【自然语言处理】:Word2Vec的理解
笔者在学习了吴恩达,以及斯坦福cs224n后,对于Word2Vec有了一些粗浅的理解,如有不合理之处请大家多多指正。这里就记记笔记啦:
一.词汇表征
在自然语言处理当中,一种是利用one-hot vector(独热编码)进行词汇表征,假设有30000个单词,那么hotel是其中的第7889个单词,那么整个表示hotel的向量,只有在一维向量的索引第7889处,数字为1,其余为0.这样计算机就可以知道这个单词是什么了,因为计算机和我们人类并不一样,他并不会清楚每一个单词的含义,我们只能够使用数字来表示单词。

但是用这种方式我们并不能够让计算机知道两个单词之间的相似程度,以及对应的关系。比如english和chinese可以归类为同一类的词语,而women对应这man。这个时候,单词的特征表示向量诞生了!
我们的一个单词,可以用其他不用的单词来进行表示,如下所示:
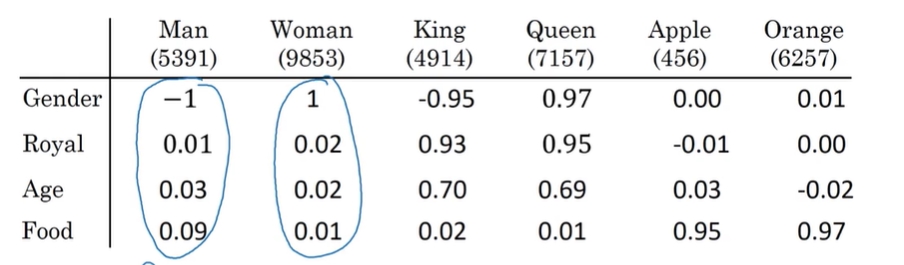
我们一个单词可以用其他单词不同的权重来表示,比如对于man而言,其gender的特性为-1,royal为0.01说明不太royal,food一般吃得比女性较多,因此food的参数为0.09,而women的food参数为0.01。通过这种方式就可以知道每个单词的具体语义了。最终,某一个单词的向量表示会长成这样;

二.skip-gram算法
在我们的word2vec当中,分为了两种算法,一种是skip-gram,一种是cbow(词袋模型)算法,这里讲解skip-gram算法。
假设我们有这样的两句话:

在这两句话当中都同时出现了banking这个单词,但是这两句话却表示的是不同的意思。skip-gram算法认为,只要知道了中心词banking,我们就可以去预测这个词旁边词语是什么的概率。
那么这个模型是干啥用的呢?假设有一个词语,有了word2vec这个模型,我们就可以用于知道这个单词周围每一个单词的概率是多少。(这个是我个人的理解,如有不对,请多多指正)
因此我们定义中心单词为wt,不是中心单词的单词为w-t,这样我们就可以通过条件概率得到单词wt周围其中任何一个词语的概率,context可以表示wt 旁的任意一个单词。
其中J是我们的loss function,概率越大,则J越小,我们loss function就拟合得越好。

同样的,我们可以使用wt+2 来表示距离wt右边两个词距的词语,wt-2 来表示距离wt左边两个词距的词语。因此我们有这样的一个例子:

通过banking这个中心词,通过神经网络训练就可以得到其余词汇的概率啦!而且这些词汇在训练开始之前,我们是不知道其概率是啥的.现在我们用更深刻的数学形式来表示整个过程:

用J(theta)这个函数进行梯度下降和优化,就可以得到theta的最优值,从而使得对J(theta)求导的概率值最大,这个概率值也就是中心单词wt旁边所有单词最有可能出现的单词的概率之和,概率之和最大了,就可以细分出每一个单词的概率。其中的参数theta其实就是中心单词的向量表示的参数。
由于在优化的时候,我们借助了神经网络,因此最后一定会有一个根据softmax层用于输出每一个单词的概率。softmax整个同时对于我妈呢来说已经非常熟悉了。公式如下:‘

公式当中的Uw表示的是除了center word之外的所有的words,进行遍历。Vc表示的是center word的特征向量。整个skip-gram的神经网络结构如下:
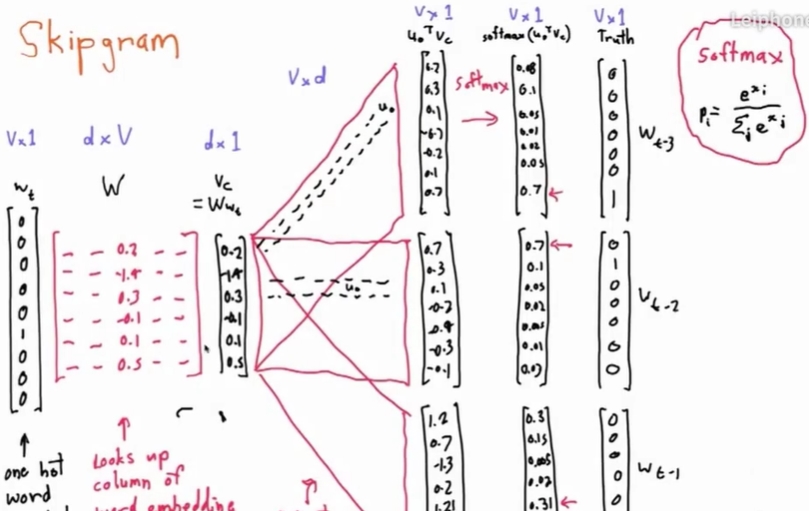
首先我们会有某个单词的one-hot vector Wt,然后经过一个参数矩阵,用整个one-hot vector乘以W整个参数矩阵(训练出来的),是所有单词的特征表示向量的集合,这样就可以得到我们想要的单词的特征表示向量(从one-hot 到feature representation),然后得到的Vc乘上周围单词的特征向量,通过softmax得到周围单词出现的概率,选取概率最大的那一个变成one-hot vector,经历这样的一个过程,我们就会知道周围单词有哪些会出现了!
三.skip-gram和CBOW的区别
skip-gram:一个词语W作为输入,输出的单词数量可以人为规定,且输出的为最有可能在W旁边的上下文
CBOW:多个词语作为输入,输出一个单词
这两者的区别可以如下所示的图来表示;

最后,我们通过word2vec训练出词汇表征之后,讲训练完后所有的词汇的特征表示进行可视化,就会得到这样的效果,具有相似单词属性的单词将会聚集在一起,形成一簇:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号