【推荐系统】:协同过滤简介
一.简介
推荐算法的整体流程是:召回——排序——策略调整
基于协同过滤的推荐算法有以下基本假设:
1.基于用户的协同过滤(User-based CF):和你喜欢相同物品的人,他们喜欢的东西你也喜欢
2.基于物品的协同过滤(item-based CF):和你喜欢的物品比较相似的物品,你也可能喜欢
二.协同过滤的具体过程
1.基于用户的协同过滤
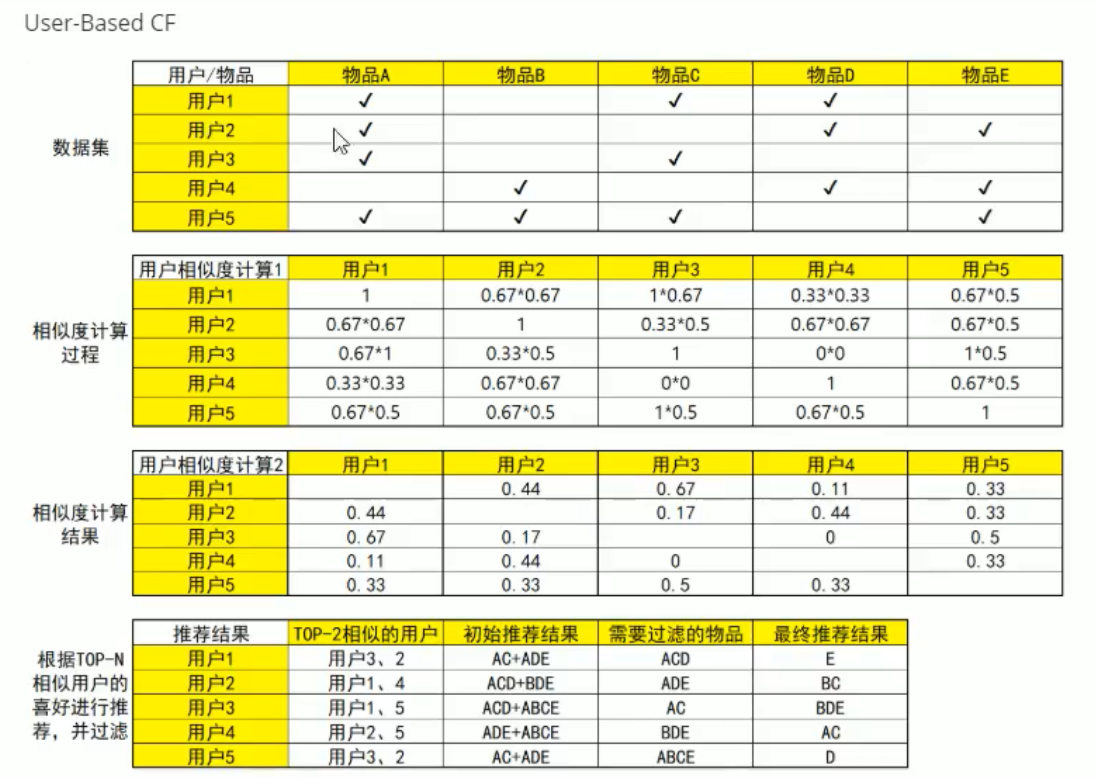
从上面可以看到用户如果买了一个东西则打钩,没有买则不打钩。假设我们有两个人,小明和小红。那么我们怎么计算这两个人喜欢物品的相似度呢?我们假设:
小明喜欢的东西有:篮球,足球,乒乓球
小红喜欢的东西有:篮球,足球,乒乓球,羽毛球
那么他们喜欢的相同物品数量是3,因此计算公式为:
3/3 * 3/4==9/12=3/4。这就是小明和小红两者之间喜欢物品的相似度。
然后计算小明和不同用户之间的喜好相似度,使用机器学习当中KNN的思想取最大的相似程度的人做推荐。找到人之后查看他们喜欢的共同物品,过滤掉,然后取另外用户喜好的物品给这个用户(小明)进行推荐。这就是基于用户的协同过滤的基本思想。
2.基于物品的协同过滤(item based CF)
我们用物品来计算相似度,如下图所示:
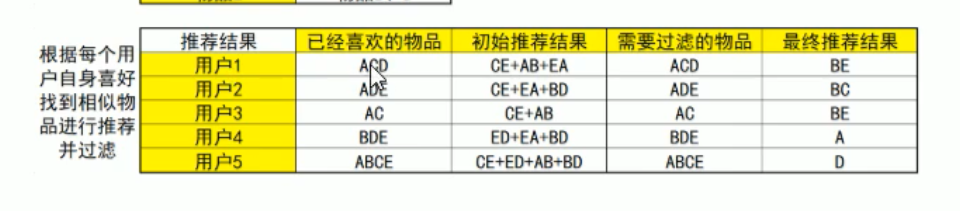
看看图自然就明白了,思想和基于用户的协同过滤是相同的。
3.咱们做推荐系统的大致思路如下:
1.首先通过特征工程将用户-物品评分矩阵创建出来
2.1通过基于用户的协同过滤
2.2或者用过给予物体的协同过滤
给用户推荐商品
三.相似度的计算
相似度不仅仅是我们刚刚做的这么简单,不是只需要比较物品即可,因为我们用户会对一个物品做出多种反应,评分,收藏,浏览次数等等。一般情况下还会使用实数值进行相似度的计算,相似度计算的数据有:
1.实数值(物品的评分情况)
2.布尔值(用户的行为,是否购买,是否收藏)
我们可以通过余玹相似度来计算两个物品之间的相似度,如下所示:

在计算余玹相似度的时候我们只需要考虑两个物品之间的夹角的值,也就是cos()的值,而不需要关心向量的长短。上图是一个仅仅具有两个特征的物品,因此维度是2.
2.我们可以通过皮尔逊相关系数来计算两个物品之间的相似度,也就是直接使用相关系数r进行运算,计算的公式如下图所示:
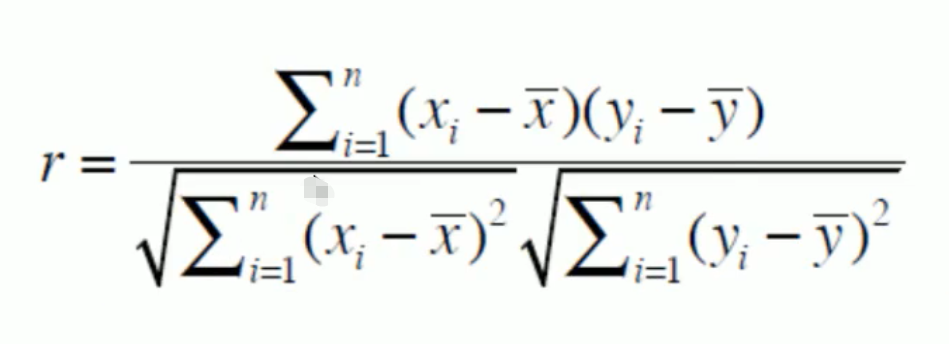
在这个公式当中同时考虑到了长度和角度的影响,当然也就在某些场景下使用的话会更加准确了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号