Tensorflow实现对fashion mnist(衣服,裤子等图片)数据集的softmax分类
首先我们要明确的是下面我们讲解的是一个很基础的神经网络,因为我们只是为了通过下面这个实例来为大家解释如何使用tensorflow2.0这个框架。整个神经网络的架构是首先是flatten层(把图片从二维转化为一维),然后经过一系列的全连接网络层,中间穿插着一些dropout层来避免过拟合,最后达到softmax层实现多分类。在整个神经网络当中并没有用到卷积神经网络,卷积神经网络会在我后面的博文当中写出。
代码如下:
import tensorflow as tf import pandas as pd import numpy as np import matplotlib.pyplot as plt #这一次我们使用softmax模型来进行对衣服,裤子,鞋子,包包图像的分类 (train_image,train_label),(test_image,test_label)=tf.keras.datasets.fashion_mnist.load_data()
加载训练以及测试的图片和label标签完毕,然后查看训练集图片的shape:
train_image.shape
输出:
(60000, 28, 28)
使用plt可以查看单个图片的式样:
#用plt交互展示出其中的一个图像 plt.imshow(test_image[4])
输出如下:
进行数据的归一化,同时搭建神经网络:
train_image=train_image/255 test_image=test_image/255#进行数据的归一化,加快计算的进程 model=tf.keras.Sequential() model.add(tf.keras.layers.Flatten(input_shape=(28,28)))#因为每一个神经元里只有一个数字,一共有15个input因此这里写15, model.add(tf.keras.layers.Dense(200,activation="relu")) model.add(tf.keras.layers.Dropout(0.5))#添加dropout层,抑制过拟合的效果。 model.add(tf.keras.layers.Dense(300,activation="relu")) model.add(tf.keras.layers.Dropout(0.5)) model.add(tf.keras.layers.Dense(10,activation="softmax")) #在最后一个节点处使用softmax,因为有十个分类,这里都写错了,粗心啊! #然后确立optimizer model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss="sparse_categorical_crossentropy", metrics=['acc'] ) #如果l物体的label使用了顺序编码,那么我们就使用sparse_categorical_crossentropy的loss,使用了独热编码,则使用 #categorical_crossentropy的loss
编译模型:
history=model.fit(train_image,train_label,epochs=15,validation_data=(test_image,test_label))
输出:
Train on 60000 samples, validate on 10000 samples Epoch 1/15 60000/60000 [==============================] - 5s 81us/sample - loss: 0.6924 - acc: 0.7534 - val_loss: 0.5699 - val_acc: 0.7996 Epoch 2/15 60000/60000 [==============================] - 4s 72us/sample - loss: 0.6461 - acc: 0.7688 - val_loss: 0.5634 - val_acc: 0.8051 Epoch 3/15 60000/60000 [==============================] - 4s 75us/sample - loss: 0.6292 - acc: 0.7754 - val_loss: 0.5536 - val_acc: 0.8108 Epoch 4/15 60000/60000 [==============================] - 4s 73us/sample - loss: 0.6199 - acc: 0.7784 - val_loss: 0.5492 - val_acc: 0.8065 Epoch 5/15 60000/60000 [==============================] - 4s 73us/sample - loss: 0.6223 - acc: 0.7772 - val_loss: 0.5447 - val_acc: 0.8121 Epoch 6/15 60000/60000 [==============================] - 4s 73us/sample - loss: 0.6155 - acc: 0.7783 - val_loss: 0.5331 - val_acc: 0.8164 Epoch 7/15 60000/60000 [==============================] - 4s 73us/sample - loss: 0.6053 - acc: 0.7810 - val_loss: 0.5377 - val_acc: 0.8136 Epoch 8/15 60000/60000 [==============================] - 4s 74us/sample - loss: 0.6100 - acc: 0.7821 - val_loss: 0.5338 - val_acc: 0.8220 Epoch 9/15 60000/60000 [==============================] - 4s 74us/sample - loss: 0.6069 - acc: 0.7830 - val_loss: 0.5387 - val_acc: 0.8169 Epoch 10/15 60000/60000 [==============================] - 4s 74us/sample - loss: 0.6020 - acc: 0.7843 - val_loss: 0.5317 - val_acc: 0.8223 Epoch 11/15 60000/60000 [==============================] - 4s 74us/sample - loss: 0.5986 - acc: 0.7856 - val_loss: 0.5314 - val_acc: 0.8196 Epoch 12/15 60000/60000 [==============================] - 5s 78us/sample - loss: 0.5884 - acc: 0.7900 - val_loss: 0.5329 - val_acc: 0.8188 Epoch 13/15 60000/60000 [==============================] - 5s 76us/sample - loss: 0.5959 - acc: 0.7835 - val_loss: 0.5555 - val_acc: 0.8087 Epoch 14/15 60000/60000 [==============================] - 4s 74us/sample - loss: 0.5868 - acc: 0.7871 - val_loss: 0.5269 - val_acc: 0.8304 Epoch 15/15 60000/60000 [==============================] - 5s 75us/sample - loss: 0.5880 - acc: 0.7862 - val_loss: 0.5301 - val_acc: 0.8230
模型训练完毕,现在把训练的过程以及结果用plt画出来,突出acc准确率和loss(损失的大小):
history.history.keys() plt.plot(history.epoch,history.history.get('loss'),label="loss") plt.plot(history.epoch,history.history.get('val_loss'),label="val_loss") plt.legend()
图像如下: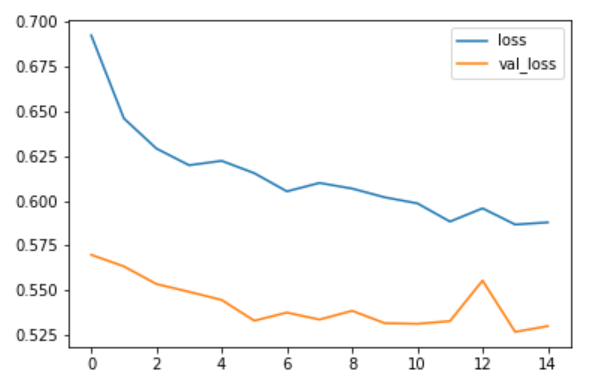
模型准确率的图像如下:
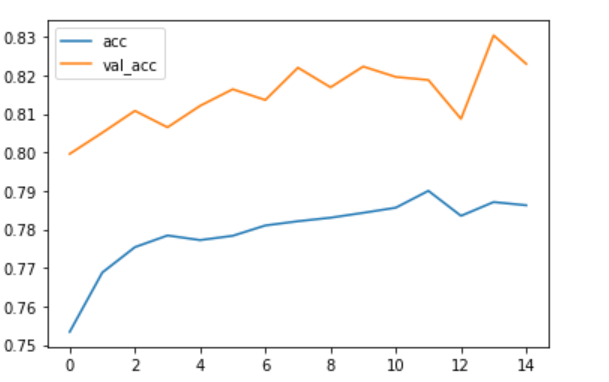
从中可以看出,验证集的准确率在不断上升,虽然中途比较跌宕起伏,但是总体有上升的趋势,因此这个模型可以继续进行迭代增加模型的验证集准确率(没有过拟合的缘故)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号