核加入了更多的非线性函数,增强了模型的非线性表达能力。
1x1卷积核的作用:改变通道数目,保持尺度不变情况下增强非线性表达能力,可以实现跨通道的信息交互。
VGG:
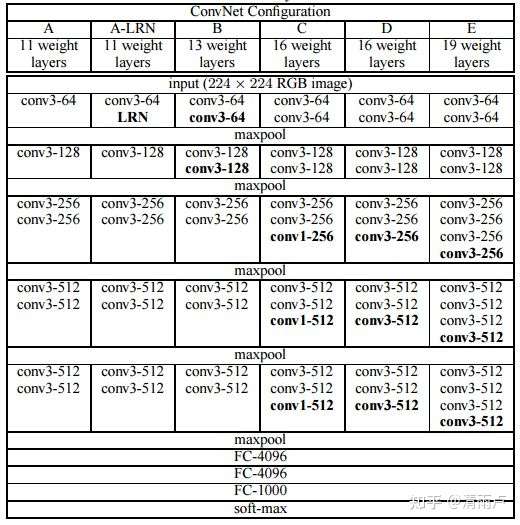
ResNet:
3.逻辑斯蒂回归(LR, Logistic Regression)
3.1 模型简介
分布函数与概率密度函数:
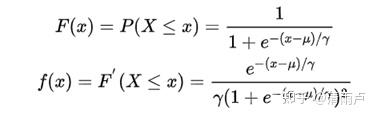
其中,μ表示位置参数,γ为形状参数。在深度学习中常用到的 Sigmoid 函数就是 Logistic 的分布函数在μ=0,γ=1的特殊形式。
损失函数:
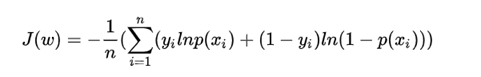
求解方法:1.随机梯度下降法 2.牛顿法
参考 https://zhuanlan.zhihu.com/p/74874291
3.2 相关问题
一、LR有什么特点?
简单、容易欠拟合、值域为(0,1)、无穷阶连续可导。
各feature之间不需要满足条件独立假设,但各个feature的贡献独立计算
二、Sigmoid变化的理解?
a) sigmoid函数光滑,处处可导,导数还能用自己表示
b) sigmoid能把数据从负无穷到正无穷压缩到0,1之间,压缩掉了长尾,扩展了核心分辨率。
c) sigmoid在有观测误差的情况下最优的保证了输入信号的信息。
三、与SVM、线性回归等模型对比
参考 https://zhuanlan.zhihu.com/p/74874291
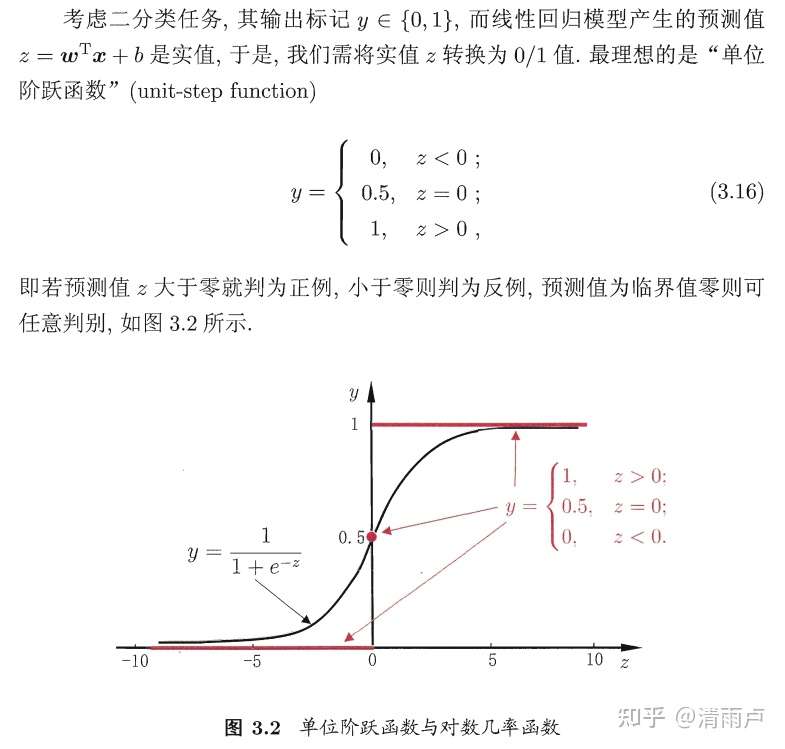
因为阶跃函数不连续,寻找替代函数如 sigmoid:


作变换可得到:
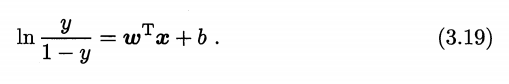
即用线性回归的结果去拟合事件发生几率(“几率”是事件发生与不发生的概率比值)的对数,这就是“对数几率回归”的名称来由,其名为回归,实际上是做分类任务。
为什么不用均方误差作为损失:


4.卷积
原理:卷积过程就是卷积核行列对称翻转后,在图像上滑动,并且依次相乘求和.(与滤波器不同的一点就是多了一个卷积核翻转的过程).然后经过池化,激活后输入下一层. 单个卷积层可以提取特征,当多个卷积叠加后即可逐步学习出更高语义的抽象特征.
*这里提到了卷积,池化以及激活,那么池化以及激活的顺序如何考虑?一般来说池化和激活的顺序对计算结果没有影响(其实是maxpooling无影响,但是如果用avgpooling的话,先后顺序还是会影响结果一点的),但先池化可以减小接下来激活的计算量.
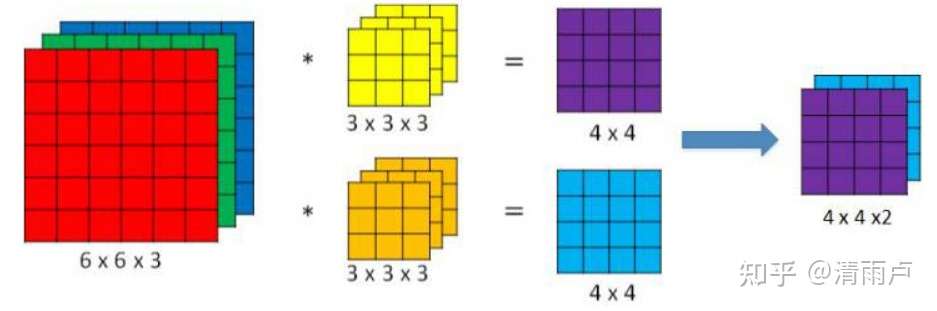
卷积核:其中卷积核主要有两类,普通卷积核和1*1的卷积核.
普通卷积核同时改变图像的空间域和通道域,如下图所示,每个卷积核的通道数与输入相同,卷积后会得到一个通道为一的特征图,我们希望卷积后的通道数有几个,卷积核就有几个.
1*1卷积核,视野大小为单个特征位点,能够实现在空间域不改变的情况下实现通道域信息的交流,并且获得我们想要的通道数量(一般是降维).
另外,1*1的卷积可以看作全连接.
参考:https://blog.csdn.net/amusi1994/article/details/81091145?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
反卷积:上采样有3种常见的方法:双线性插值(bilinear),反卷积(Transposed Convolution),反池化(Unpooling),我们这里只讨论反卷积。这里指的反卷积,也叫转置卷积,它并不是正向卷积的完全逆过程,用一句话来解释:
反卷积是一种特殊的正向卷积,先按照一定的比例通过补0来扩大输入图像的尺寸,接着旋转卷积核,再进行正向卷积。



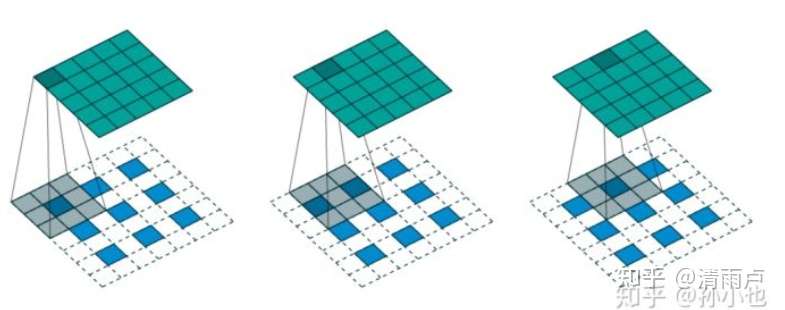
https://www.zhihu.com/question/48279880
空洞卷积
诞生背景
在图像分割领域,图像输入到CNN(典型的网络比如FCN[3])中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野,但是由于图像分割预测是pixel-wise的输出,所以要将pooling后较小的图像尺寸upsampling到原始的图像尺寸进行预测,在先减小后增大尺寸的过程中,肯定有些信息损失掉了,如何避免?答案就是空洞卷积。
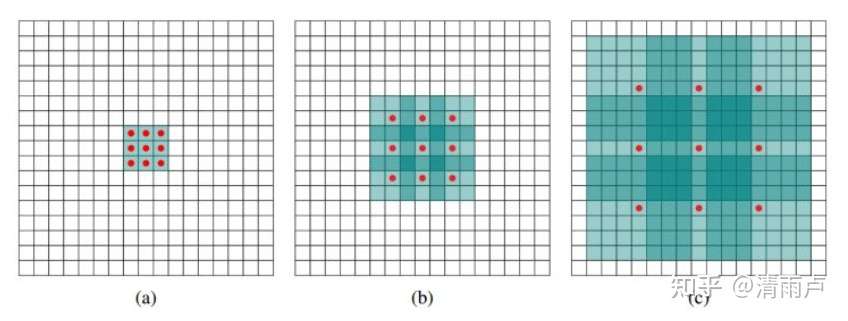
(a)图对应3x3的1-dilated conv,和普通的卷积操作一样,(b)图对应3x3的2-dilated conv,实际的卷积kernel size还是3x3,但是空洞为1,也就是对于一个7x7的图像patch,只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。(c)图是4-dilated conv操作
优点
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者语音文本需要较长的sequence信息依赖的问题中,都能很好的应用dilated conv,比如图像分割、语音合成WaveNet、机器翻译ByteNet中。
潜在问题 1:The Gridding Effect
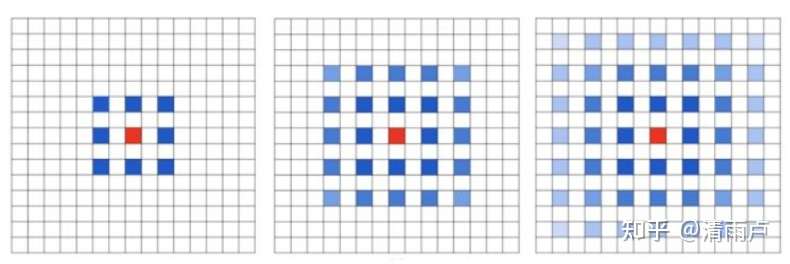
我们发现我们的 kernel 并不连续,也就是并不是所有的 pixel 都用来计算了,因此这里将信息看做 checker-board 的方式会损失信息的连续性。这对 pixel-level dense prediction 的任务来说是致命的。
潜在问题 2:Long-ranged information might be not relevant.
我们从 dilated convolution 的设计背景来看就能推测出这样的设计是用来获取 long-ranged information。然而光采用大 dilation rate 的信息或许只对一些大物体分割有效果,而对小物体来说可能则有弊无利了。如何同时处理不同大小的物体的关系,则是设计好 dilated convolution 网络的关键。
通向标准化设计:Hybrid Dilated Convolution (HDC)
对于上个 section 里提到的几个问题,图森组的文章对其提出了较好的解决的方法。他们设计了一个称之为 HDC 的设计结构。
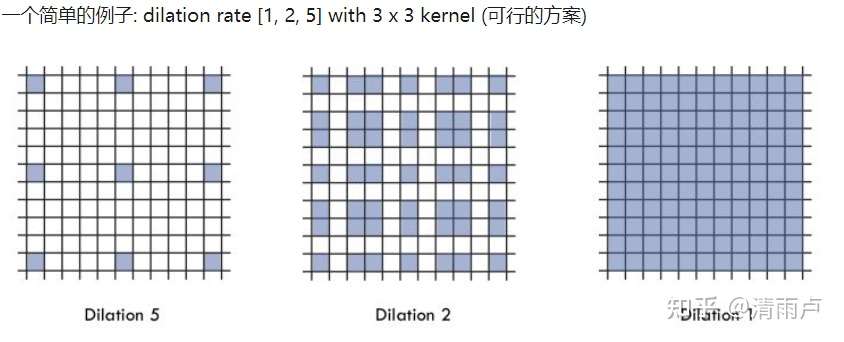
第一个特性是,叠加卷积的 dilation rate 不能有大于1的公约数。比如 [2, 4, 6] 则不是一个好的三层卷积,依然会出现 gridding effect。
第二个特性是,我们将 dilation rate 设计成 锯齿状结构,例如 [1, 2, 5, 1, 2, 5] 循环结构。
第三个特性是,我们需要满足一下这个式子:
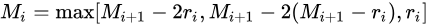
ri 是i层的dilation rate, Mi是i层的最大dilation rate, 那么假设总共有n层的话,默认 Mn = rn 。假设我们应用于 kernel 为 k x k 的话,我们的目标则是M2 <= k ,这样我们至少可以用 dilation rate 1 即 standard convolution 的方式来覆盖掉所有洞。
基于港中文和商汤组的 PSPNet 里的 Pooling module (其网络同样获得当年的SOTA结果),ASPP 则在网络 decoder 上对于不同尺度上用不同大小的 dilation rate 来抓去多尺度信息,每个尺度则为一个独立的分支,在网络最后把他合并起来再接一个卷积层输出预测 label。这样的设计则有效避免了在 encoder 上冗余的信息的获取,直接关注与物体之间之内的相关性。
https://www.zhihu.com/question/54149221
卷积的三种模式:
通常用外部api进行卷积的时候,会面临mode选择
其实这三种不同模式是对卷积核移动范围的不同限制
设 image的大小是7x7,filter的大小是3x3
- full mode
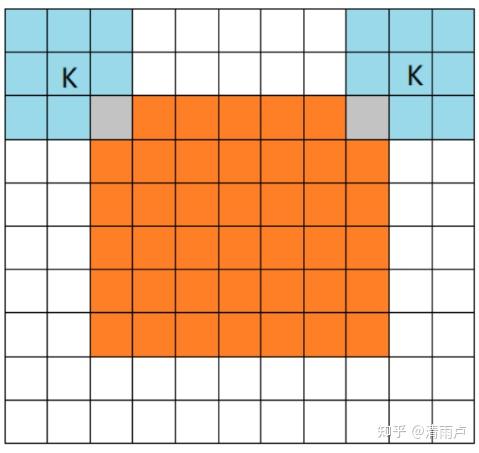
橙色部分为image, 蓝色部分为filter。full模式的意思是,从filter和image刚相交开始做卷积,白色部分为填0。filter的运动范围如图所示。
- same mode
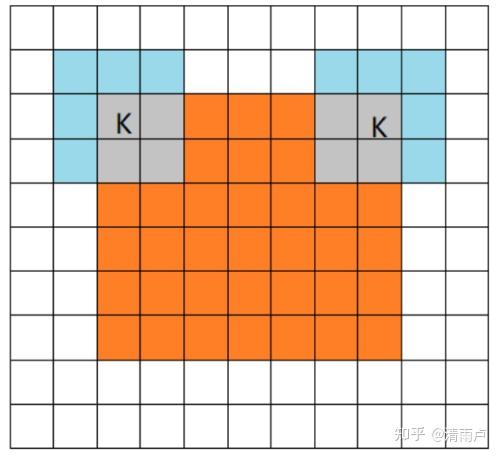
当filter的中心(K)与image的边角重合时,开始做卷积运算,可见filter的运动范围比full模式小了一圈。注意:这里的same还有一个意思,卷积之后输出的feature map尺寸保持不变(相对于输入图片)。当然,same模式不代表完全输入输出尺寸一样,也跟卷积核的步长有关系。same模式也是最常见的模式,因为这种模式可以在前向传播的过程中让特征图的大小保持不变,调参师不需要精准计算其尺寸变化(因为尺寸根本就没变化)。
- valid mode
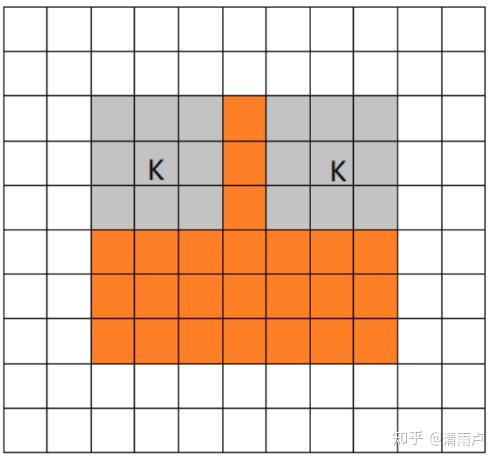
当filter全部在image里面的时候,进行卷积运算,可见filter的移动范围较same更小了。
5.交叉熵与softmax
5.1 数学原理
交叉熵刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。假设概率分布p为期望输出(标签),概率分布q为实际输出,H(p,q)为交叉熵。
第一种交叉熵损失函数的形式:
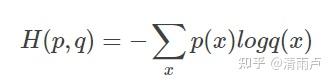
第二种交叉熵损失函数的形式:
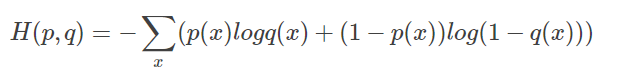
5.2 交叉熵不适用于回归问题
当MSE和交叉熵同时应用到多分类场景下时,(标签的值为1时表示属于此分类,标签值为0时表示不属于此分类),MSE对于每一个输出的结果都非常看重,而交叉熵只对正确分类的结果看重。例如:在一个三分类模型中,模型的输出结果为(a,b,c),而真实的输出结果为(1,0,0),那么MSE与cross-entropy相对应的损失函数的值如下:
MSE:
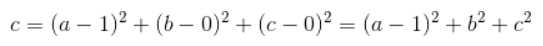
cross-entropy:
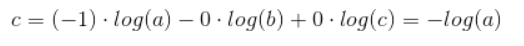
从上述的公式可以看出,交叉熵的损失函数只和分类正确的预测结果有关系,而MSE的损失函数还和错误的分类有关系,该分类函数除了让正确的分类尽量变大,还会让错误的分类变得平均,但实际在分类问题中这个调整是没有必要的。但是对于回归问题来说,这样的考虑就显得很重要了。所以,回归问题熵使用交叉上并不合适。
5.3 交叉熵与softmax
交叉熵损失函数经常用于分类问题中,特别是神经网络分类问题,由于交叉熵涉及到计算每个类别的概率,所以在神经网络中,交叉熵与softmax函数紧密相关。在神经网络中,Softmax通常作用于分类模型最后的输出,将分类结果归一化为(0,1)区间,表示各分类结果的概率。它的函数形式为:
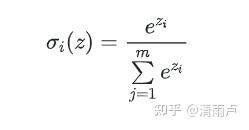
1)为什么softmax分母是所有类别的加权和?
归一化操作,将输入映射为(0,1)之间的概率值。
2)为什么要引入指数形式?
如果使用max函数,虽然能完美的进行分类但函数不可微从而无法进行训练,引入以 e 为底的指数并加权归一化,一方面指数函数使得结果将分类概率拉开了距离,另一方面函数可微。
3)为什么不用2、4、10等自然数为底而要以 e 为底呢?
主要是以e为底在求导的时候比较方便。
参考:https://www.jianshu.com/p/1536f98c659c
6. 激活函数的意义
激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。
Sigmoid
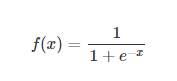
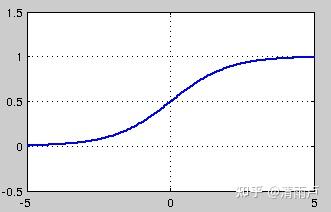
可以被表示作概率,或用于输入的归一化。
sigmoid函数连续,光滑,严格单调,以(0,0.5)中心对称,是一个非常良好的阈值函数。
Sigmoid函数的导数是其本身的函数,即f′(x)=f(x)(1−f(x)),计算非常方便,也非常节省计算时间。
【补充:
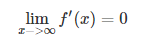
具有这种性质的称为软饱和激活函数。具体的,饱和又可分为左饱和与右饱和。与软饱和对应的是硬饱和, 即 f′(x)=0,当|x|>c,其中c为常数。f′(x)=0,当|x|>c,其中c为常数。】
一旦输入落入饱和区,f′(x)f′(x) 就会变得接近于0,导致了向底层传递的梯度也变得非常小。此时,网络参数很难得到有效训练。这种现象被称为梯度消失。
此外,sigmoid函数的输出均大于0,使得输出不是0均值,这称为偏移现象,这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。
tanh
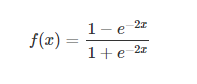
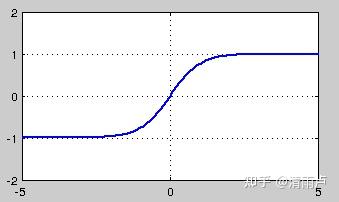
tanh也是一种非常常见的激活函数。与sigmoid相比,它的输出均值是0,使得其收敛速度要比sigmoid快,减少迭代次数。然而,从途中可以看出,tanh一样具有软饱和性,从而造成梯度消失。
tanh 的导数为 1-(tanh(x))2
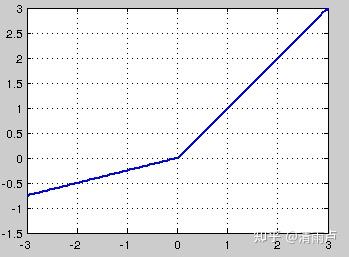
RELU
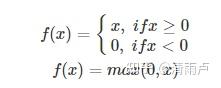
当x<0时,ReLU硬饱和,而当x>0时,则不存在饱和问题。所以,ReLU 能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。
然而,随着训练的推进,部分输入会落入硬饱和区,导致对应权重无法更新。这种现象被称为“神经元死亡”。与sigmoid类似,ReLU的输出均值也大于0,偏移现象和 神经元死亡会共同影响网络的收敛性。针对在x<0的硬饱和问题,Leaky-ReLU对ReLU做出相应的改进,使得
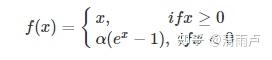
7. pooling有什么意义,和卷积有什么区别
1、降维减少计算量和内存消耗
2、增大深层卷积的感受野
3、压缩特征图,提取主要特征
反向传播
设卷积核尺寸为p x q, 步长为t,为保证整除,填充后的X是m x n 矩阵, 经MaxPooling 卷积得到g x h矩阵Y, 前向传播得到误差值error(标量e)。上游的误差梯度向量
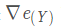
已在反向传播时得到, 求 e 对 X 的梯度.
已知 :
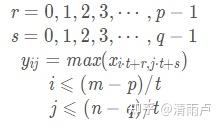
e=forward(Y)
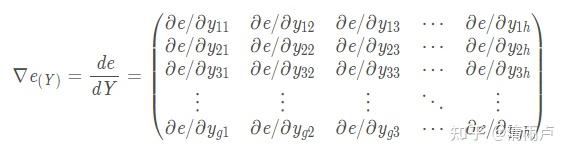
其中:
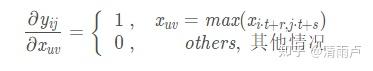
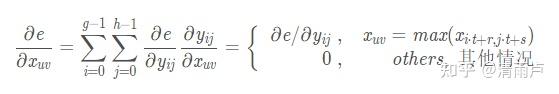
其中,
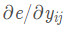
由上游计算得出。
参考:https://www.nowcoder.com/discuss/371584
https://www.nowcoder.com/tutorial/95/ea84cef4fb2c4555a7a4c24ea2f6b6e8
https://blog.csdn.net/oBrightLamp/article/details/84635346
8.泛化误差(过拟合)
训练误差与泛化误差:
训练误差:
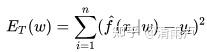
泛化误差:
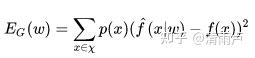
泛化误差表达模型的泛化能力,可以理解为样本误差的期望,p(x)为表示全集合X中x出现的概率(x可以是一个样本,也可以是一个集合)
训练误差只能代表选定的部分数据的误差,但泛化误差能考虑到全数据集。
泛化误差分解:
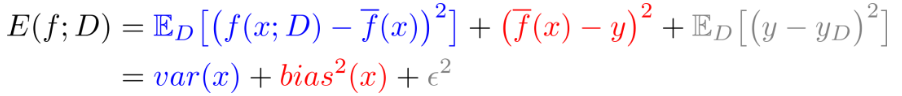
即泛化误差 = 方差 + 偏差 + 噪声
1,噪声是模型训练的上限,也可以说是误差的下限,噪声无法避免。
2,方差表示不同样本下模型预测的稳定程度(方差大其实就是过拟合,预测不稳定)
3,偏差表示模型对训练数据的拟合程度 (偏差大就是欠拟合,预测效果不好)
训练过程中方差和偏差此消彼涨
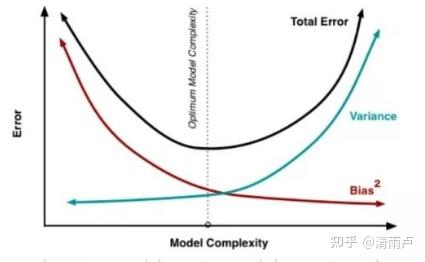
降低方差的方法:(其实就是防止过拟合)
数据:1,增大数据量,进行数据增强
2,进行数据清洗(纠正错误数据)
3,进行特征选择,降低特征维度
4,类别平衡(欠采样、过采样)
网络结构:1,正则化L1,L2, BN 2,dropout
宏观:1,选择合适复杂度的模型,或对已有模型进行剪枝、删减
2,集成学习(Ensemble)
3,限制训练
降低偏差的方法:(防止欠拟合)
输入: 优化特征,检查特征工程是否有漏掉的具有预测意义的特征
网络中间:削弱或者去除已有的正则化约束
宏观:1,增加模型复杂度, 2,集成学习(Ensemble) 3,增大训练轮数
*注:集成学习可以同时降低方差与偏差
参考 https://www.sohu.com/a/317862976_654419
https://www.zhihu.com/question/27068705/answer/137487142?utm_source=wechat_session&utm_medium=social&utm_oi=929368776753954816
9. LR相关
- 手推
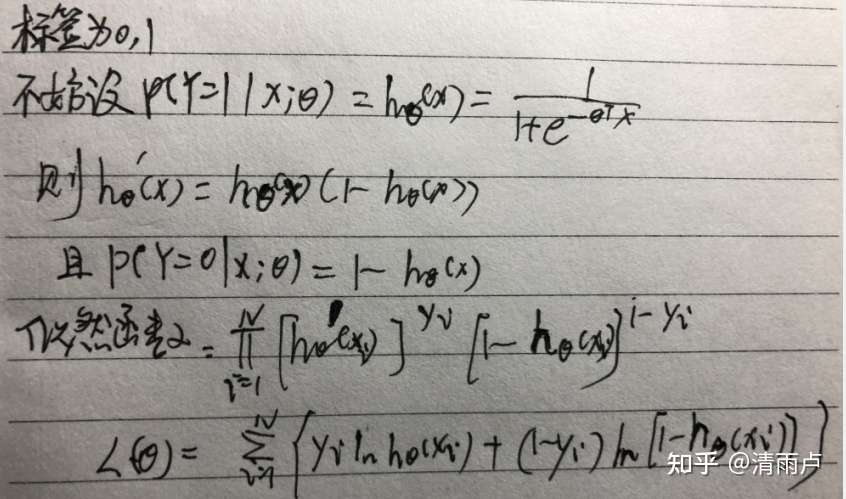
zhx:


最大似然<-> 最小化损失
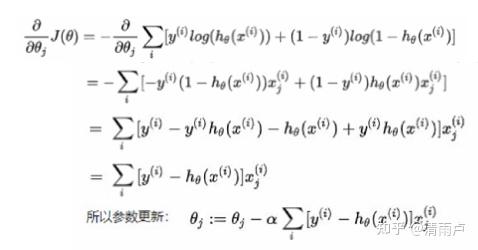
- 优缺点
- 优点:
- 参数代表每个特征对输出的影响,可解释性强
- 简单,计算量小、存储占用低,可以在大数据场景中使用
- 缺点
- 容易欠拟合,精度不高
- 对异常值比较敏感
- LR如何解决低维不可分:通过核函数将特征把低维空间转换到高维空间,在低维空间不可分的数据,到高维空间中线性可分的几率会高一些
- 怎么防止过拟合:L1正则与L2正则
10. SVM
- 基本原理、意义(4)
SVM需要找到一个超平面,将所有的样本点都正确分类,并且其与所有样本点的几何间隔最大化;通过变换可以将其化为凸二次规划问题,是一个带有不等式约束的求最小值的问题。二次规划问题可以直接解,但通常的做法是利用拉格朗日乘子法去解它的对偶问题,解法如 SMO;而根据其所需满足的 KKT 条件,可以知道该解仅和几何间隔最小的那部分样本有关,这些样本就叫支持向量。
- 软间隔、损失函数(3)
- 核函数列举、选择(3)
- 为什么用对偶函数(2)
- SVM与LR (2)
基本原理与推导
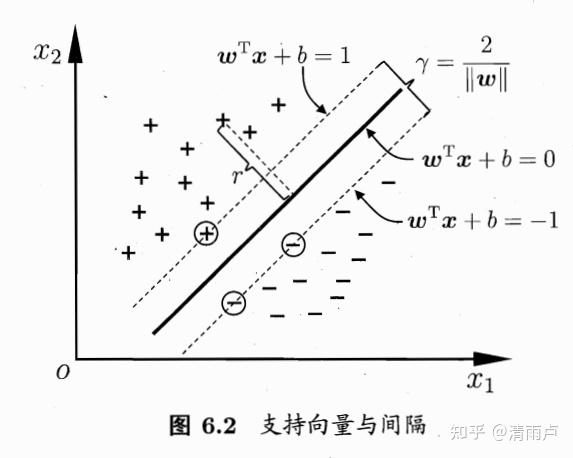
点到超平面的距离:
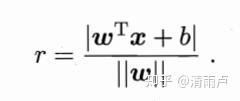
令(样本确定后,最优的r就固定了,可以通过改变分母来调整分子的大小,得出下式)
:
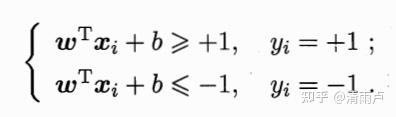
最大化r,也就是最小化下式 (约束中有不等式,需要满足KKT条件):
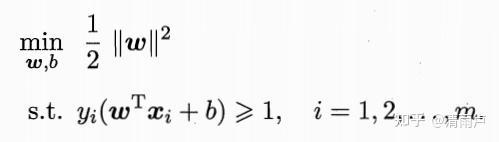

KKT条件:乘子、约束、约束*乘子:
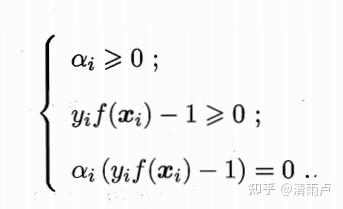
必有:
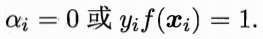
前者表明样本无影响,后者表明样本是支持向量。
核函数:
当样本是线性不可分的时候,需要将其特征映射到高维空间,使其线性可分;而在解对偶问题时涉及到两个样本的内积运算,直接在高维空间计算太困难;因此引入核函数,其值等于样本在高维空间的内积,就能在低维空间计算。
核函数的作用:
- 将特征空间从低维映射到高维,使得原本线性不可分的问题变为线性可分。
- 使用核函数计算,避免了在高维空间中进行复杂计算,且不影响其效果。
常见的核函数如下:

核函数的选择:
- 样本特征较多、维数较高、线性可分时,通常采用线性核。
- 样本特征较少,样本数适中、线性不可分、情况不明时可先尝试高斯核。高斯核参数较多,结果对参数的敏感性较高,通过交叉验证可以寻找到合适的参数,但比较耗时
软间隔与损失函数:
现实任务中很难确定核函数是否使得样本线性可分了(即便找到了某个核函数使得样本线性可分,也不能保证它不是过拟合产生的结果。)。
软间隔意味着SVM允许部分样本不满足约束条件,即不要求所有样本都被正确分类。
此时,优化目标为:
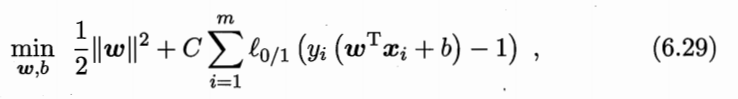
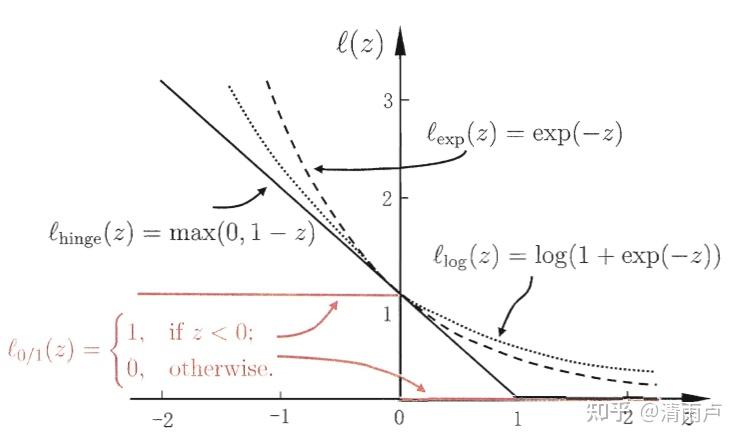
式中的后一项表示被错误分类的数目,C是权重,单纯的0/1损失显然不好用,于是引入替代的损失函数,常见如下:
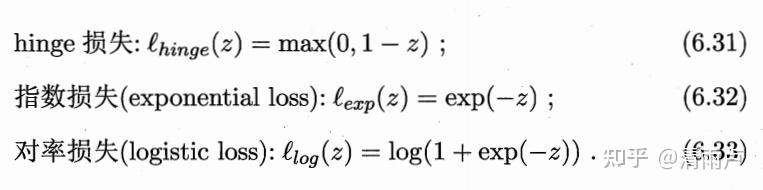
11. 约束优化问题的对偶问题


参考链接:https://www.bilibili.com/video/BV1Hs411w7ci
对偶性的几何解释:

d* <= p* (弱对偶性)
凸优化+Slater条件 => d* = p*
充分非必要
参考链接https://www.bilibili.com/video/BV1aE411o7qd?p=33
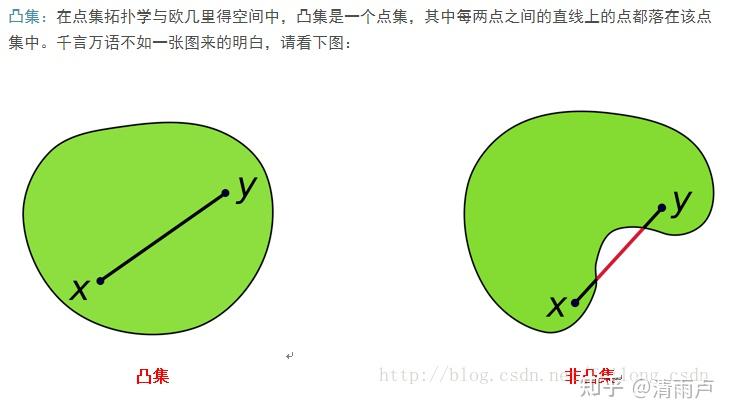
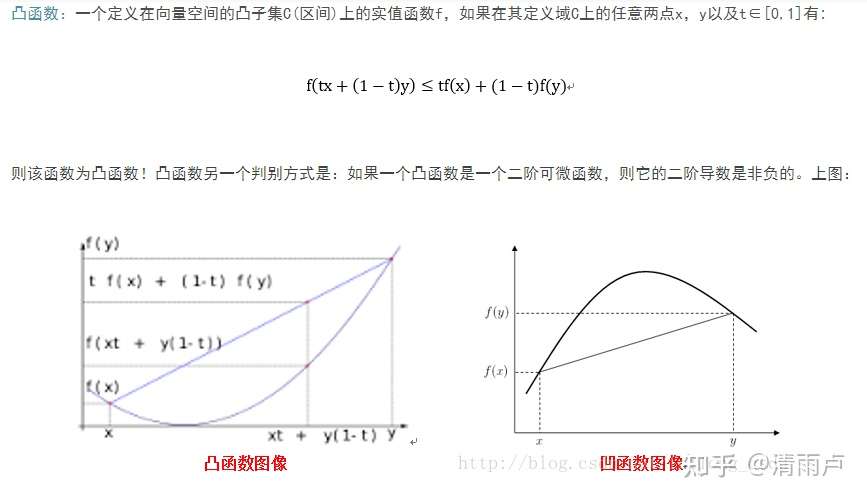

凸优化(百科):凸优化是指一种比较特殊的优化,是指求取最小值的目标函数为凸函数的一类优化问题。其中,目标函数为凸函数且定义域为凸集的优化问题称为无约束凸优化问题。而目标函数和不等式约束函数均为凸函数,等式约束函数为仿射函数,并且定义域为凸集的优化问题为约束优化问题。

仿射函数:仿射函数即由由1阶多项式构成的函数,一般形式为f(x)=Ax+b,其中的特例是,函数f(x)=ax+b,其中a、x、b都是标量。此时严格讲,只有b=0时,仿射函数才可以叫“线性函数”(“正比例”关系)。
Slater条件:
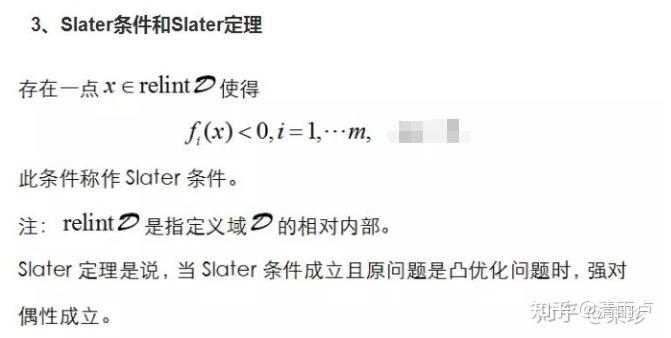
relint:relative interior,除去边界的定义域
- 对于大多数凸优化,slater条件成立。
有时候在定义域内部求fi(x)是否<0比较困难
- 放松的slater:m中有k个仿射函数,那么只检查剩下m-k个是否满足条件。
SVM天生:凸二次优化+slater条件 => 强对偶性(p*=d*) <=> KKT条件
KKT条件:
原问题如下,其最优解p*
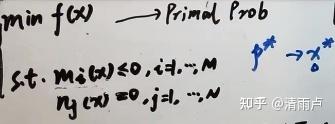
其对偶问题,最优解d*

KKT条件:给定了x*,λ*,η*求解关系。
- 梯度为0,L`=0
- 原问题可行条件, mi(x)<=0, nj(x)=0
- 对偶问题可行,λi>=0
- 互补松弛条件:λi * mi=0
互补松弛条件和梯度=0条件推导。

参考资料:https://zhuanlan.zhihu.com/p/58064316
https://www.bilibili.com/video/BV1aE411o7qd?p=34
https://blog.csdn.net/feilong_csdn/article/details/62427148
11.Dropout
背景:为了减轻过拟合问题,2012年Hintion在论文中提出Dropout方法
原理:1,前向传播时按概率p随机关闭神经元(每个neuron, 有p%的可能性被去除;(注意不是去除p比例的神经元),本次反向传播时,只更新未关闭的神经元
2,下一次训练时,恢复上一轮被更新的神经元,然后重复操作1

其中,Bernoulli函数是为了生成概率r向量,也就是随机生成一个0、1的向量
训练与测试:
测试时需要关闭dropout,否则仍然按概率抛弃神经元会导致网络不稳定,即同一样本多次预测结果不同。
但若什么处理都不做,会导致训练与测试结果不同。
为了平衡训练与测试的差异,可以采取使得训练与测试的输出期望值相等的操作:
[补]:
1,训练时除以p:假设一个神经元的输出激活值为a,在不使用dropout的情况下,其输出期望值为a,如果使用了dropout,神经元就可能有保留和关闭两种状态,把它看作一个离散型随机变量,它就符合概率论中的0-1分布,其输出激活值的期望变为 p*a+(1-p)*0=pa,此时若要保持期望和不使用dropout时一致,就要除以 p
2, 测试时乘p
为什么可以减轻过拟合?
1,ensemble效果:训练过程中每次随机关闭不同的神经元,网络结构已经发生了改变,整个dropout的训练过程就相当于很多个不同的网络取平均,进而达到ensemble的效果。
2,减少神经元之间复杂的共适应关系:dropout导致每两个神经元不一定每一次都在网络中出现,减轻神经元之间的依赖关系。 阻止了某些特征仅仅在其它特定特征下才有效果的情况,从而迫使网络无法关注特殊情况,而只能去学习一些更加鲁棒的特征。
BN和Dropout共同使用出现的问题
Dropout为了平衡训练和测试的差异,会通过随机失活的概率来对神经元进行放缩,进而会改变其方差。如果再加一层BN,又会将方差拉回至(0-1)分布,进而产生方差冲突。
处理方法:1,始终将Dropout放在BN后 2,使用高斯Dropout
参考 https://zhuanlan.zhihu.com/p/38200980
https://blog.csdn.net/songyunli1111/article/details/89071021
12. 评价指标

1,准确率和召回率(虚警和漏报)
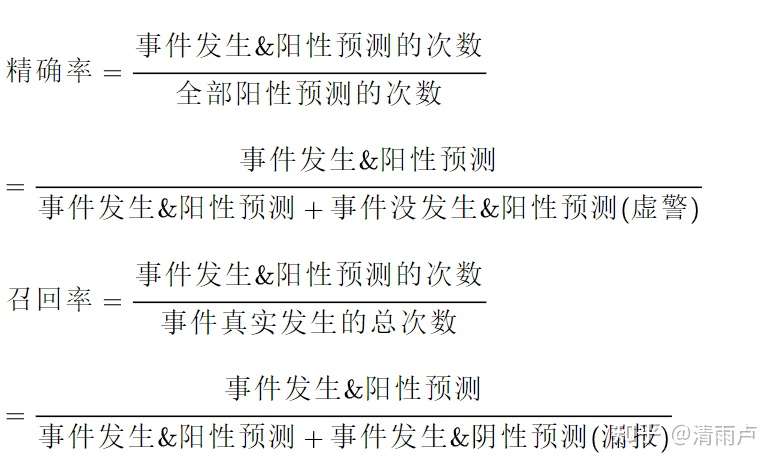
准确率为预测阳性的病人中真正为阳性的概率
召回率等价于敏感度,即有病的人中被检测到有病的概率(有病且被召回的概率)
4、PR曲线与F1值:纵轴为精确率P,横轴为召回率R
PR曲线围成面积越大越好,但:

5、ROC曲线与AUC值:纵轴为真阳性率TPR,横轴为假阳性率FPR
真阳性率(true positive rate,TPR),又称敏感度 正样本被预测为正样本的概率
假阳性率:无病,但根据筛检被判为有病的百分比
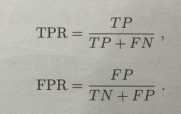
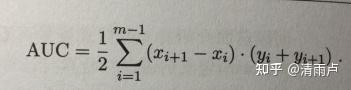
6、怎么形成曲线:分类阈值α的调整形成
7、PR和ROC曲线应用场景对比:

13.正则化L1,L2
1、什么是正则化
正则化就是一类通过显式设计降低泛化误差,以提升算法通用性的策略的统称。从概率论角度看,许多正则化技术对应的是在模型参数上施加一定的先验分布,其作用是改变泛化误差的结构。正则化在经验风险最小化的基础上(也就是训练误差最小化),尽可能采用简单的模型,可以有效提高泛化预测精度。如果模型过于复杂,变量值稍微有点变动,就会引起预测精度问题。正则化之所以有效,就是因为其降低了特征的权重,使得模型更为简单。
2、L1正则化
而L1正则项就是一个L1范数,即相当于为模型添加了这样一个先验知识:w 服从零均值拉普拉斯分布。
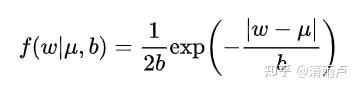
由于引入了先验知识,所以似然函数这样写:
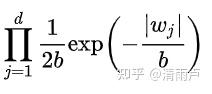
取 log 再取负,得到目标函数:
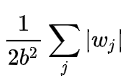
3、L2正则化
L2正则项就是一个L2范数,即Ridge 回归,相当于为模型添加了这样一个先验知识:w 服从零均值正态分布。
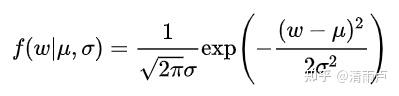
类似的,似然函数为:
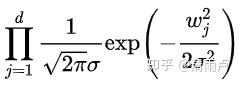
目标函数为:
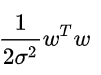
,即L2范数
4、L1和L2正则化的区别
L1 正则化增加了所有权重 w 参数的绝对值之和逼迫更多 w 为零,也就是变稀疏,L2 正则化中增加所有权重 w 参数的平方之和,逼迫所有 w 尽可能趋向零但不为零(L2 的导数趋于零)。
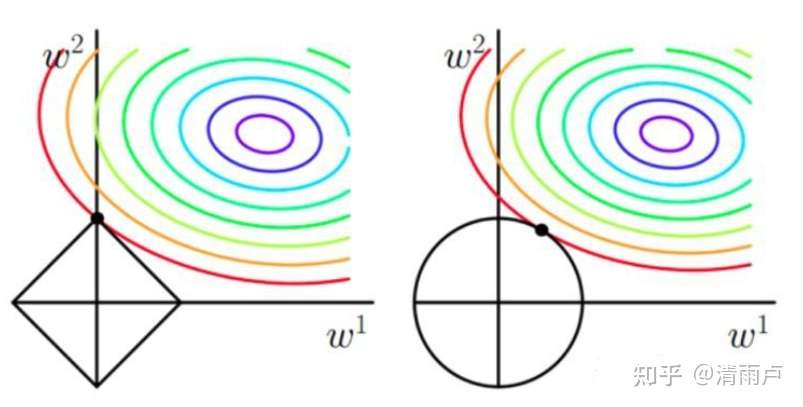
5、总结
给 loss function 加上正则化项,能使新得到的优化目标函数 h=f+||w|| ,需要在 f 和 ||w|| 中做一个权衡,如果还像原来只优化 f 的情况下,那可能得到一组解比较复杂,使得正则项 ||w|| 比较大,那么 h 就不是最优的,因此可以看出加正则项能让解更加简单,符合奥卡姆剃刀理论,同时也比较符合在偏差和方差(方差表示模型的复杂度)分析中,通过降低模型复杂度,得到更小的泛化误差,降低过拟合程度。
L1 正则化就是在 loss function 后边所加正则项为 L1 范数,加上 L1 范数容易得到稀疏解(0 比较多)。L2 正则化就是 loss function 后边所加正则项为 L2 范数的平方,加上 L2 正则相比于 L1 正则来说,得到的解比较平滑(不是稀疏),但是同样能够保证解中接近于 0(但不是等于 0,所以相对平滑)的维度比较多,降低模型的复杂度。
- 缩小参数空间
- 防止过拟合
- 加先验知识
- 使得求解变得可行(比如样本较少时候OLS的逆矩阵求解)
不用L0正则化的原因
根据上面的讨论,稀疏的参数可以防止过拟合,因此用L0范数(非零参数的个数)来做正则化项是可以防止过拟合的。
从直观上看,利用非零参数的个数,可以很好的来选择特征,实现特征稀疏的效果,具体操作时选择参数非零的特征即可。但因为L0正则化很难求解,是个NP难问题,因此一般采用L1正则化。L1正则化是L0正则化的最优凸近似,比L0容易求解,并且也可以实现稀疏的效果。
不正则化参数b的原因
如果对||b||进行惩罚,其实是没有作用的,因为在对输出结果的贡献中,参数b对于输入的改变是不敏感的,不管输入改变是大还是小,参数b的贡献就只是加个偏置而已。举个例子,如果你在训练集中,w和b都表现得很好,但是在测试集上发生了过拟合,b是不背这个锅的,因为它对于所有的数据都是一视同仁的(都只是给它们加个偏置),要背锅的是w,因为它会对不同的数据产生不一样的加权。
6、稀疏与平滑
f(x) = b + w1x1+w2x2+w3x3+...
- 稀疏
对于模型而言,稀疏指的是模型中的参数有较少的非零值,其作用有:
- 去掉冗余特征,使模型更简单,防止过拟合
- 降低运算量,防止维度爆炸
L1正则化 与 Relu 都能带来稀疏性。
对于样本而言,稀疏指的是样本中存在较多的特征值缺失或为零(文本数据通常是稀疏表示的),也叫作样本的稀疏表示。
稀疏表示的样本可以使得其数据集线性可分,使用SVM方法时能够有很好的性能,并且稀疏矩阵的已经有高效的存储方式,并不会带来额外的负担。
Adagrad 适合处理稀疏数据的原因:
Adagrad 中每个参数的学习率:
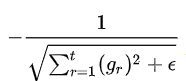
假设有10000个样本,其中有9900个样本的特征 x1 的值为0,这就是稀疏的数据。
那么在更新时,x1 的参数 w1 有 9900 次其更新梯度都是 0,仅有 100 次更新梯度非零。假如没有使用 Adagrad,其学习率没有针对过往梯度和做比例调整,那么10000个样本中仅有这100次更新是有效的,相对于非稀疏特征,其收敛速度大减,而使用 Adagrad 后,学习率会被放大,虽然仅有100次更新,但是能够大大加快收敛速度。
- 平滑
平滑是指模型中的参数都比较小,其函数图像看起来比较平滑,而非陡峭,作用是使模型对样本特征值(也就是 x)的变化不敏感,防止过拟合。
【补】
7、使用场景:
需要对特征进行筛选的场景,那我们可以选择L1正则
L2可让所有特征的系数都缩小,但是不会变成零,会使得优 求解稳定快速;
有些应用场景,也会把L1和L2联合起来使用
8、如何解决L1求导困难:坐标下降法

9、坐标下降法缺点:可能会调到局部最优而不是全局最优
14.权重初始化
是否可以将权重初始化为0?
背景:对于简单的网络可以直接随机初始化
但对于深层网络而言,参数如果初始化不合适,就有可能导致输出结果分布在梯度过大或过小的位置,那么经过层层叠加之后就容易发生梯度消失或梯度爆炸的问题。
几种初始化:
- pretraining
- raddom initialization, 但若所选分布不当,也会影响收敛
eg,10层网络,激活函数为tanh
a,随机初始化为均值为0,方差为0.1
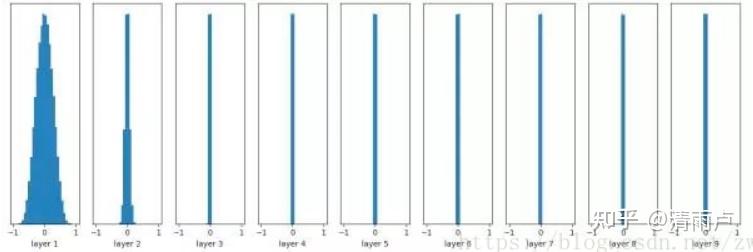

b,随机初始化为均值0,方差1
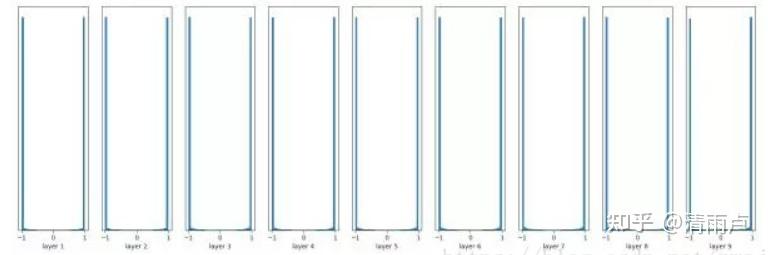
- Xavier Initialization(其实就是rescale 标准0,1正态分布)
2010年Xavier Glorot提出一般情况下,激活值的方差是逐层衰减的,反向传播梯度也逐层递减。要避免梯度消失,就是要避免激活值方差的衰减。如果能保证每层网络的输入和输出分布保持一致,就perfect了,
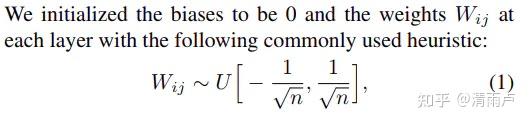
推导:

- Kaiming Initialization
但Xavier假设网络中没有激活函数,或者为线性激活函数,若使用Relu,输出值依旧会跑偏。
对于Relu函数,若激活前均值为0,那么激活后抛弃掉小于0的值,均值会增大,进而不满足Xavier关于均值为0的前提。
何凯明经过推导得出rescale系数应改成
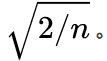
15. 决策树
15.1 原理
决策树(decision tree) 是一类常见的机器学习方法.一般的,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点,叶结点对应于决策结果,其他每个结点则对应一个属性测试;每个结点包含的样本集合根据属性测试的结果被划分到子结点中;根结点包含样本全集.从根结点到每个叶结点的路径对应了一个判定测试序列。
根据不同的划分方式,衍生出多种不同类型的决策树方法。ID3和C45算法均为悉尼大学校友发明,这一点十分关键。
15.2 ID3
信息熵:"信息熵" (information entropy)是度量样本集合纯度最常用的一种指标.假定当前样本集合D 中第k 类样本所占的比例为Pk (k = 1, 2,. . . , |Y|) ,则D信息熵定义为
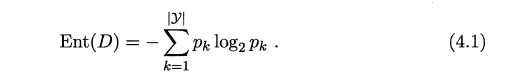
Ent(D) 的值越小,则D 的纯度越高.
信息增益:
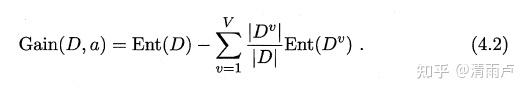
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的"纯度提升"越大。
15.3 C4.5
C45是在ID3算法之上的一个改进。ID3算法有几点不不足:
(1)不能处理连续特征;
(2)使用信息增益作为标准容易偏向于取值较多的特征;
(3)缺失值处理问题;
(4)过拟合问题;
因此C45的出现解决了这个问题。
增益率(又叫信息增益比):
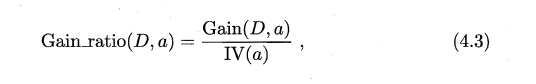
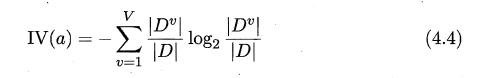
其中的IV(a)表示的是特征熵,V为特征a的类别数量面,意思是将所有的特征都加权做一个log的计算。特征越多,特征熵就越大,信息增益率就越小。
需注意的是,增益率准则对可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的.(重点:我们选取的是信息增益率越大越好,和ID3一样,也是信息增益越大越好)
15.4 CART决策树
"基尼指数" (Gini index):
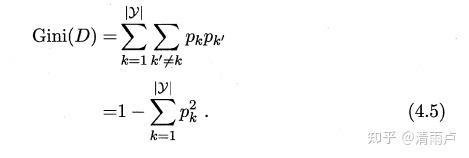
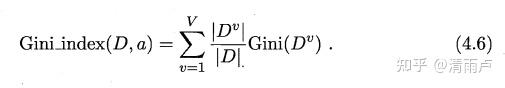
我们在候选属性集合A 中,选择那个使得划分后基尼指数最小的属性作为最优划分属性(基尼指数最小的座作为最优的划分属性,和ID3 ,C45相反)
15.5 剪枝处理o
预剪枝:生成树时对某一节点的划分用验证集对比精度,没提高则剪枝。预剪枝降低了过拟合,但基于贪心的本质禁止这些分支展开,有欠拟合的风险。
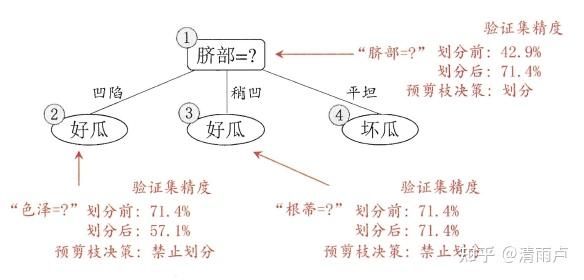
后剪枝:生成完整决策树后,自底向上判断结点剪枝与否在验证集精度是否提高。
一般情形下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树,但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中的所有非叶结点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多。
15.6 连续值处理(回归树)
一般选用相邻连续值的中点作为候选划分点,判断最优点进行划分。且与离散属性不同,若当前结点划分属性为连续属性,该属性还可作为其后代结点的划分属性。
15.7 缺失值处理
- 如何在属性值缺失的情况F进行划分属性选择?
推广的信息增益公式:
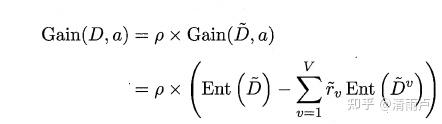
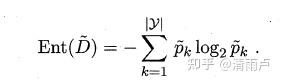
- 给定划分属性?若样本在该属性上的值缺失,如何对样本进行划分?
若样本x划分属性a上的取值己知,则将x划入与其取值对应的子结点,且样本权值在于结点中保持为ω. 若样本x在划分属性a上的取值未知,则将x同时划入所有子结点,且样本权值在与属性值a_v对应的子结点中调整为凡ω·r_v。
15.8 多变量决策树
使用多变量将每一个非叶结点用一个线性分类器进行划分。
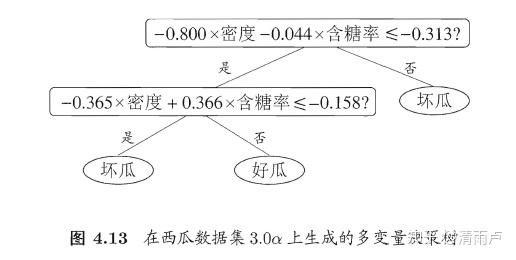
15.9 LR、决策树、SVM的选择与对比
逻辑回归的优点:
- 便利的观测样本概率分数;
- 已有工具的高效实现;
- 对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决;
- 逻辑回归广泛的应用于工业问题上(这一点很重要)。
逻辑回归的缺点:
- 当特征空间很大时,逻辑回归的性能不是很好;
- 不能很好地处理大量多类特征或变量;
- 对于非线性特征,需要进行转换;
- 依赖于全部的数据(个人觉得这并不是一个很严重的缺点)。
决策树的优点:
- 直观的决策规则
- 可以处理非线性特征
- 考虑了变量之间的相互作用
决策树的缺点:
- 训练集上的效果高度优于测试集,即过拟合[随机森林克服了此缺点]
- 没有将排名分数作为直接结果
SVM的优点:
- 能够处理大型特征空间
- 能够处理非线性特征之间的相互作用
- 无需依赖整个数据
SVM的缺点:
- 当观测样本很多时,效率并不是很高
- 有时候很难找到一个合适的核函数
何时选择这三种算法,流程如下:
首当其冲应该选择的就是逻辑回归,如果它的效果不怎么样,那么可以将它的结果作为基准来参考;然后试试决策树(随机森林)是否可以大幅度提升模型性能。即使你并没有把它当做最终模型,你也可以使用随机森林来移除噪声变量;如果特征的数量和观测样本特别多,那么当资源和时间充足时,使用SVM不失为一种选择。
`
参考: 机器学习,第四章 周志华 (本节1-8点)
https://blog.csdn.net/weixin_41712499/article/details/88149170 (本节9点)
16. Boosting vs Bagging
- Boosting vs Bagging (3)
Bagging和Boosting的区别:
1)样本选择上:Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:Bagging:使用均匀取样,每个样例的权重相等。Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:Bagging:所有预测函数的权重相等。Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:Bagging:各个预测函数可以并行生成。Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
- XGBoost、AdaBoost、 GBDT (2)
- 决策树、GBDT、XGBoost 区别与联系
https://blog.csdn.net/quiet_girl/article/details/88756843
- XGBoost (5)
16.1 集成学习
结合多个“好而不同”的学习器,来获得优于单一学习器的泛化性能。
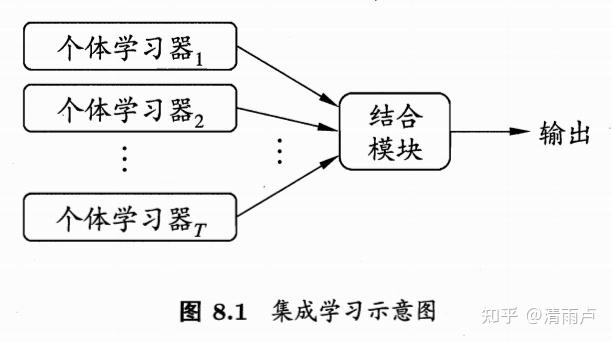
学习器之间应“好而不同”,“好而同”则集成不起作用,“坏而不同”则起副作用。(“好”可以理解为至少优于随机瞎猜)

16.2 Boosting
个体学习器之间存在强依赖关系,串行生成。
主要关注减低偏差,可以将弱分类器提升为强分类器。
先从原始训练集训练得到一个基学习器,再提高对错误样本的权重比例,使用新的样本分布来重新训练学习器,重复进行T次,最终将T个学习器加权结合。
AdaBoost

16.3 Bagging
通过自助采样法得到T个互有交集的训练集,基于每个训练集训练出基学习器,最后结合。Bagging在最后结合时,通常对分类任务做简单投票法,对回归任务做简单平均法。
由于每个学习器使用的样本都只是原始训练集的一个子集(约有63.2% 的样本),所以剩下的样本可以用作验证集,来对泛化性能做“包外估计”。
Bagging的复杂度与训练一个学习器的复杂度同阶(可以简单看做O(Tn),T是一个不大的常数)
主要关注降低方差,在不剪枝决策树、神经网络等易受样本扰动的学习器上效用明显。

16.4从减小偏差和方差来解释Boosting和Bagging
Bagging:减小方差
Bagging就是对数据随机采样,训练若干基分类器,对所有基分类器取平均。
假设n个基分类器,方差为σ2,若两两相互独立,则取平均后的方差为σ2/n。但模型之间不可能完全独立,假设模型之间的相关性为p,则取平均后的方差为:
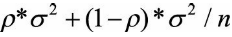
可以看出,相关性越低,方差越小。
因此,bagging时要尽可能降低模型之间的相关性:
- 随机森林算法中,每次选取节点分裂属性时,会随机抽取一 个属性子集,而不是从所有属性中选取最优属性
- 训练集的重采样
Boosting:减小偏差
Boosting在训练好一个弱分类器后,我们需要计算弱分类器的错误或者残差,作为下一个分类器的输入。 学习过程中不断减小损失函数,使模型不断逼近靶心。
可以看出,此时基分类器之间强相关,所以不会显著降低方差。
16.5 随机森林(RF)
随机选取样本+特征
是Bagging的扩展变体,在以决策树为基学习器的Bagging集成上,在决策树的训练过程中引入随机属性选择(原本是选择最优的属性,改为先随机选择k个属性,再从中选择最优属性,推荐值 k=log2d, d为属性数)。
相比Bagging的多样性仅来自于样本扰动,RF还增加了属性扰动,进一步提升学习器之间的差异性,从而提升泛化性能。
随机森林简单、易实现、计算开销小,实现效率比Bagging还低(每次属性选择时只考虑了子集,而非全集。)
17.优化算法
在机器学习算法中,对于很多监督学习模型,需要对原始的模型构建损失函数,之后通过优化算法对损失函数进行优化,寻找到最优的参数。求解机器学习参数的优化算法中,使用较多的是基于梯度下降的优化算法(Gradient Descent, GD)。
梯度下降法的含义是通过当前点的梯度方向寻找到新的迭代点。
基本思想可以这样理解:我们从山上的某一点出发,找一个最陡的坡走一步(也就是找梯度方向),到达一个点之后,再找最陡的坡,再走一步,直到我们不断的这么走,走到最“低”点(最小花费函数收敛点)。
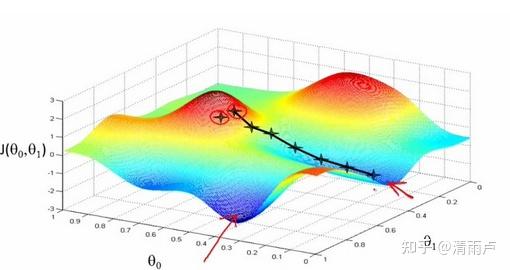
梯度下降法的变形形式
- 批量梯度下降法 (Batch Gradient Descent)
批梯度下降法(Batch Gradient Descent)针对的是整个数据集,通过对所有的样本的计算来求解梯度的方向。
梯度和参数更新公式如下:
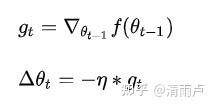
其中,是η学习率,是g_t梯度。
每迭代一步,都要用到训练集所有的数据,如果样本数目很大,这种方法的迭代速度很慢!
优点:理论上讲,可以得到全局最优解,参数更新比较稳定,收敛方向稳定;可以并行实现;
缺点:计算量大,参数更新慢,对内存的要求很高,不能以在线的形式训练模型,也就是运行时不能加入新样本。
从迭代的次数上来看,批量梯度下降法迭代的次数相对较少。其迭代的收敛曲线示意图可以表示如下:
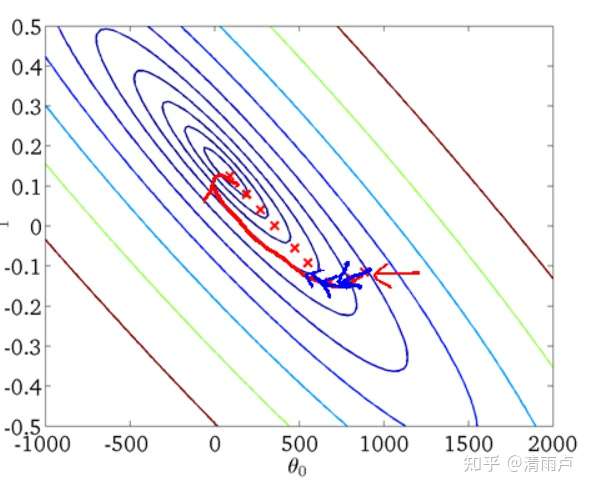
- 随机梯度下降(Stochastic Gradient Descent)
为了加快收敛速度,并且解决大数据量无法一次性塞入内存(显存)的问题,每次只训练一个样本去更新参数,这就是随机梯度下降法。
如果我们的数据集很大,比如几亿条数据, 基本上设置1,2,(10以内的就足够了)就可以。但是SGD也有缺点,因为每次只用一个样本来更新参数,会导致不稳定性大些,每次更新的方向,不像batch gradient descent那样每次都朝着最优点的方向逼近,会在最优点附近震荡)。因为每次训练的都是随机的一个样本,会导致导致梯度的方向不会像BGD那样朝着最优点。
在代码中的随机把数据打乱很重要,因为这个随机性相当于引入了“噪音”,正是因为这个噪音,使得SGD可能会避免陷入局部最优解中。
优点:训练速度快;同时能够在线学习。
缺点:1、参数更新的过程震荡很大,目标函数波动剧烈,参数更新方向有很大的波 动。
2、其较大的波动可能收敛到比批量梯度下降更小的局部极小值,因为会从一个极小值跳出来
3、不易并行实现。
从迭代的次数上来看,SGD迭代的次数较多,在解空间的搜索过程看起来很盲目。其迭代的收敛曲线示意图可以表示如下:
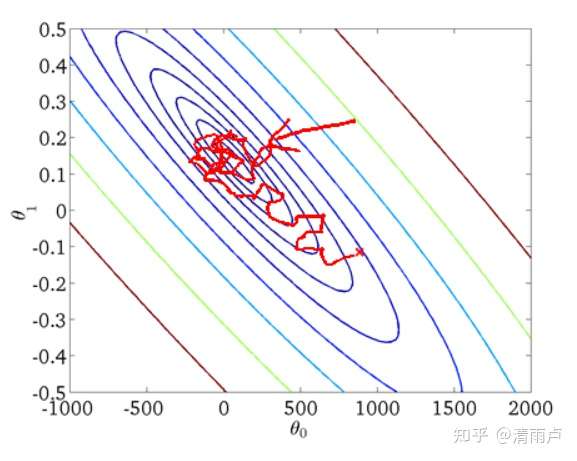
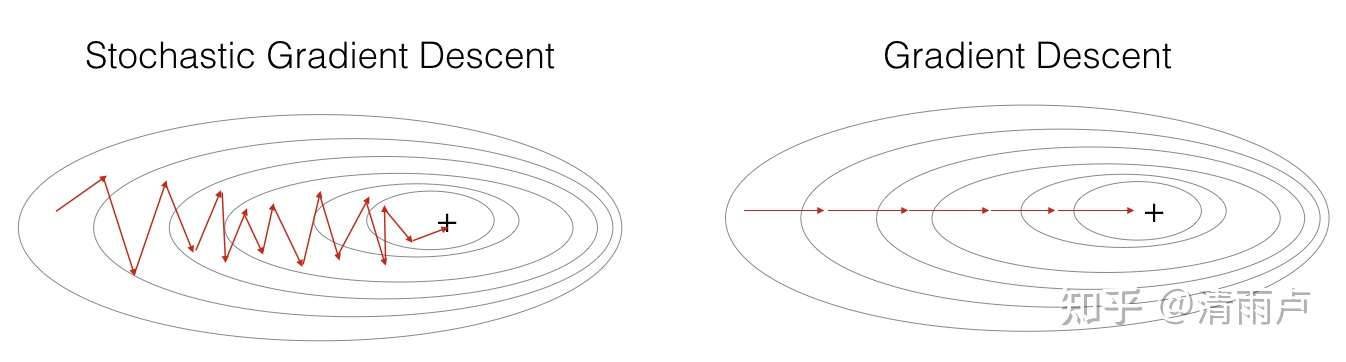
下面来对比下SGD和BGD的代价函数随着迭代次数的变化图:
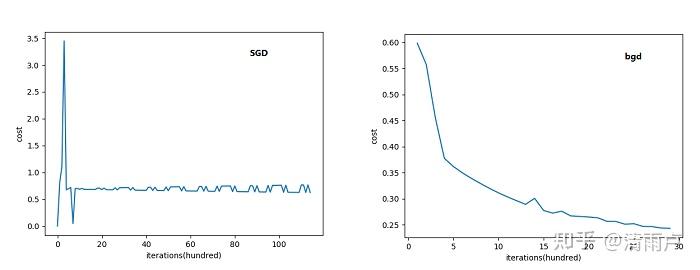
可以看到SGD的代价函数随着迭代次数是震荡式的下降的(因为每次用一个样本,有可能方向是背离最优点的)
- 小批量梯度下降(Mini-Batch Gradient Descent)
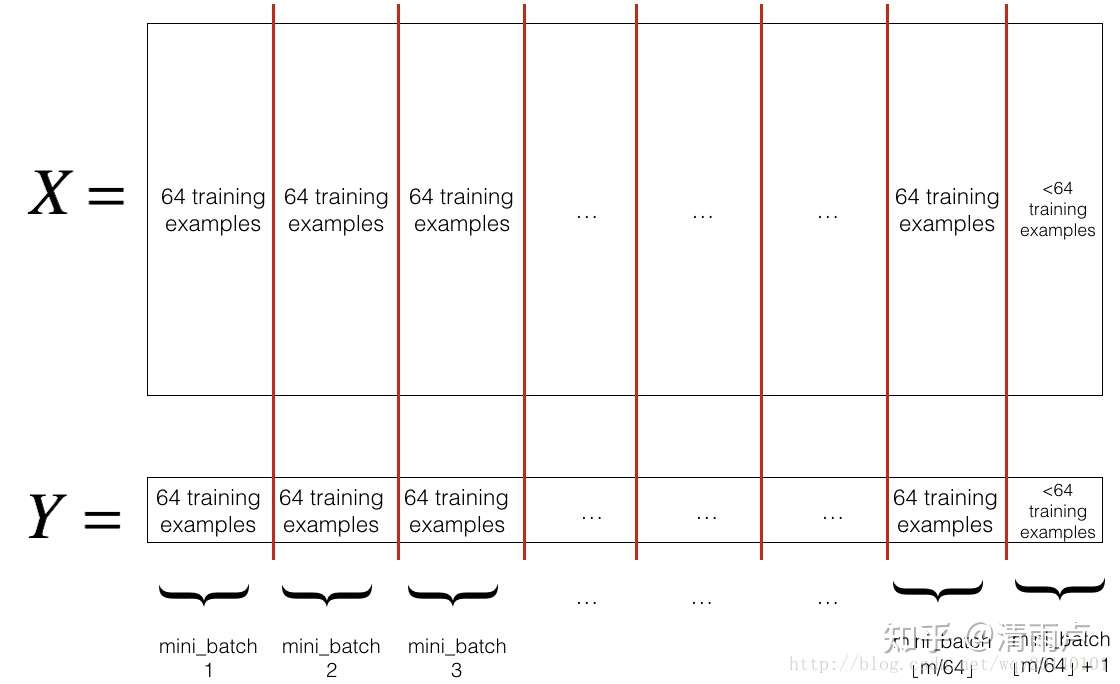
在上述的批梯度的方式中每次迭代都要使用到所有的样本,对于数据量特别大的情况,如大规模的机器学习应用,每次迭代求解所有样本需要花费大量的计算成本。所以出现了mini-batch梯度下降,其思想是:可以在每次的迭代过程中利用部分样本代替所有的样本。batch通常设置为2的幂次方,通常设置(很少设置大于512)。因为设置成2的幂次方,更有利于GPU加速。现在深度学习中,基本上都是用 mini-batch gradient descent,(在深度学习中,很多直接把mini-batch gradient descent(a.k.a stochastic mini-batch gradient descent)简称为SGD,所以当你看到深度学习中的SGD,一般指的就是mini-batch gradient descent)。
假设每个batch有64个样本,如下图所示:
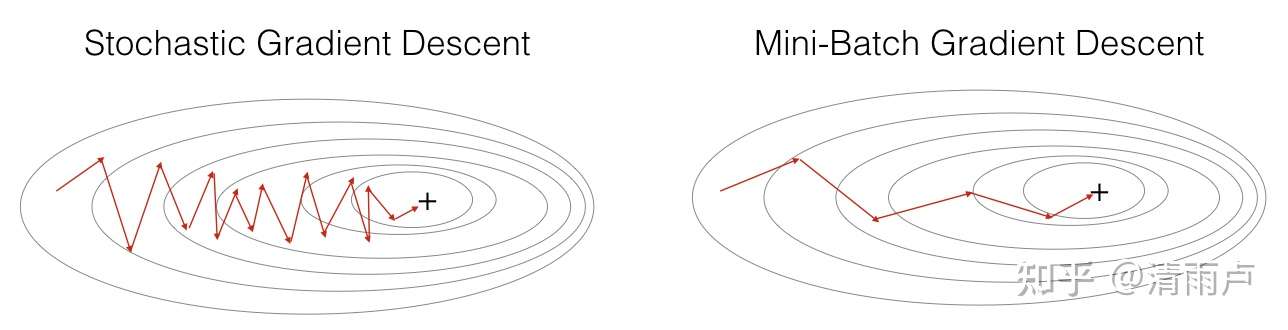
mini-batch gradient descent 和 stochastic gradient descent 在下降时的对比图:
mini-batch gradient descent的代价函数随着迭代次数的变化图:
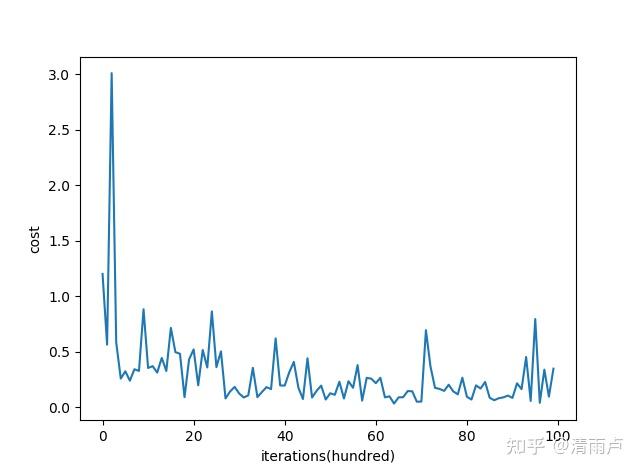
mini-batch gradient descent 相对SGD在下降的时候,相对平滑些。不像SGD那样震荡的比较厉害。mini-batch gradient descent的一个缺点是增加了一个超参数。
优点:1、降低了更新参数的方差,使得收敛过程更加的稳定
2、能够利用高度优化的矩阵运算,很高效的求得每小批数据的梯度
SGD容易收敛到局部最优,并且在某些情况下可能被困在鞍点,【在合适的初始化和step size的情况下,鞍点的影响不是很大。】
【上述梯度下降法方法面临的主要挑战】:
- 选择合适的学习率较为困难,太小的学习率会导致收敛缓慢,太大的学习率导致波动较大,可能跳出局部最小值
目前可采用的方法是在训练过程中调整学习率的大小,
例如模拟退火法:预定义一个迭代次数m,每次执行完m次训练便减小学习率,
或者当损失函数的值低于一个阈值时,减小学习率,迭代次数和损失函数的阈值必须训练前先定义好。
- 上述方法中,每个参数的学习率都是相同的,但这种方法是不合理的,如果训练数据是稀疏的,并且不同特征的出现频率差异较大,那么比较合理的做法是对于出现频率较低的特征设置较大的学习率,对于出现频率较大的特征设置较小的学习率。
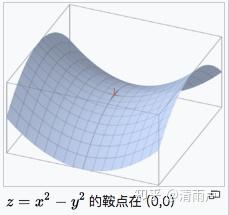
- 近期研究表明[1],深层网络之所以比较难以训练,并不是因为容易进入局部最优,因为网络结构十分复杂,即使进入了局部最优也可以得到很好的效果,难以训练的原因在于学习的过程很容易落入鞍点,也就是在一个维度是极小值,另一个维度却是极大值的点,而这种情况比较容易出现在平坦区域,在这种区域中,所有方向的梯度几乎都是0,但有的方向的二阶导小于0,即出现极大值。
- 动量法(Momentum)
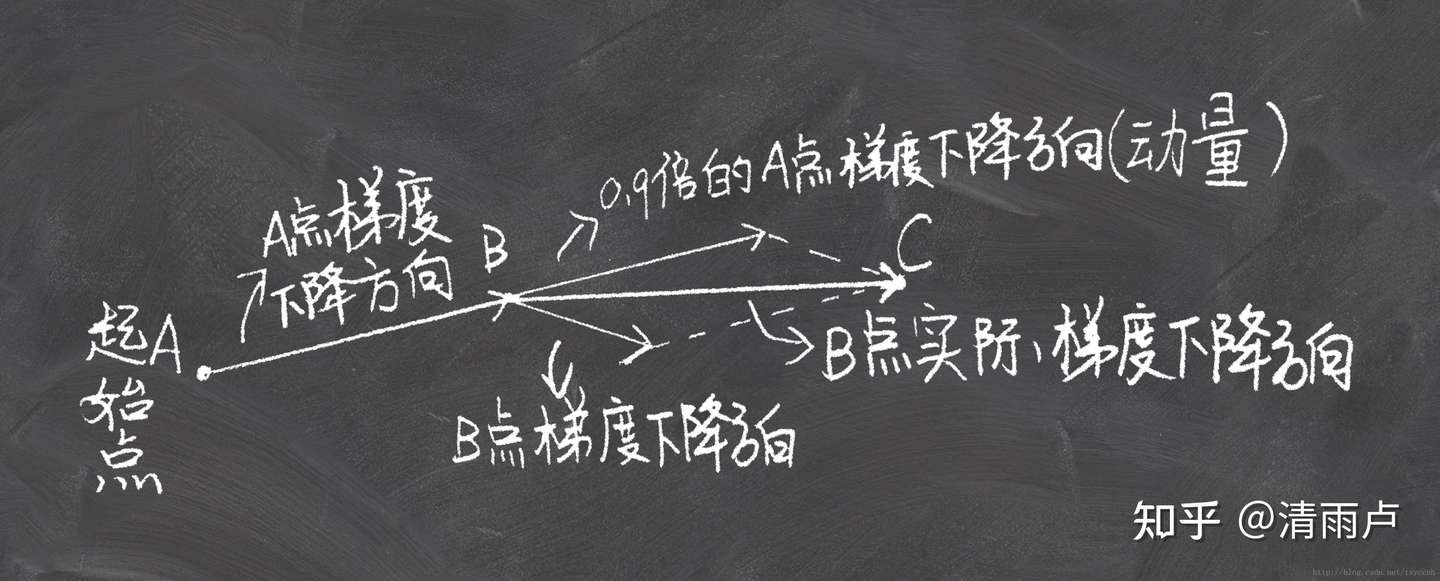
SGD(一般指小批量梯度下降)的一个缺点在于,其更新的方向完全依赖于当前batch计算出的梯度,因而十分不稳定。
Momentum算法借用了物理中的动量的概念,模拟物体运动时候的惯性,即在更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度对之前的梯度进行微调,这样一来,可以在一定程度上增加稳定性,从而学习的更快,并且有一定的摆脱局部最优的能力。
更新后的梯度 = 动量项(折损系数(gamma)) x 更新前的梯度+当前的梯度
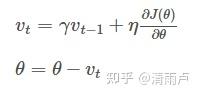
注意:
![]()
表示之前所有步骤所累积的动量和,而不仅仅是上一个更新梯度。
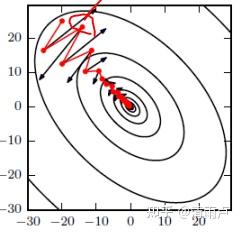
红色为SGD+momentum,黑色为SGD
【注意】:
- 动量项是表示在多大程度上保留原来的更新方向,值在0~1之间,是自己设置的超参数,训练开始时,由于梯度可能会很大,所以初始值一般选为0.5,当梯度慢慢减小的时候,改为0.9。
- 刚开始的时候,梯度方向变化很大,原始梯度起的作用较小,当前时刻的梯度方向减弱,则动量项较小,动量小则步长小
xwn:SGD其实就是摸着石头下山,动量项越大,则越难转向。初始时尚在找路阶段,原始梯度方向借鉴意义比较小,所以可以动量项设置小一些,后期经过积累基本已锁定正确优化方向,则动量项可以设置大一些,使得每次的当前梯度只是使总方向微调而已。
- 后面的时候,梯度方向变化较小了,原始梯度起的作用大,当前时刻的梯度方向增强,则动量项较大,动量大则步长大
- 动量项的解释:物体运动都是有惯性的,随机梯度下降和批量梯度下降的梯度之和本时刻的梯度有关,可以立刻改变方向,但如果加上动量的话,方向不可能骤转。
- 当动量项分别设置为0.5,0.9,0.99的时候,分别表示最大速度2倍、10倍、100倍于SGD的算法
- xwn: pytorch 中用的SGD其实为加入动量的mini-batch SGD

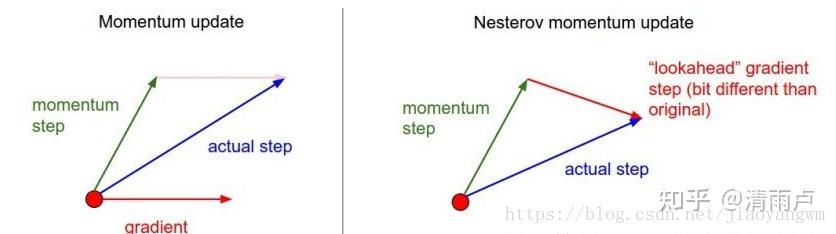
- Nesterov Momentum(Nesterov Accelerated Gradient)
在预测参数下一次的位置之前,我们已有当前的参数和动量项,先用
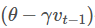
作为参数下一次出现位置的预测值,虽然不准确,但是大体方向是对的,之后用我们预测到的下一时刻的值来求偏导,让优化器高效的前进并收敛。
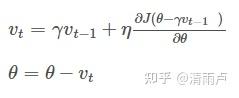
其中:
![]()
表示之前所有步骤所累积的动量和,θ表示参数,一般 γ 仍取值 0.9 左右。
【注意】:在计算梯度时,不是在当前位置,而是未来的位置上
NAG 可以使 RNN 在很多任务上有更好的表现。
【自适应学习率的方法】
- Adagrad法[2]
该方法是基于梯度的优化方法,其主要功能是:对于不同的参数使用不同的学习率,频繁变化的参数以更小的步长进行更新,而稀疏的参数以更大的步长进行更新,
适合于处理稀疏数据。
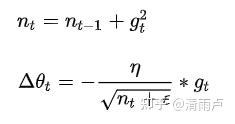
对g_t从1到t进行一个递推形成一个对学习率约束项
,
![]()
用来保证分母非0。
xwn:不同参数的梯度不同,但之前的方法所有参数的学习率是相同的。
对于稀疏数据而言,每当该参数所对应的特征缺失或者为0时,其基本就不更新了,所以稀疏的那部分特征所对应参数更新频率较低,收敛较慢。(累积的梯度也较小)
此方法通过学习率除以累积梯度的方法,增大稀疏参数的学习率,降低稠密的
超参数设定值:一般η选取0.01
直观感受AdaGrad:
假设我们现在采用的优化算法是最普通的梯度下降法mini-batch。它的移动方向如下面蓝色所示:

假设我们现在就只有两个参数w,b,我们从图中可以看到在b方向走的比较陡峭,这影响了优化速度。
而我们采取AdaGrad算法之后,我们在算法中使用了累积平方梯度n_t=n_(t-1)+g2。
从上图可以看出在b方向上的梯度g要大于在w方向上的梯度。
那么在下次计算更新的时候,r是作为分母出现的,越大的反而更新越小,越小的值反而更新越大,那么后面的更新则会像下面绿色线更新一样,明显就会好于蓝色更新曲线。

结论:在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小),并且能够使得陡峭的方向变得平缓,从而加快训练速度。
特点:
- 前期较小的时候, 学习率约束项较大,能够放大梯度
- 后期较大的时候,学习率约束项较小,能够约束梯度
缺点:
- 由公式可以看出,仍依赖于人工设置一个全局学习率
- 设置过大的话,会使学习率约束项过于敏感,对梯度的调节太大
- 中后期,分母上梯度平方的累加将会越来越大,使参数更新梯度区域0,使得训练提前结束
【补充】:
It adapts the learning rate to the parameters, performing smaller updates (i.e. low learning rates) for parameters associated with frequently occurring features, and larger updates (i.e. high learning rates) for parameters associated with infrequent features. For this reason, it is well-suited for dealing with sparse data.
高频出现特征的相关参数有较小的更新,低频出现特征的相关参数有较大的更新,适合处理稀疏数据。
原论文对稀疏数据的解释:sparse data (input sequences where g_t has many zeros)
网上对于适合稀疏数据的解释:
- Adadelta/RMSprop
Adadetla是Adagrad的一个延伸,它旨在解决Adagrad学习率不断急剧单调下降的问题,Adagrad是利用之前所有梯度的平方和,Adadelta法仅计算在一个时间区间内的梯度值的累积和。
此处的梯度累积和定义为:关于过去梯度值的指数衰减均值,当前时间的梯度均值是基于过去梯度的均值和当前梯度值平方的加权平均,γ是权重。
xwn:每一次都会在之前的梯度积累值上乘γ,越久远的梯度值,被乘γ的次数就越大,被遗忘的就越多。
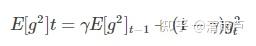
7.1
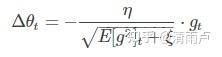
7.2
这个分母相当于梯度的均方根 root mean squared (RMS),在数据统计分析中,将所有值平方求和,求其均值,再开平方,就得到均方根值 ,所以可以用 RMS 简写:
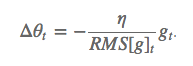
RMSprop可以算作Adadelta的一个特例,γ=0.9
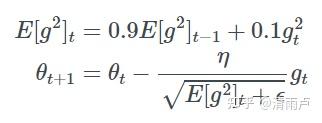
RMSprop提出者Hinton 建议设定γ为0.9, 学习率η为 0.001。
RMSprop和Adadelta都是大约在同一时间独立开发的,它们都是为了解决Adagrad的学习率急剧下降的问题。
总体算法图,可能会对全局有把握:

RMSProp算法不是像AdaGrad算法那样直接暴力地累加平方梯度,而是加了一个衰减系数来控制历史信息的获取多少。见公式7.1。γ作用相当于加了一个指数衰减系数来控制历史信息的获取多少,通俗理解,见https://zhuanlan.zhihu.com/p/29895933
优点:
1、RMSprop算是Adagrad的一种发展,和Adadelta的变体,效果趋于二者之间
2、适合处理非平稳目标-对于RNN效果很好
- Adam:Adaptive Moment Estimation自适应矩估计
矩估计

二阶矩估计:
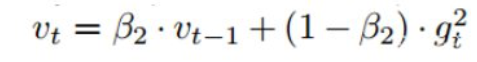
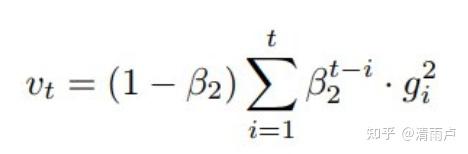
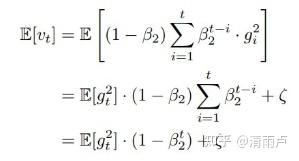
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。公式如下:
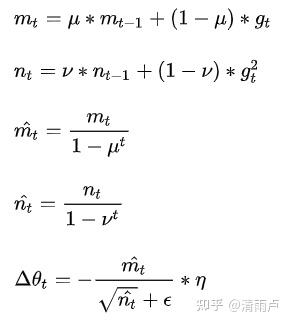


特点:


参考:
[1] Adolphs, Leonard, Hadi Daneshmand, Aurelien Lucchi, and Thomas Hofmann. “Local Saddle Point Optimization: A Curvature Exploitation Approach.” ArXiv:1805.05751 [Cs, Math, Stat], February 14, 2019. http://arxiv.org/abs/1805.05751.
[2] Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. Journal of Machine Learning Research, 12, 2121–2159. Retrieved from http://jmlr.org/papers/v12/duchi11a.html
https://blog.csdn.net/u012328159/article/details/80252012
https://blog.csdn.net/cs24k1993/article/details/79120579
https://zhuanlan.zhihu.com/p/22252270
https://blog.csdn.net/jiaoyangwm/article/details/81457623
https://www.jiqizhixin.com/graph/technologies/f41c192d-9c93-4306-8c47-ce4bf10030dd Adam
18. 线性判别分析
线性判别分析(linear discriminant analysis,LDA)是对fisher的线性鉴别方法的归纳,这种方法使用统计学,模式识别和机器学习方法,试图找到两类物体或事件的特征的一个线性组合,以能够特征化或区分它们。所得的组合可用来作为一个线性分类器,或者,更常见的是,为后续的分类做降维处理。
线性判别分析是特征抽取的一种方法。
特征抽取又可以分为监督和无监督的方法。监督的特征学习的目标是抽取对一个特定的预测任务最有用的特征,比如线性判别分析(Linear Discriminant Analysis, LDA)。而无监督的特征学习和具体任务无关,其目标通常是减少冗余信息和噪声,比如主成分分析(Principle Components Analysis, PCA)、独立成分分析、流形学习、自编码器。
线性判别分析可以用于降维。
在实际应用中,数据是多个类别的,我们的原始数据一般也是超过二维的,投影后的也一般不是直线,而是一个低维的超平面。





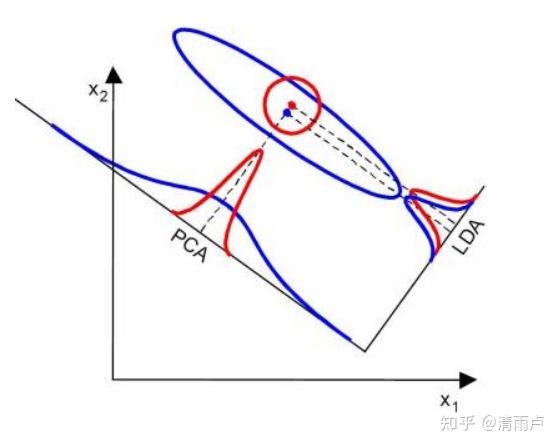
LDA与PCA 异同点:

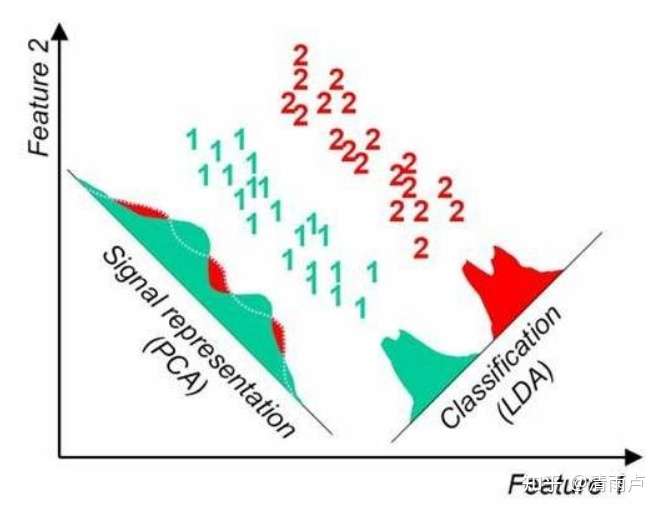
某些某些数据分布下PCA比LDA降维较优,如下图所示:
LDA优缺点:
LDA算法既可以用来降维,又可以用来分类,但是目前来说,主要还是用于降维。在进行图像识别相关的数据分析时,LDA是一个有力的工具。下面总结下LDA算法的优缺点。

参考:https://zhuanlan.zhihu.com/p/27899927
https://www.cnblogs.com/jiangkejie/p/11153555.html
https://www.cnblogs.com/jerrylead/archive/2011/04/21/2024384.html
19.朴素贝叶斯
- 为什么“朴素”:条件独立性假设
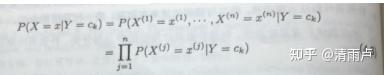
- 推导:

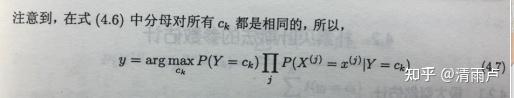
- 在计算条件概率P(x|y)时出现概率为0的情况怎么办:拉普拉斯平滑
- 优缺点:
- 优点:
- 对小规模的数据表现很好
- 面对孤立的噪声点,朴素贝叶斯分类器是健壮的
- 可解释性高
- 缺点:输入变量必须都是条件独立的
20.梯度提升决策树GBDT/MART (Gradient Boosting Decision Tree)
Decision Tree:GBDT中使用的决策树一般为CART
Gradient Boosting:每次沿着损失函数的梯度下降(负梯度)的方向训练基分类器,
最后将所有基分类器结果加和作为预测结果.
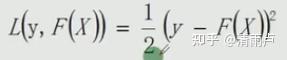
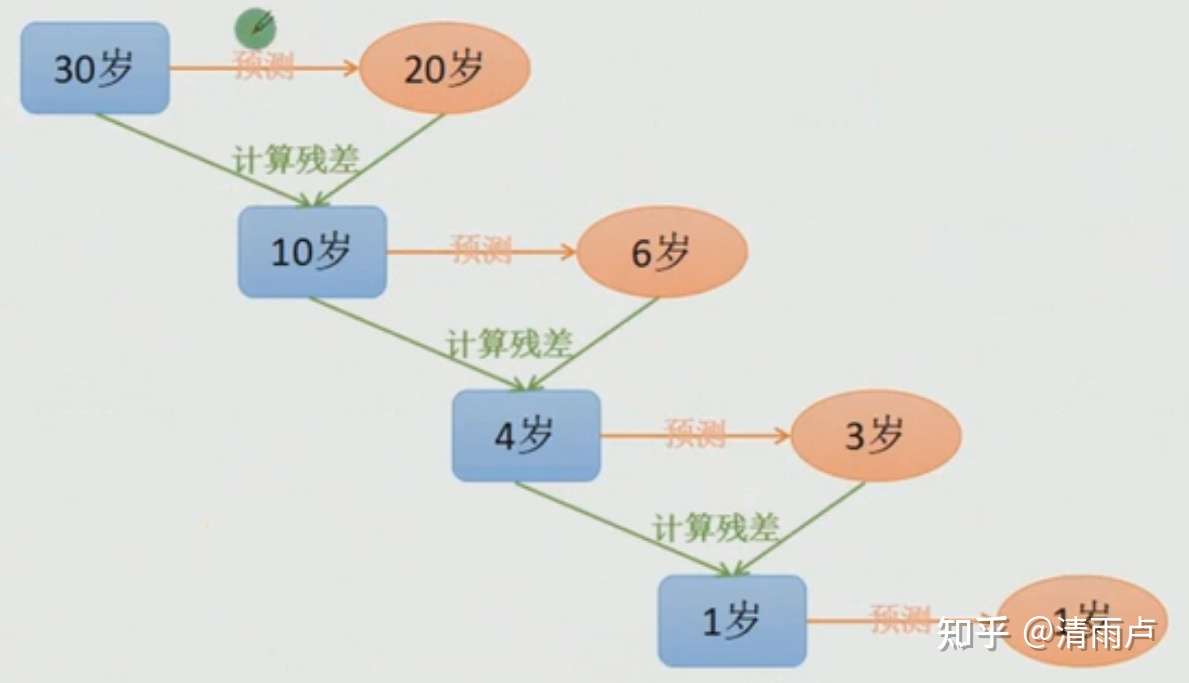
梯度提升与梯度下降关系:
两者都是沿着梯度下降的方向对模型进行优化.
- 梯度下降是LR或神经网络中使用,梯度优化是针对模型参数的,每次迭代过程都是对参数的更新.
- 梯度提升是直接对函数的更新,这样和使用什么模型无关,扩展了使用模型的种类
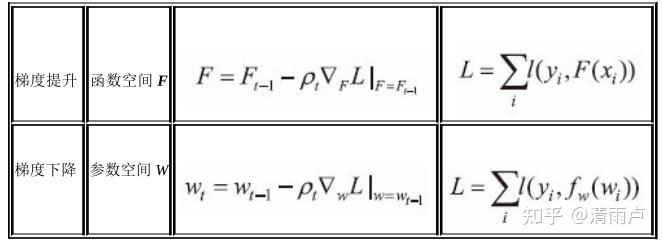
优点:
- 预测的时候基分类器可以并行计算,预测速度快
- 对于分布稠密的数据,泛化能力和表达能力都很好
- 采用决策树作为基分类器,可解释性高,能自动发现特征之间的高阶关系,
也不需要对数据进行归一化等预处理
缺点:
- 高维稀疏数据,不如svm和神经网络
- 处理文本分类的时候,没有像处理数值特征的时候那么有优势
- 串行训练,训练过程慢
21.KMeans

优点:相对是高效的,它的计算复杂度是O(NKt)接近于线性,其中N是数据对象的数目,K是聚类的簇数,t是迭代的轮数
缺点:(1)受初始点、初始K值的影响每次的结果不稳定;
(2)结果通常不是全局最优而是局部最优解
K值的选择:一般基于经验和多次实验结果。例如采用手肘法,我们可以尝试不同的K值:
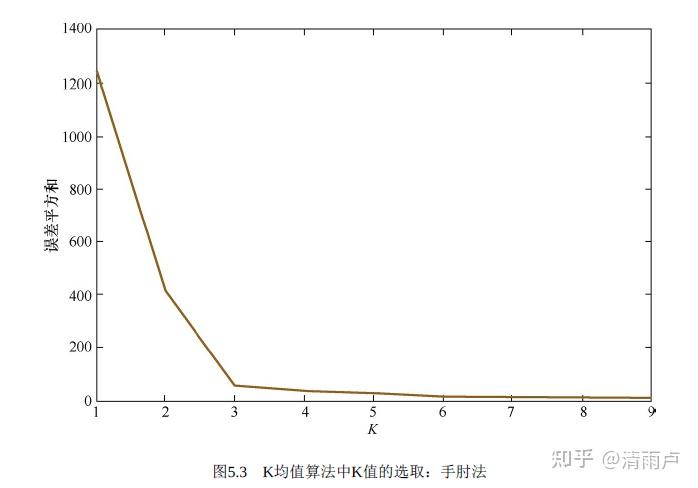
由图可见,K值越大,距离和越小;并且,当K=3时,存在一个拐点,就像人
的肘部一样;当K (1,3)时,曲线急速下降;当K>3时,曲线趋于平稳。手肘法认
为拐点就是K的最佳值
K-means++算法:优化K-means“初始点”缺点

二分K-Means算法:
1、将所有样本数据作为一个簇放到一个队列中。
2、从队列中选择一个簇进行K-means算法划分,划分为两个子簇,并将子簇添加到队列中。
3、循环迭代第二步操作,直到中止条件达到(聚簇数量、最小平方误差、迭代次数等)。
4、队列中的簇就是最终的分类簇集合。
从队列中选择划分聚簇的规则一般有两种方式,分别如下:
1、对所有簇计算误差和SSE(SSE也可以认为是距离函数的一种变种),选择SSE最大的聚簇进行划分操作(优选这种策略)。
2、选择样本数据量最多的簇进行划分操作
22. 牛顿法



xwn:牛顿法解决的问题:a,求解函数的根 b,求解函数极值
eg,求函数的根, 图像理解
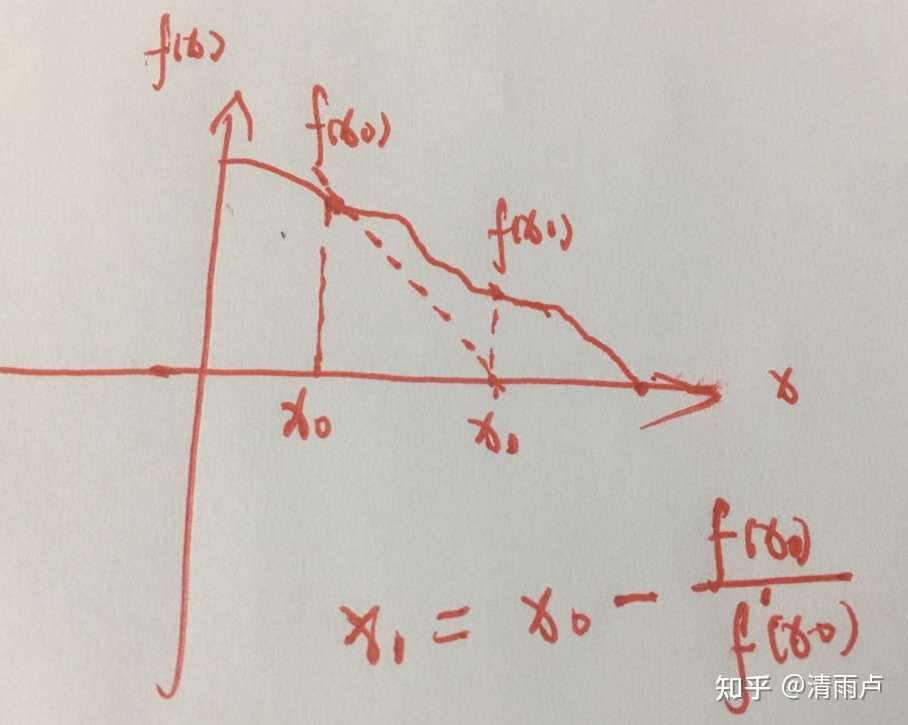
首先得明确,牛顿法是为了求解函数值为零的时候变量的取值问题的,具体地,当要求解 f(x)=0时,如果 f可导,那么将 f(x)展开:

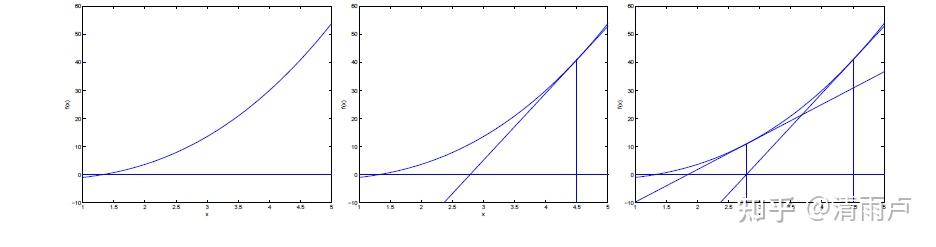

求局部最优点(极值点)
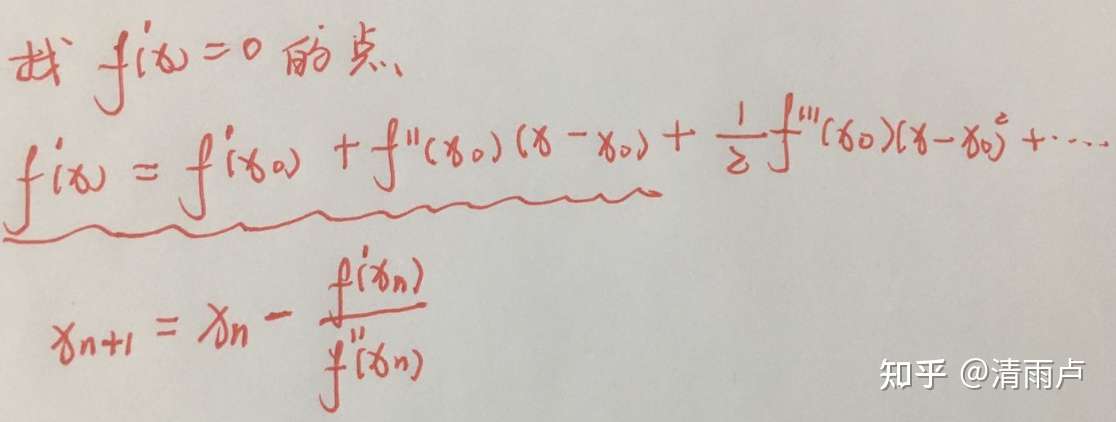
通过比较牛顿法和梯度下降法的迭代公式,可以发现两者极其相似。海森矩阵的逆就好比梯度下降法的学习率参数alpha。牛顿法收敛速度相比梯度下降法很快,而且由于海森矩阵的的逆在迭代中不断减小,起到逐渐缩小步长的效果。
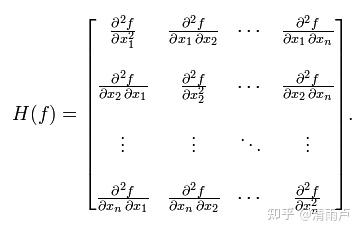
海森矩阵:
牛顿法的优缺点总结:
优点:二阶收敛,收敛速度快;
缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂,尤其是在高维情况下。(拟牛顿法就是以较低的计算代价求海森矩阵的近似逆矩阵)
参考 https://www.youtube.com/watch?v=FQN0-KHAgRw
https://zhuanlan.zhihu.com/p/37588590
http://sofasofa.io/forum_main_post.php?postid=1000966
23. 缺失值的处理
缺失值的原因:
- 信息暂时无法获取。如商品售后评价、双十一的退货商品数量和价格等具有滞后效应。
- 信息被遗漏。可能是因为输入时认为不重要、忘记填写了或对数据理解错误而遗漏,也可能是由于数据采集设备的故障
- 获取这些信息的代价太大。如统计某校所有学生每个月的生活费,家庭实际收入等等。
- 有些对象的某个或某些属性是不可用的。如一个未婚者的配偶姓名、一个儿童的固定收入状况等
缺失值较多:直接舍弃该特征
缺失值较少(<10%):填充处理
- 异常值填充:将缺失值作为一种情况处理0
- 均值/条件均值填充:
- 均值:对于数值类型属性,可采用所有样本的该属性均值,
非数值类型,可采用所有样本的众数
- 其条件均值指的是与缺失值所属标签相同的所有数据的均值
- 最近距离法K-means:先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的K个样本,将这K个值加权平均来估计该样本的缺失数据
- 插值
- 算法拟合填充:对有值的数据采用随机森林等方法拟合,然后对有缺失值的数据进行预测,用预测的值来填充
具体算法的缺失值处理:
- LR:如上所述
- 决策树:详见第15点
- XGBoost:将样本分别分配到左孩子和右孩子,选择增益大的方向分裂即可;如果在训练中没有缺失值而在预测中出现缺失,那么会自动将缺失值的划分方向放到右子树
参考链接
https://zhuanlan.zhihu.com/p/33996846
24. 模型评估中常用的验证方法
在机器学习中,我们通常把样本分为训练集和测试集,训练集用于训练模型,测试集用于评估模型。在样本划分和模型验证的过程中,存在着不同的抽样方法和验证方法。
1)Holdout检验
Holdout 检验是最简单也是最直接的验证方法,它将原始的样本集合随机划分成训练集和验证集两部分。比方说,对于一个点击率预测模型,我们把样本按照70%~30% 的比例分成两部分,70% 的样本用于模型训练;30% 的样本用于模型验证,包括绘制ROC曲线、计算精确率和召回率等指标来评估模型性能。
缺点:在验证集上计算出来的最后评估指标与原始分组有很大关系。
2)交叉检验
k-fold交叉验证:首先将全部样本划分成k个大小相等的样本子集;依次遍历这k个子集,每次把当前子集作为验证集,其余所有子集作为训练集,进行模型的训练和评估;最后把k次评估指标的平均值作为最终的评估指标。在实际实验中,k经常取10。
留一验证:每次留下1个样本作为验证集,其余所有样本作为测试集。样本总数为n,依次对n个样本进行遍历,进行n次验证,再将评估指标求平均值得到最终的评估指标。在样本总数较多的情况下,留一验证法的时间开销极大。事实上,留一验证是留p验证的特例。
留p验证:每次留下p个样本作为验证集,而从n个元素中选择p个元素有C(p,n)种可能,因此它的时间开销更是远远高于留一验证,故而很少在实际工程中被应用。
3) 自助法:
不管是Holdout检验还是交叉检验,都是基于划分训练集和测试集的方法进行模型评估的。然而,当样本规模比较小时,将样本集进行划分会让训练集进一步减小,这可能会影响模型训练效果。有没有能维持训练集样本规模的验证方法呢?自助法可以比较好地解决这个问题。
自助法是基于自助采样法的检验方法。对于总数为n的样本集合,进行n次有放回的随机抽样,得到大小为n的训练集。n次采样过程中,有的样本会被重复采样,有的样本没有被抽出过,将这些没有被抽出的样本作为验证集,进行模型验证,这就是自助法的验证过程。
当样本无穷大时,使用自助法有多少样本未被选择:
一个样本一次抽中概率为1-1/n,n次未抽中的概率为(1-1/n)^n,
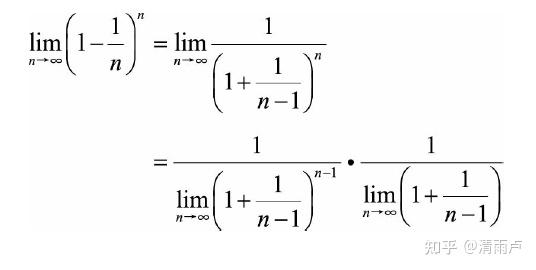
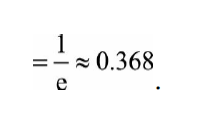
25. 主成分分析
主成分分析是一种降维的方法,目的是找到一个超平面,将原有样本投射在该超平面上,原则则是样本经过投射后损失的信息尽量的少。
PCA 对该超平面有两种解释:
- 最近重构性:样本点到该超平面的距离都足够近。
- 最大可分性:样本点到该超平面的投影都尽量可分。
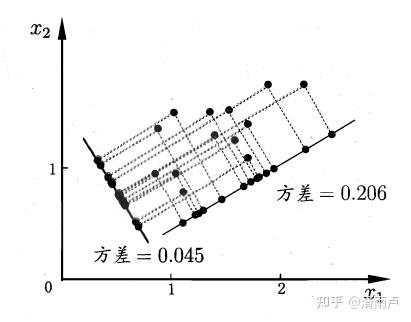
用最大可分性来推导,就是使得投影后的样本的方差尽可能大,两种方式都可以得到下式:(tr表示矩阵的迹,即矩阵主对角线元素的和,也等于矩阵所有特征值的和)

对其使用拉格朗日乘子法得到:

对XXT做特征值分解,取最大的d'(d'为降维后的维数)个特征值对应的特征向量作为W,即得到PCA的解。

d'的选取:
- 用户事先指定。
- 用其它开销较小的学习器先进行交叉验证选取。
- 从重构的角度出发,设定一个重构阈值,如t=95%:

降维的作用:
- 增大样本采样密度。
- 去除噪声。
26.Softmax函数的特点和作用是什么
我们知道max,假如说我有两个数,a和b,并且a>b,如果取max,那么就直接取a,没有第二种可能
但有的时候我们不想这样,因为这样会造成分值小的那个饥饿。所以我希望分值大的那一项经常取到,分值小的那一项也偶尔可以取到,那么我用softmax就可以了
现在还是a和b,a>b,如果我们取按照softmax来计算取a和b的概率,那a的softmax值大于b的,所以a会经常取到,而b也会偶尔取到,概率跟它们本来的大小有关。所以说不是max,而是Softmax那各自的概率究竟是多少呢,我们下面就来具体看一下
定义:

1、计算与标注样本的差距
在神经网络的计算当中,我们经常需要计算按照神经网络的正向传播计算的分数S1,和按照正确标注计算的分数S2,之间的差距,计算Loss,才能应用反向传播。Loss定义为交叉熵
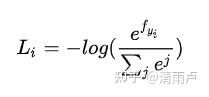
![]()
样本中正确的那个分类的对数值。
取log里面的值就是这组数据正确分类的Softmax值,它占的比重越大,这个样本的Loss也就越小,这种定义符合我们的要求。
2、计算上非常方便
当我们对分类的Loss进行改进的时候,我们要通过梯度下降,每次优化一个step大小的梯度。我们定义选到yi的概率是
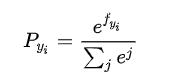
然后我们求Loss对每个权重矩阵的偏导,应用链式法则
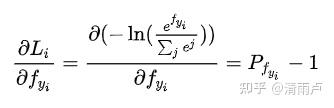

27.样本不均衡
- 导致模型性能降低的本质原因
模型训练时优化的目标函数和人们在测试时的评价标准不同:
- 分布:在训练时优化的是整个训练集(正负样本比例可能是1∶99)的正确率 而测试时可能想要模型在正样本和负样本上的平均正确率尽可能大(实际上是期望正负样本比例为 1∶1)
- 权重(重要性):训练时认为所有样本的贡献是相等的,而测试时假阳性样本(False Positive) 和伪阴性样本(False Negative)有着不同的代价
- 解决办法
- 基于数据
a)随机采样:欠采样(有放回)+过采样(放不放回都可以)
欠采样对少数样本进行多次复制,扩大了数据规模,但容易造成过拟合
欠采样丢弃部分样本,有可能会丢失部分有用信息,导致模型只学到了整体模式的部分
b)SMOTE算法(针对过采样)不再简单的复制样本,而是生成新样本,降低过拟合
对少数类的数据集的每一个样本x,从其k近邻中随机选取一个样本y,在其连线上随机选取一点,作为新合成的样本
根据采样倍率重复操作
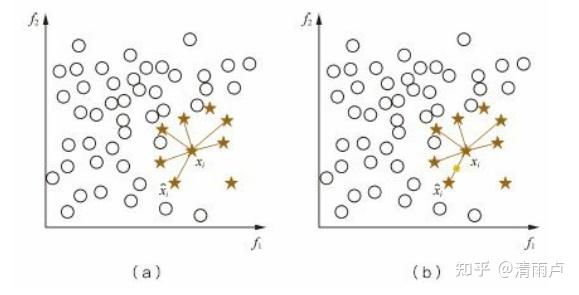
每个少数类样本合成相同数量的新样本,这可能会增大类间重叠度,并且会生成一些不能提供有益信息的样本
i)Borderline-SMOTE:只给那些处在分类边界上的少数类样本 合成新样本
ii)ADASYN: 给不同的少数类样本合成不同个数的新样本
iii)数据清理方法:进一步降低合成样本带来 的类间重叠
数据扩充方法也是一种过采样,对少数类样 本进行一些噪声扰动或变换(如图像数据集中对图片进行裁剪、翻转、旋转、加光照等)以构造出新的样本
c)Informed Undersampling(欠采样):解决数据丢失问题
i)easy ensemble
从多数类中随机抽取子集E,与所有少数类训练基分类器。
重复操作后,基分类器融合
ii)Balance Cascade
从多数类中随机抽取子集E,与所有少数类训练基分类器
从多数类中剔除被分类正确的样本,继续重复操作
融合基分类器
- 基于算法
- 改变损失函数,不同类别不同权重 ------不平衡
- 转化为单类学习(one-class learning)---极度不平衡
- 异常检测(anormaly detection)
28.损失函数
- 回归
- MSE loss/均方误差--L2损失
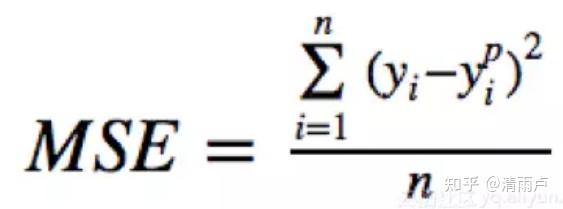
- MAE loss/平均绝对误差--L1损失
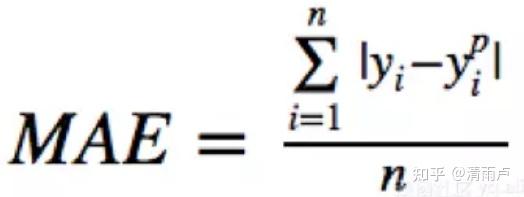
- MSE VS MAE
MSE易求解,但对异常值敏感, 得到观测值的均值
MAE对于异常值更加稳健, 得到观测值的中值
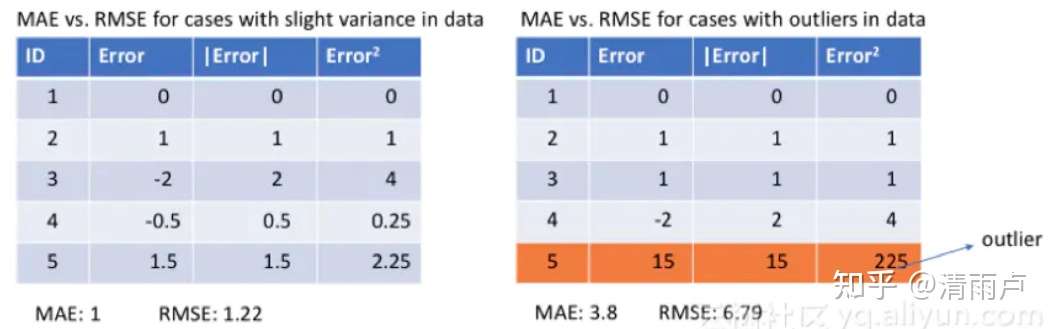
对于误差较大的异常样本,MSE损失远大于MAE,使用MSE的话,模型会给予异常值更大的权重,全力减小异常值造成的误差,导致模型整体表现下降
因此,训练数据中异常值较多时,MAE较好
但MAE在极值点梯度会发生跃迁,即使很小的损失也会造成较大的误差,为解决这一问题,可以在极值附近动态减小学习率
总结:MAE对异常值更加鲁棒,但导数的不连续导致找最优解过程中低效
MSE对异常值敏感,但优化过程更加稳定和准确
问题:例如某个任务中90%的数据都符合目标值——150,而其余的10%数据取值则在0-30之间
那么利用MAE优化的模型将会得到150的预测值而忽略的剩下的10%(倾向于中值);
而对于MSE来说由于异常值会带来很大的损失,将使得模型倾向于在0-30的方向取值。
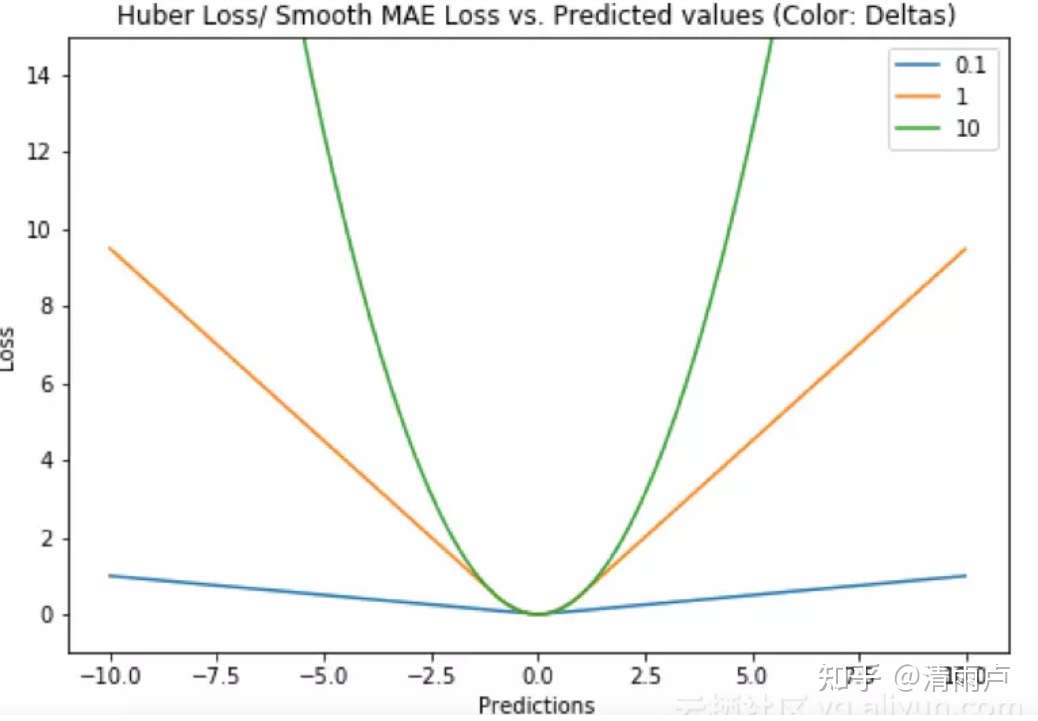
- Huber loss/平滑平均绝对误差
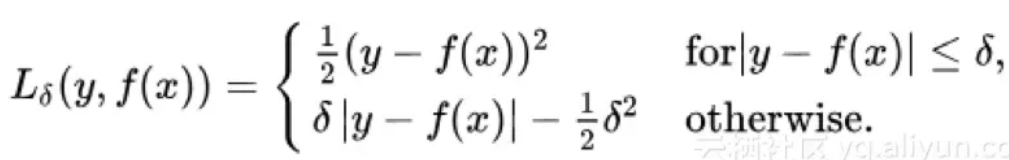
对异常值不敏感,且可微
使用超参数δ来调节这一误差的阈值。当δ趋向于0时它就退化成了MAE,而当δ趋向于无穷时则退化为了MSE
- Log-Cosh loss
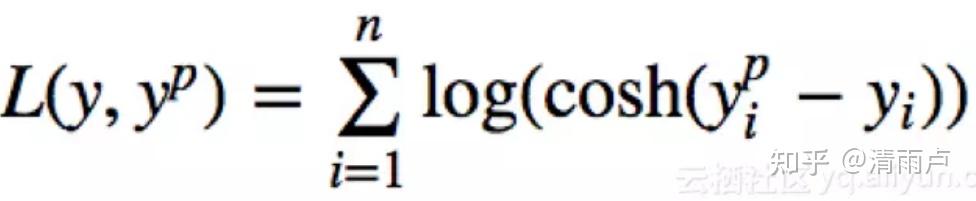
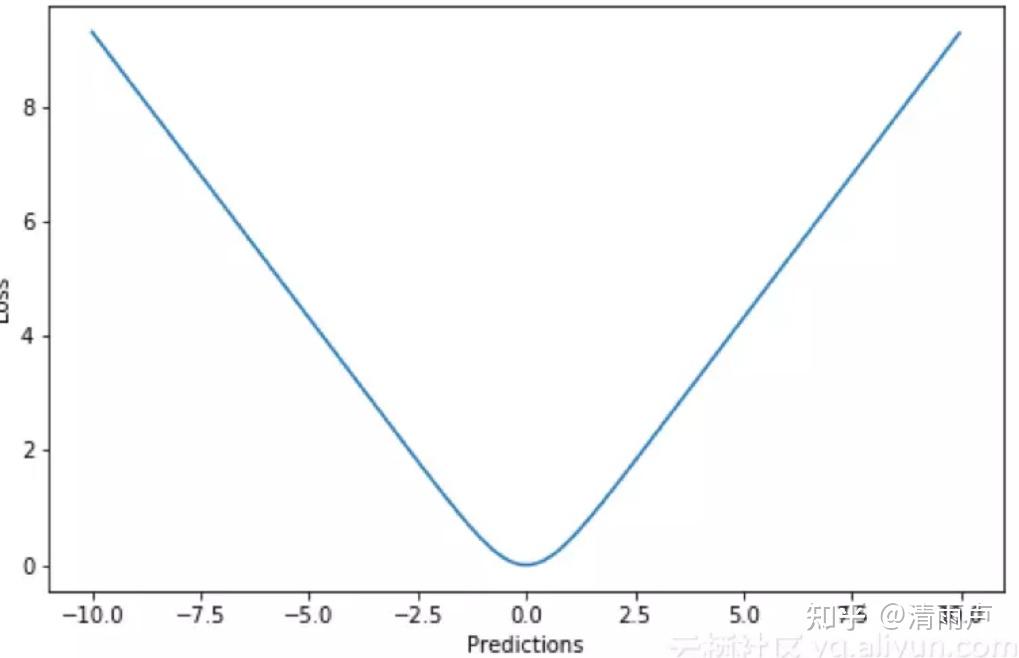
拥有Huber的所有优点,并且在每一个点都是二次可导的。二次可导在很多机器学习模型中是十分必要的
- Quantile loss/分位数损失
参考:https://www.jianshu.com/p/b715888f079b
- 分类
- 0-1 loss(很少使用)
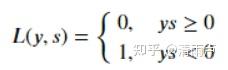
对每个错分类点都施以相同的惩罚
不连续、非凸、不可导,难以使用梯度优化算法
- Cross Entropy Loss/交叉熵损失
- Hinge Loss
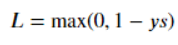
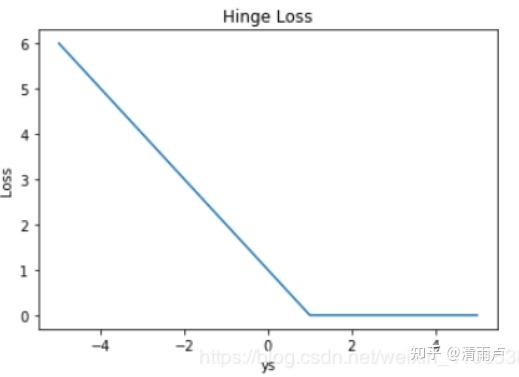
一般多用于支持向量机(SVM)
ys > 1 的样本损失皆为 0,由此带来了稀疏解,使得 SVM 仅通过少量的支持向量就能确定最终超平面
- Exponential loss/指数损失
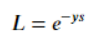
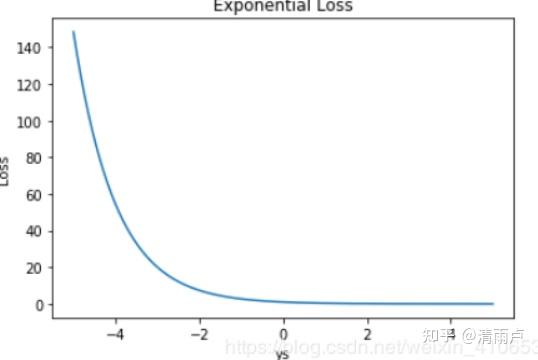
一般多用于AdaBoost 中。因为使用 Exponential Loss 能比较方便地利用加法模型推导出 AdaBoost算法。该损失函数对异常点较为敏感,相对于其他损失函数robust性较差
- Modified Huber loss
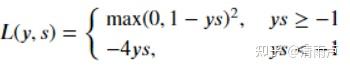
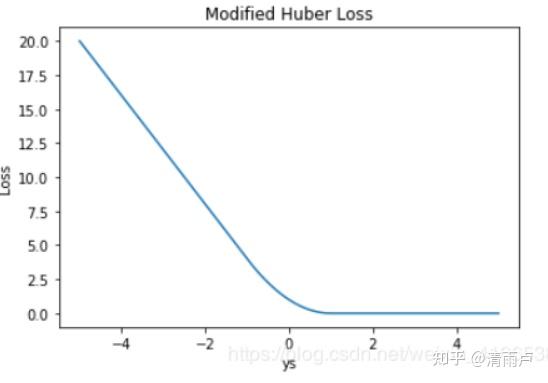
结合了 Hinge Loss 和 交叉熵 Loss 的优点。一方面能在 ys > 1 时产生稀疏解提高训练效率;另一方面对于 ys < −1 样本的惩罚以线性增加,这意味着受异常点的干扰较少
- Softmax loss
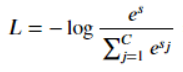
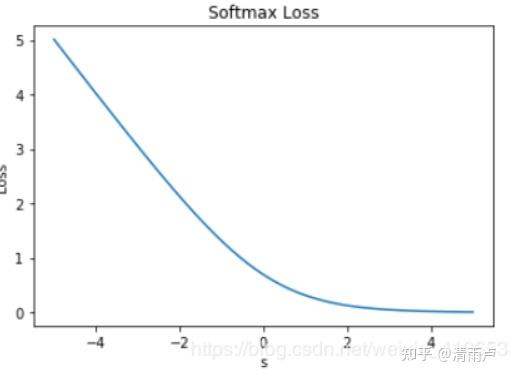
当 s << 0 时,Softmax 近似线性;当 s>>0 时,Softmax 趋向于零。Softmax 同样受异常点的干扰较小,多用于神经网络多分类问题中
注:相比 Exponential Loss,其它四个 Loss,包括 Softmax Loss,都对离群点有较好的“容忍性”,受异常点的干扰较小,模型较为健壮
参考:https://blog.csdn.net/weixin_41065383/article/details/89413819
- focal loss
- 背景:
one-stage网络因为正负样本严重不均衡,且负样本中还有很多易区分的原因,精度一般低于two-stage 网络(two-stage 利用RPN网络,将正负样本控制在1:3左右)
- 原理:
1,解决正负样本不均衡问题:添加权重控制,增大少数类样本权重
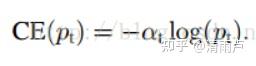
2,解决难易样本问题:Pt越大说明该样本易区分,应当降低容易区分样本的权重。也就是说希望增加一个系数,概率越大的样本,权重系数越小。
另,为提高可控性,引入系数γ
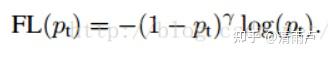
综合:两个参数α和γ协调来控制,本文作者采用α=0.25,γ=2效果最好
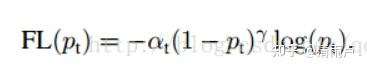
参考:https://blog.csdn.net/wfei101/article/details/79477303
29.贝叶斯决策论
- 概率框架下实施决策的基本方法
以多分类举例:
共 N 种类别,λij 为将 j 类样本误分类为 i 类样本所产生的损失。
那么,给定样本 x,将其分类为 i 类样本所产生的期望损失为:
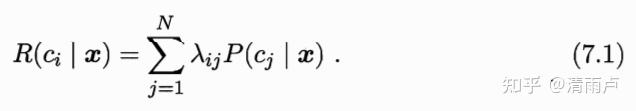
任务目标为找到分类器 h:X→Y ,使总体损失最小:
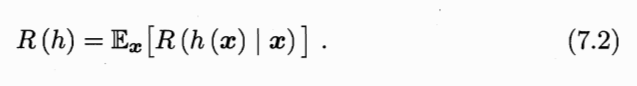
最好的 h 显然是对每个样本 x,都选择期望损失最小的类别:
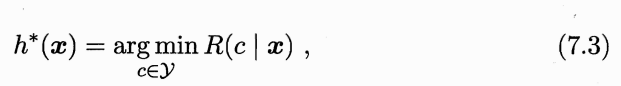
h* 就叫贝叶斯最优分类器,R(h*)叫贝叶斯风险,1-R(h*) 是分类器所能达到的最优性能,即通过机器学习所能产生的模型精度的理论上限。
比如,目标是最小化误分类率,那么:
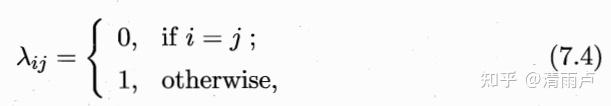
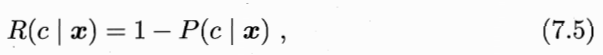
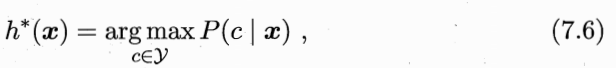
- 判别式 vs 生成式
两者的本质区别在于建模对象不同。
- 判别式
直接对 P(c|x) 建模:给定 x,使用模型预测其类别 c,通过各种方法来选择最好的模型。
- 生成式
对 P(c,x) 建模,再计算 P(c|x):

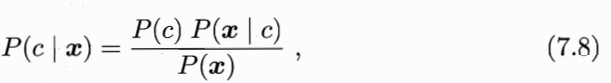
P(c)好得,P(x)无所谓,重点在如何获取 P(x|c).
- 极大似然估计
假设 P(x|c) 满足某种分布(分布参数为 θ),再用极大似然估计找出 θ.
- 朴素贝叶斯
假设 x 中所有属性相互独立:
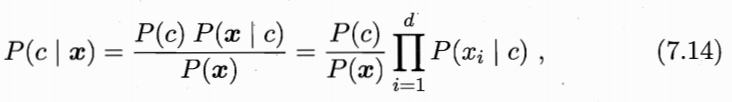
生成式模型理解 LR:
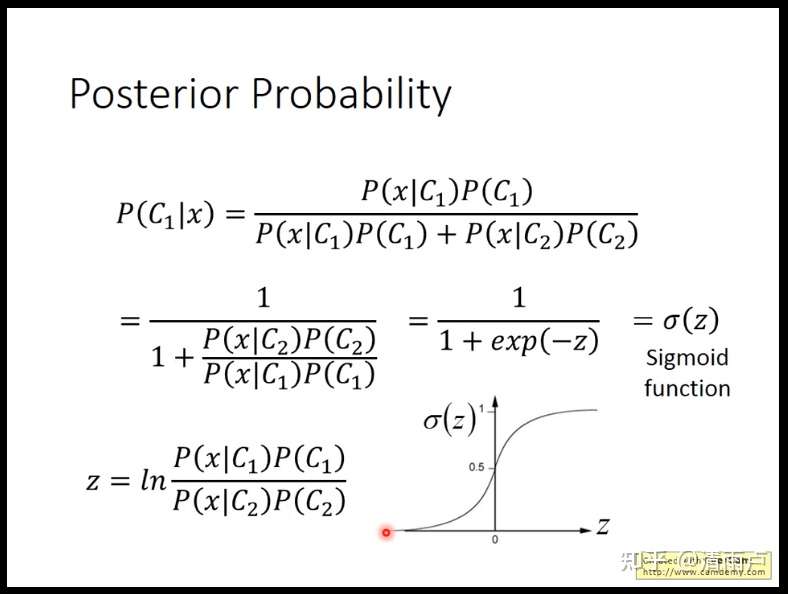



- 常见的判别式与生成式模型:
判别式:线性回归、逻辑回归、线性判别分析、SVM、神经网络
生成式:隐马尔科夫模型HMM、朴素贝叶斯、高斯混合模型GMM、LDA、KNN
- 优缺点
- 生成式模型最终得到的错误率会比判别式模型高,但是收敛所需的训练样本数会比较少。
- 生成式模型更容易拟合,比如在朴素贝叶斯中只需要计数即可,而判别式模型通常都需要解决凸优化问题。
- 生成式模型可以更好地利用无标签数据。
- 生成式模型可以用来生成样本 x.
- 生成式模型可以用来检测异常值。
30.采样
- 实现均匀分布的随机数生成器
计算机程序都是确定性的,因此并不能产生真正意义上的完全均匀分布随机数,只能产生伪随机数。
计算机 的存储和计算单元只能处理离散状态值,因此也不能产生连续均匀分布随机数,只能通过离散分布来逼近连续分布(用很大的离散空间来提供足够的精度)
线性同余法:根据当前生成的随机数xt来进行适当变换,进而产生下一次的随机数xt+1 。初始值x0称为随机种子
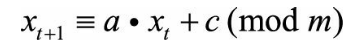
得到的是区间[0,m−1]上的随机整数,如果想要得到区间[0,1]上的连续均匀分布随机数,用xt除以m即可。
实际上对于特定的种子,很多数无法取到,循环周期基本达不到m。进行多次操作,得到的随机数序列会进入循环周期
gcc中的设置

种子seed应该是随机选取的,可以将时间戳作为种子
reference:
因为本文实在是总结得太好了,本着尊重作者的态度给出原文链接:https://zhuanlan.zhihu.com/p/429901476
本人也在原文的基础上做了一些补充和改进,增加了一些重要的知识点,得到了现在一个比较完善的版本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号