阿里天池文本分类竞赛task2:初始数据分析
在这一块当中我们稍微看看就好,不需要了解得太详细。进行文本数据分析往往是一个数据科学家需要具有的良好习惯,因为在对数据分析之前,需要对数据具有初步的了结。
首先我们导入代码,开始分析数据:
import pandas as pd train_df = pd.read_csv('train_set.csv', sep='\t')
这样我们就将csv文件变成了dataframe,就可以根据开始做各种各样的数据分析了。
现在我们先来看看数据长什么样:
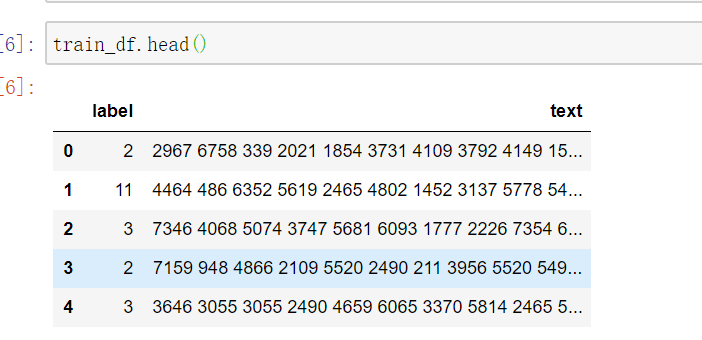
然后查看各个文本分类的数量如何,代码和可视化后的状态如下:
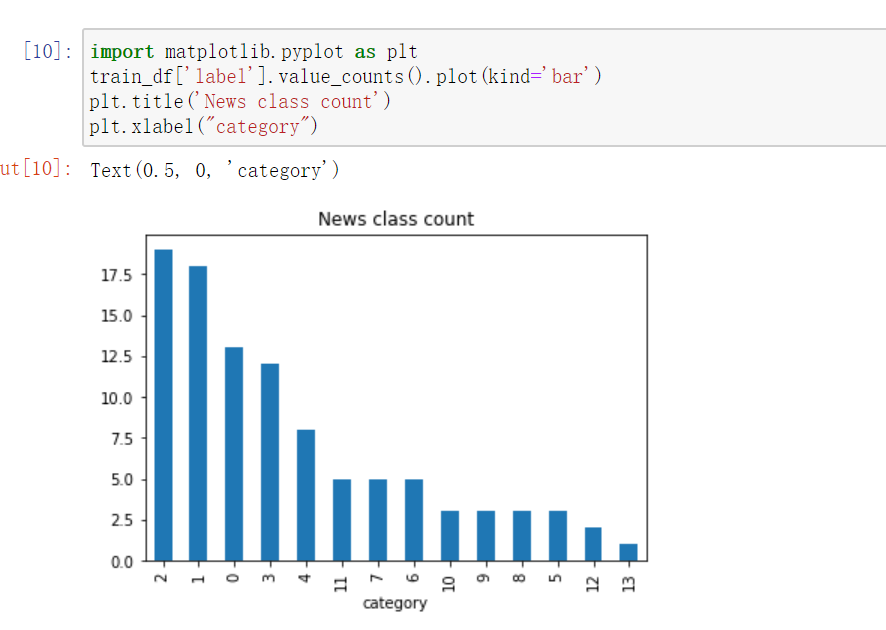
的解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号