【深度学习】:一文入门Dropout层
Dropout层在神经网络层当中是用来干嘛的呢?它是一种可以用于减少神经网络过拟合的结构,那么它具体是怎么实现的呢?
假设下图是我们用来训练的原始神经网络:

一共有四个输入x_i,一个输出y。Dropout则是在每一个batch的训练当中随机减掉一些神经元,而作为编程者,我们可以设定每一层dropout(将神经元去除的的多少)的概率,在设定之后,就可以得到第一个batch进行训练的结果:
从上图我们可以看到一些神经元之间断开了连接,因此它们被dropout了!dropout顾名思义就是被拿掉的意思,正因为我们在神经网络当中拿掉了一些神经元,所以才叫做dropout层。
在进行第一个batch的训练时,有以下步骤:
1.设定每一个神经网络层进行dropout的概率
2.根据相应的概率拿掉一部分的神经元,然后开始训练,更新没有被拿掉神经元以及权重的参数,将其保留
3.参数全部更新之后,又重新根据相应的概率拿掉一部分神经元,然后开始训练,如果新用于训练的神经元已经在第一次当中训练过,那么我们继续更新它的参数。而第二次被剪掉的神经元,同时第一次已经更新过参数的,我们保留它的权重,不做修改,直到第n次batch进行dropout时没有将其删除。
备注:
这就是dropout层的思想了,为什么dropout能够用于防止过拟合呢?因为约大的神经网络就越有可能产生过拟合,因此我们随机删除一些神经元就可以防止其过拟合了,也就是让我们拟合的结果没那么准确。就如同机器学习里面的L1/L2正则化一样的效果!
那么我们应该对什么样的神经网络层进行dropout的操作呢?很显然是神经元个数较多的层,因为神经元较多的层更容易让整个神经网络进行预测的结果产生过拟合,假设有如下图所示的一个dropou层:
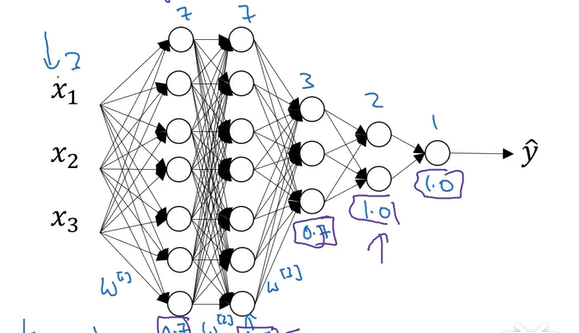
由于隐藏层的第一层和第二层神经元个数较多,容易产生过拟合,因此我们将其加上dropout的结构,而后面神经元个数较少的地方就不用加了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号