【图像分割】:使用全卷积神经网络FCN,进行图像语义分割详解(附代码实现)
一.导论
本教程的FCN基于Tensorflow实现,并在本教程当中做了相应的讲解,数据集和代码均已经上传Github链接:https://github.com/Geeksongs/Computer_vision
数据集采用了英国牛津大学视觉几何组 —— IIIT Pet数据集,链接如下:https://www.robots.ox.ac.uk/~vgg/data/pets/。如果无法下载也可以在我的Github上下载。
在图像语义分割领域,困扰了计算机科学家很多年的一个问题则是我们如何才能将我们感兴趣的对象和不感兴趣的对象分别分割开来呢?比如我们有一只小猫的图片,怎样才能够通过计算机自己对图像进行识别达到将小猫和图片当中的背景互相分割开来的效果呢?如下图所示:
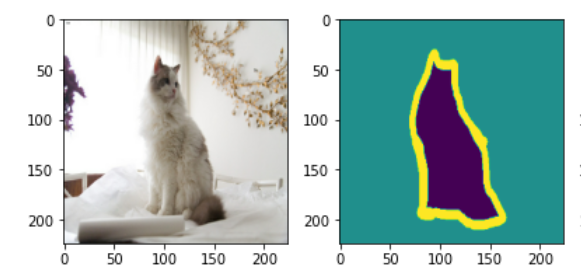
而在2015年出来的FCN,全卷积神经网络完美地解决了这个问题,将曾经mean IU(识别平均准确度)只有百分之40的成绩提升到了百分之62.2(在Pascal VOC数据集上跑的结果,FCN论文上写的),像素级别识别精确度则是90.2%。这已经是一个相当完美的结果了,几乎超越了人类对图像进行区分,分割的能力。如上图所示,小猫被分割为了背景,小猫,边缘这三个部分,因此图像当中的每一个像素最后只有三个预测值,是否为小猫,背景,或者边缘。全卷积网络要做的就是这种进行像素级别的分类任务。那么这个网络是如何设计和实现的呢?
二.网络的实现
这个网络的实现虽然听名字十分霸气,全卷积神经网络。不过事实上使用这个名字无非是把卷积网络的最后几层用于分类的全连接层换成了1*1的卷积网络,所以才叫这个名字。这个网络的首先对图片进行卷积——>卷积——>池化,再卷积——>卷积——>池化,直到我们的图像缩小得够小为止。这个时候就可以进行上采样,恢复图像的大小,那么什么是上采样呢?你估计还没有听说过,等下咱们一 一道来。这个网络的结构如下所示(附上论文上的原图):
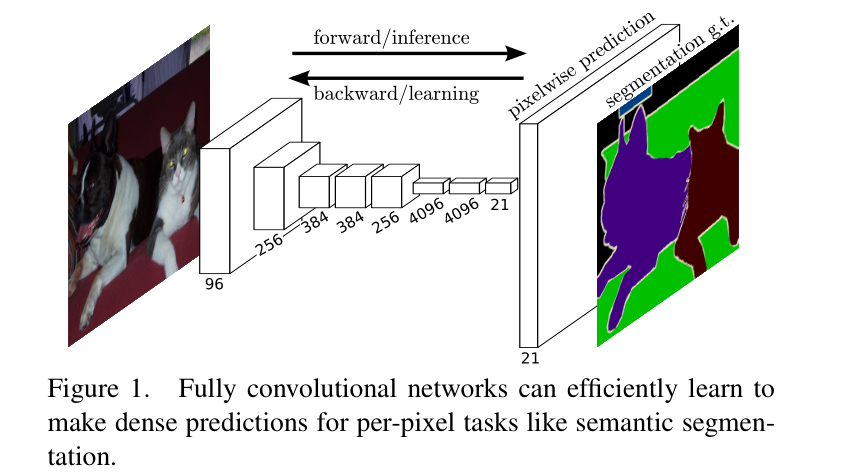
从中可以看到我们输入了一个小猫和小狗在一起时的图片,最后再前向传播,在这个前向传播网络的倒数第三层,卷积神经网络的长度就变成了N*N*21,因为在VOC数据集上一共有21个softmax分类的结果,因此每个类别都需要有一个相关概率(置信度)的输出。而前面这个前向传播的卷积神经网络可以是VGG16,也可以是AlexNet,Google Inception Net,甚至是ResNet,论文作者在前三个Net上都做了相应的尝试,但是因为ResNet当时还没出来,也就没有尝试过在前面的网络当中使用它。当我们的网络变成了一个N*N*21的输出时,我们将图像进行上采样,上采用就相当于把我们刚才得到的具有21个分类输出的结果还原成一个和原图像大小相同,channel相同的图。这个图上的每个像素点都代表了21个事物类别的概率,这样就可以得到这个图上每一个像素点应该分为哪一个类别的概率了。那么什么是图像的上采样呢?
三.图像的上采样
图像的上采样正好和卷积的方式相反,我们可以通过正常的卷积让图像越来越小,而上采样则可以同样通过卷积将图像变得越来越大,最后缩放成和原图像同样大小的图片,关于上采样的论文在这这篇论文当专门做了详解:https://arxiv.org/abs/1603.07285。上采样有3种常见的方法:双线性插值(bilinear),反卷积(Transposed Convolution),反池化(Unpooling)。在全卷积神经网络当中我们采用了反卷积来实现了上采样。我们先来回顾一下正向卷积,也称为下采样,正向的卷积如下所示,首先我们拥有一个这样的3*3的卷积核: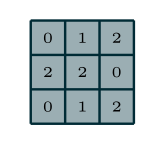
然后对一个5*5的特征图利用滑动窗口法进行卷积操作,padding=0,stride=1,kernel size=3,所以最后得到一个3*3的特征图:
那么上采样呢?则是这样的,我们假定输入只是一个2*2的特征图,输出则是一个4*4的特征图,我们首先将原始2*2的map进行周围填充pading=2的操作,笔者查阅了很多资料才知道,这里周围都填充了数字0,周围的padding并不是通过神经网络训练得出来的数字。然后用一个kernel size=3,stride=1的感受野扫描这个区域,这样就可以得到一个4*4的特征图了!: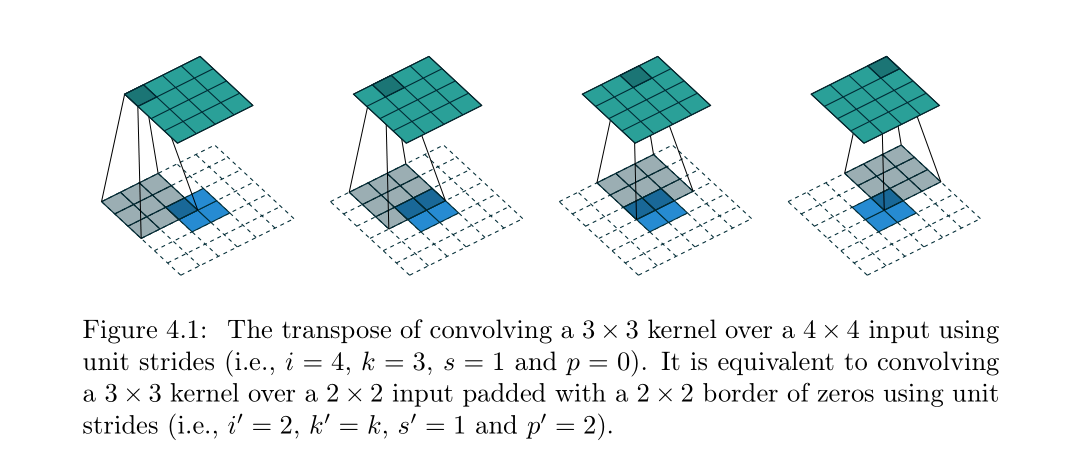
我们甚至可以把这个2*2的feature map,每一个像素点隔开一个空格,空格里的数字填充为0,周围的padding填充的数字也全都为零,然后再继续上采样,得到一个5*5的特征图,如下所示:
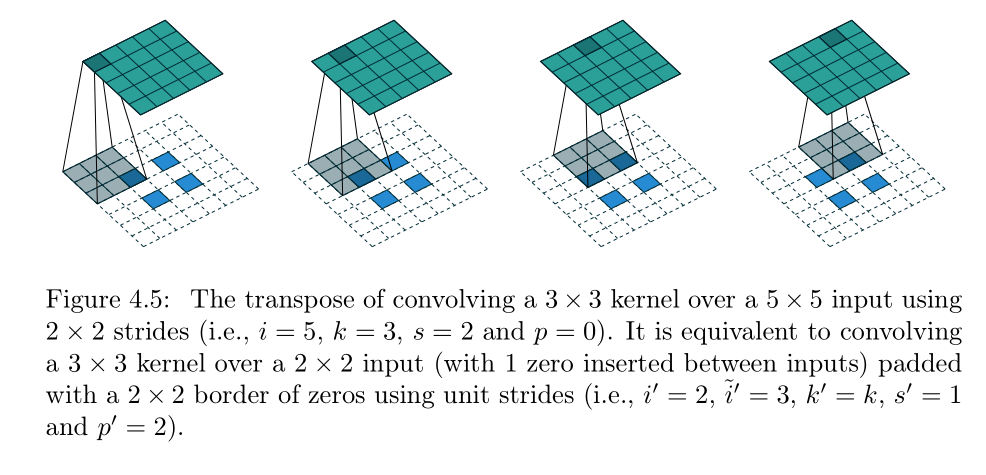
这样咱们的反卷积就完成了。那么什么是1*1卷积呢?
四.1*1卷积
在我们的卷积神经网络前向传播的过程当中,最后是一个N*N*21的输出,这个21是可以我们进行人为通过1*1卷积定义出来的,这样我们才能够得到一个21个类别,每个类别出现的概率,最后输出和原图图像大小一致的那个特征图,每个像素点上都有21个channel,表示这个像素点所具有的某个类别输出的概率值。吴恩达教授在讲解卷积神经网络的时候,用到了一张十分经典的图像来表示1*1卷积: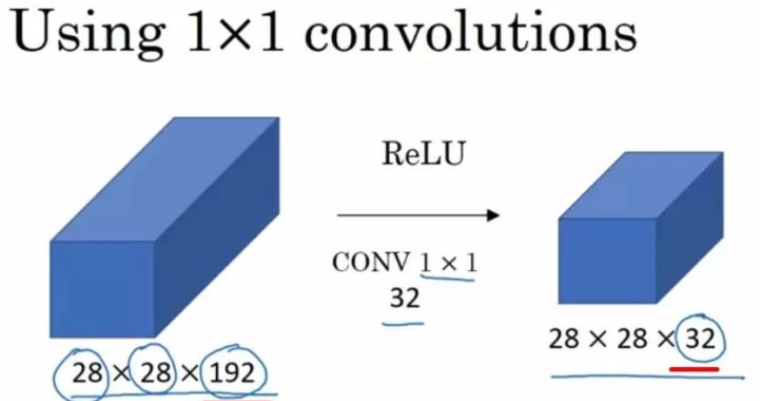
原本的特征图长宽为28,channel为192,我们可以通过这种卷积,使用32个卷积核将28*28*192变成一个28*28*32的特征图。在使用1*1卷积时,得到的输出长款保持不变,channel数量和卷积核的数量相同。可以用抽象的3d立体图来表示这个过程:
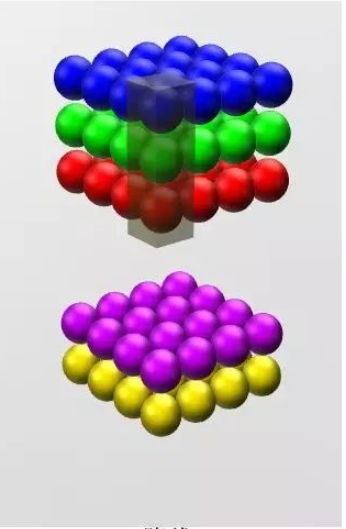
因此我们可以通过控制卷积核的数量,将数据进行降维或者升维。增加或者减少channel,但是feature map的长和宽是不会改变的。我们在全卷积神经网络(FCN)正向传播,下采样的最后一步(可以查看本博客的第一张图片)就是将一个N*N*4096的特征图变成了一个N*N*21的特征图。
五.全卷积神经网络的跳级实现(skip)
我们如果直接采用首先卷积,然后上采样得到与原图尺寸相同特征图的方法的话,进行语义分割的效果经过实验是不太好的。因为在进行卷积的时候,在特征图还比较大的时候,我们提取到的图像信息非常丰富,越到后面图像的信息丢失得就越明显。我们可以发现经过最前面的五次卷积和池化之后,原图的分别率分别缩小了2,4,8,16,32倍。对于最后一层的的图像,需要进行32倍的上采样才能够得到和原图一样的大小,但仅依靠最后一层图像做上采样,得到的结果还是不太准确,一些细节依然很不准确。因此作者采用了跳级连接的方法,即将在卷积的前几层提取到的特征图分别和后面的上采样层相连,然后再相加继续网上往上上采样,上采样多次之后就可以得到和原图大小一致的特征图了,这样也可以在还原图像的时候能够得到更多原图所拥有的信息。如下图所示:
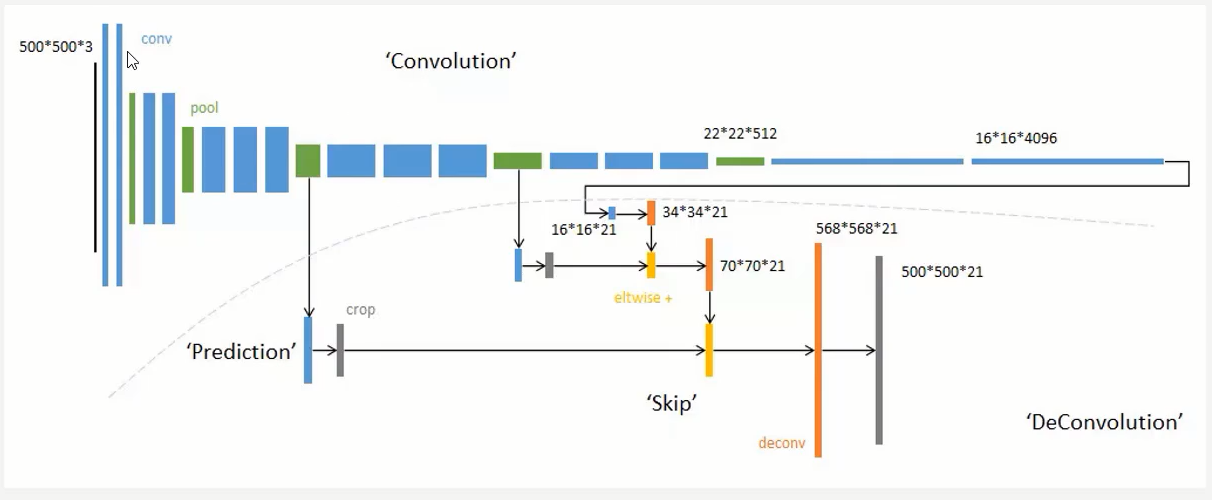
作者最先提出的跳级连接是把第五层的输出进行上采样,然后和池化层4的预测相结合起来,最后得到原图的策略,这个策略叫做FCN-16S,之后又尝试了和所有池化层结合起来预测的方法叫做FCN-8S,发现这个方法准确率是最高的。如下图所示:
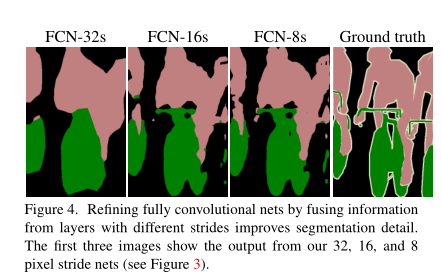
Ground Truth表示原始图像的人为标注,前面的都是神经网络做出的预测。跳级连接,我们这类给出的原图的大小是500*500*3,这个尺寸无所谓,因为全卷积神经网络可接受任意尺寸大小的图片。我们首先从前面绿色刚刚从池化层做完maxpool的特征图上做一次卷积然后,然后再把下一个绿色的特征图做卷积,最后把16*16*21,已经做完1*1卷积的输出,把这个三个输出相加在一起,这样就实现了跳级(skip)输入的实现,再把这几个输入融合之后的结果进行上采样,得到一个568*568*21的图,将这个图通过一个softmax层变成500*500*21的特征图,因此图像的长宽和原图一模一样了,每一个像素点都有21个概率值,表示这个像素点属于某个类别的概率,除了和原图的channel不同之外没啥不同的。
然后我们来看基于Tensorflow的代码实现。
六.Tensorflow代码实现全卷积神经网络
首先导包并读取图片数据:
import tensorflow as tf import matplotlib.pyplot as plt import numpy as np import os import glob images=glob.glob(r"F:\UNIVERSITY STUDY\AI\dataset\FCN\images\*.jpg") #然后读取目标图像 anno=glob.glob(r"F:\UNIVERSITY STUDY\AI\dataset\FCN\annotations\trimaps\*.png")
glob库可以用于读取本地的图片并用来制作每一个batch的数据,我把数据集放在了F:\UNIVERSITY STUDY\AI\dataset\FCN\,这个文件夹下。
幂image文件夹用于装载训练集的图片,annatation文件夹用于装载人们标注边界的数据集。
标注的图片显示如下:
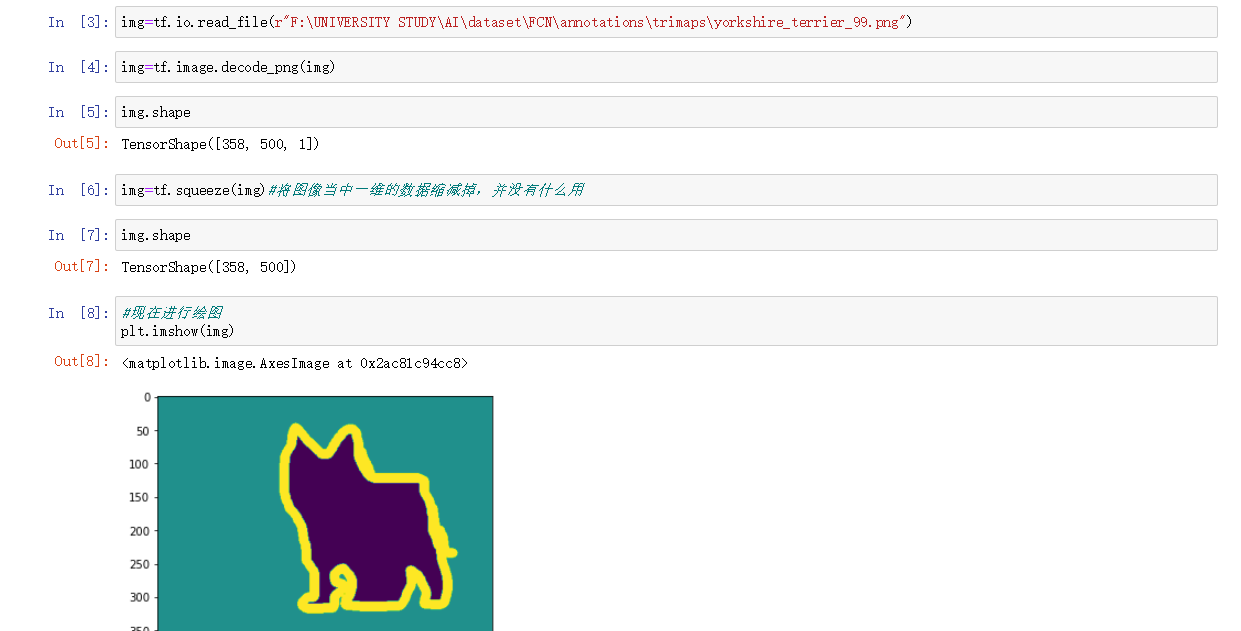
原始图是一个小狗的图片,原始图在下面: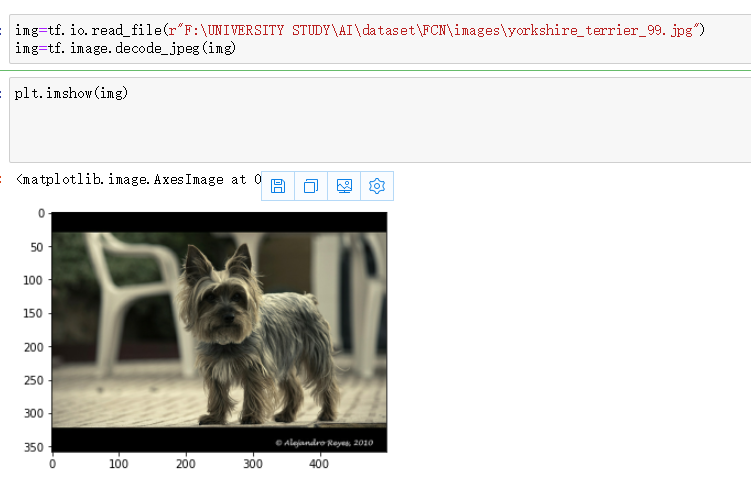
然后制作dataset,batch数据,以及读取图片文件的函数,包括png和jpg分别进行解析为三维矩阵:
#现在对读取进来的数据进行制作batch np.random.seed(2019) index=np.random.permutation(len(images)) images=np.array(images)[index] anno=np.array(anno)[index] #创建dataset dataset=tf.data.Dataset.from_tensor_slices((images,anno)) test_count=int(len(images)*0.2) train_count=len(images)-test_count data_train=dataset.skip(test_count) data_test=dataset.take(test_count) def read_jpg(path): img=tf.io.read_file(path) img=tf.image.decode_jpeg(img,channels=3) return img def read_png(path): img=tf.io.read_file(path) img=tf.image.decode_png(img,channels=1) return img #现在编写归一化的函数 def normal_img(input_images,input_anno): input_images=tf.cast(input_images,tf.float32) input_images=input_images/127.5-1 input_anno-=1 return input_images,input_ann #加载函数 def load_images(input_images_path,input_anno_path): input_image=read_jpg(input_images_path) input_anno=read_png(input_anno_path) input_image=tf.image.resize(input_image,(224,224)) input_anno=tf.image.resize(input_anno,(224,224)) return normal_img(input_image,input_anno) data_train=data_train.map(load_images,num_parallel_calls=tf.data.experimental.AUTOTUNE) data_test=data_test.map(load_images,num_parallel_calls=tf.data.experimental.AUTOTUNE) #现在开始batch的制作 BATCH_SIZE=3#根据显存进行调整 data_train=data_train.repeat().shuffle(100).batch(BATCH_SIZE) data_test=data_test.batch(BATCH_SIZE)
然后我们使用VGG16进行卷积操作,同时使用imagenet的预训练模型进行迁移学习,搭建神经网络和跳级连接:
conv_base=tf.keras.applications.VGG16(weights='imagenet', input_shape=(224,224,3), include_top=False) #现在创建子model用于继承conv_base的权重,用于获取模型的中间输出 #使用这个方法居然能够继承,而没有显式的指定到底继承哪一个模型,确实神奇 #确实是可以使用这个的,这个方法就是在模型建立完之后再进行的调用 #这样就会继续自动继承之前的网络结构 #而如果定义 sub_model=tf.keras.models.Model(inputs=conv_base.input, outputs=conv_base.get_layer('block5_conv3').output) #现在创建多输出模型,三个output layer_names=[ 'block5_conv3', 'block4_conv3', 'block3_conv3', 'block5_pool' ] layers_output=[conv_base.get_layer(layer_name).output for layer_name in layer_names] #创建一个多输出模型,这样一张图片经过这个网络之后,就会有多个输出值了 #不过输出值虽然有了,怎么能够进行跳级连接呢? multiout_model=tf.keras.models.Model(inputs=conv_base.input, outputs=layers_output) multiout_model.trainable=False inputs=tf.keras.layers.Input(shape=(224,224,3)) #这个多输出模型会输出多个值,因此前面用多个参数来接受即可。 out_block5_conv3,out_block4_conv3,out_block3_conv3,out=multiout_model(inputs) #现在将最后一层输出的结果进行上采样,然后分别和中间层多输出的结果进行相加,实现跳级连接 #这里表示有512个卷积核,filter的大小是3*3 x1=tf.keras.layers.Conv2DTranspose(512,3, strides=2, padding='same', activation='relu')(out) #上采样之后再加上一层卷积来提取特征 x1=tf.keras.layers.Conv2D(512,3,padding='same', activation='relu')(x1) #与多输出结果的倒数第二层进行相加,shape不变 x2=tf.add(x1,out_block5_conv3) #x2进行上采样 x2=tf.keras.layers.Conv2DTranspose(512,3, strides=2, padding='same', activation='relu')(x2) #直接拿到x3,不使用 x3=tf.add(x2,out_block4_conv3) #x3进行上采样 x3=tf.keras.layers.Conv2DTranspose(256,3, strides=2, padding='same', activation='relu')(x3) #增加卷积提取特征 x3=tf.keras.layers.Conv2D(256,3,padding='same',activation='relu')(x3) x4=tf.add(x3,out_block3_conv3) #x4还需要再次进行上采样,得到和原图一样大小的图片,再进行分类 x5=tf.keras.layers.Conv2DTranspose(128,3, strides=2, padding='same', activation='relu')(x4) #继续进行卷积提取特征 x5=tf.keras.layers.Conv2D(128,3,padding='same',activation='relu')(x5) #最后一步,图像还原 preditcion=tf.keras.layers.Conv2DTranspose(3,3, strides=2, padding='same', activation='softmax')(x5) model=tf.keras.models.Model( inputs=inputs, outputs=preditcion )
编译和fit模型:
model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc']#这个参数应该是用来打印正确率用的,现在终于理解啦啊 ) model.fit(data_train, epochs=1, steps_per_epoch=train_count//BATCH_SIZE, validation_data=data_test, validation_steps=train_count//BATCH_SIZE)
输出:
Train for 1970 steps, validate for 1970 steps 1969/1970 [============================>.] - ETA: 1s - loss: 0.3272 - acc: 0.8699WARNING:tensorflow:Your input ran out of data; interrupting training. Make sure that your dataset or generator can generate at least `steps_per_epoch * epochs` batches (in this case, 1970 batches). You may need to use the repeat() function when building your dataset. 1970/1970 [==============================] - 3233s 2s/step - loss: 0.3271 - acc: 0.8699 - val_loss: 0.0661 - val_acc: 0.8905
结果只用了一个epoch,像素精确度就已经达到了百分之89了,是不是很神奇呢?嘿嘿
这就是全卷积神经网络FCN的所有知识啦!希望您看了有所收获,小编写得也挺辛苦的,如果觉得还行的话,不要忘了点击右下角的“推荐”和左下角的“关注”呀!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号