进程(三)--- 线程
多进程架构
知道了进程的切换和调度之后,就可以展开了解进程的父子关系。在linux操作系统中进程是存在父子关系的,其中一开始存在的进程有三个:
0号进程是scheduler1号进程是init/systemd(所有user thread的祖先)2号进程是[kthreadd](所有kernel thread的父进程)
PPID 为当前进程的父进程id,从以下两张图可以看出1号进程和2号进程的父进程是0进程剩下的3,4,6号进程的父进程是2号进程。661,662,666号进程的父进程是1号进程。


创建子进程
在linux 中提供了一个 fork 函数来创建子进程,可以通过man fork 来查看如何使用,接下来可以通过一段代码来理解fork.
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/wait.h>
int main(int argc ,char const *argv[]){
pid_t cid;//child pid
int value = 100;
printf("Before fork process id : %d\n",getpid());
// fork 函数执行之后会创建一个和父进程一模一样的子进程(pid和ppid 不一样),子进程代码会执行fork 之后的代码
// 如果cid 不为0,代表fork 函数由返回值,说明当前代码段是运行在父进程,如果cid为0,代表cid就是个初始值
// 为子进程执行的代码
cid = fork();
if (cid==0){
printf("Chid process id (my parent pid is %d) : \n%d\n",getppid(),getpid());
for (int i = 0; i < 3; i++){
printf("hello value is (%d)\n",value--);
}
}else{
printf("parent process id : %d\n",getpid());
for (int i = 0; i < 3; i++){
printf("hello value is (%d)\n",value++);
}
wait(NULL); //等待子进程结束返回
}
return 0;
}
代码执行结果
Before fork process id : 937310
parent process id : 937310
hello value is (100)
hello value is (101)
hello value is (102)
Chid process id (my parent pid is 937310) :
937311
hello value is (100)
hello value is (99)
hello value is (98)
从执行结果可以看出,fork 后创建的子进程是完全拷贝了父进程的数据,同时并发的执行fork()函数之后的代码。

优劣
优势
- fork 创建子进程的方式可以异步的处理一些程序功能,比如当执行的代码需要将数据写入磁盘文件,由于写磁盘文件的速度是远远慢于cpu的,此时创建一个子进程来处理这些事情,处理完后告诉父进程,父进程可以接着去干其他的事情。
- 当父进程挂了不影响子进程的执行操作
劣势
- 需要拷贝和存储的资源比较多,fork 进程需要将整个进程的内存全部拷贝一份,进程切换消耗的资源是很多的。
线程
从上面的进程fork() 可以看出,fork出的子进程基本上全部信息都是一样的,只是代码执行流不一样(cpu会再两个进程的代码指令上来回执行流程)。那么我们只要让cpu 再一个进程里面来回执行不同的代码,这样不就创建了多个执行流了吗?
用上面的例子就是,当写文件的时候cpu会去执行写文件的代码但是不会一直阻塞再这段代码上,当执行了一小会后会保存这段代码的上下文,转而执行主进程要执行的逻辑。
一个进程中的多个执行流就是进程中的线程
线程的定义
单线程进程和多线程进程
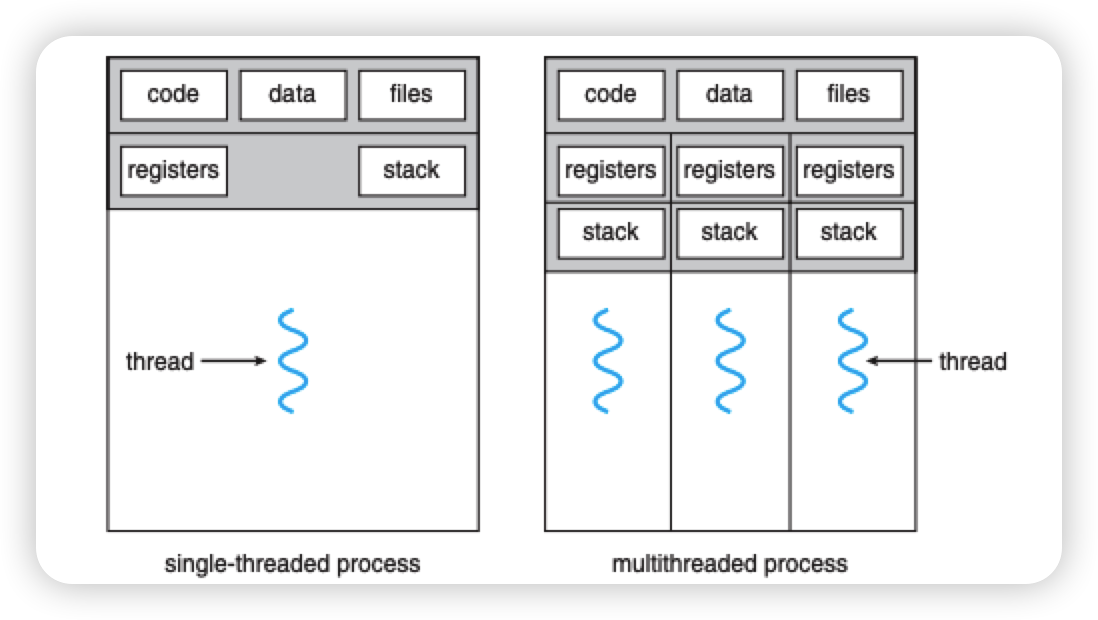
从上图可以看出多线程进程和单线程进程的差异在于,多线程进程,每一个线程拥有独立的栈空间和寄存器值,其他进程中的代码段,数据段,打开的文件等信息是共享的。其中registers和files 都是属于PCB中的内容.
我们知道 stack保存的是程序的局部变量, registers 保存的是进程执行过程中的临时的数据和结果.这些都是代码执行过程中所需要的数据.
代码段,数据段,打开的文件等信息是共享的好处是,这样不需要跨空间去访问资源。又因为是共享的,因此再多线程操作的时候,全局变量的修改更新需要加锁防止数据竞争从而出现数据不一致。
优势
-
响应性: 当一个web 服务正在运行,这个时候一个客户端请求过来查询某个商品还有多少库存,同时又有一个客户端来查询相同的商品库存,多线程机制可以在一个进程里面创建多个线程来处理请求,而多进程需要fork一份相同的进程来处理事件,相对来说响应没有那么实时。
-
资源共享:线程之间代码段,数据段,打开的文件这些数据是共享的,当需要访问这些数据的时候是直接可以再内存中访问的,但是如果是多进程的话,由于资源全部是隔离的,想要互相访问则需要进程间进行通信。
-
经济: 父进程创建子进程的时候是复制整个内存空间的,这样就造成了不必要的内存浪费,而多线程只是栈数据和寄存器数据是单独的,相对来说更加节省内存。同时因此线程间的切换也比进程切换更加的经济
-
可伸缩性: 多核处理器体系结构,因为线程可以在多处理核上并行运行,不管有多少可用cpu,单线程进程只能运行在一个cpushang
多线程模型
线程在操作系统中也分为用户线程或内核线程,用户线程在用户空间,他的管理不需要内核的支持,而内核线程需要操作系统支持和管理。
用户线程和内核线程之间存在某种关系,如下:
多对一模型
映射多个用户级线程到一个内核线程。线程管理是由用户共建的线程过来完成的。
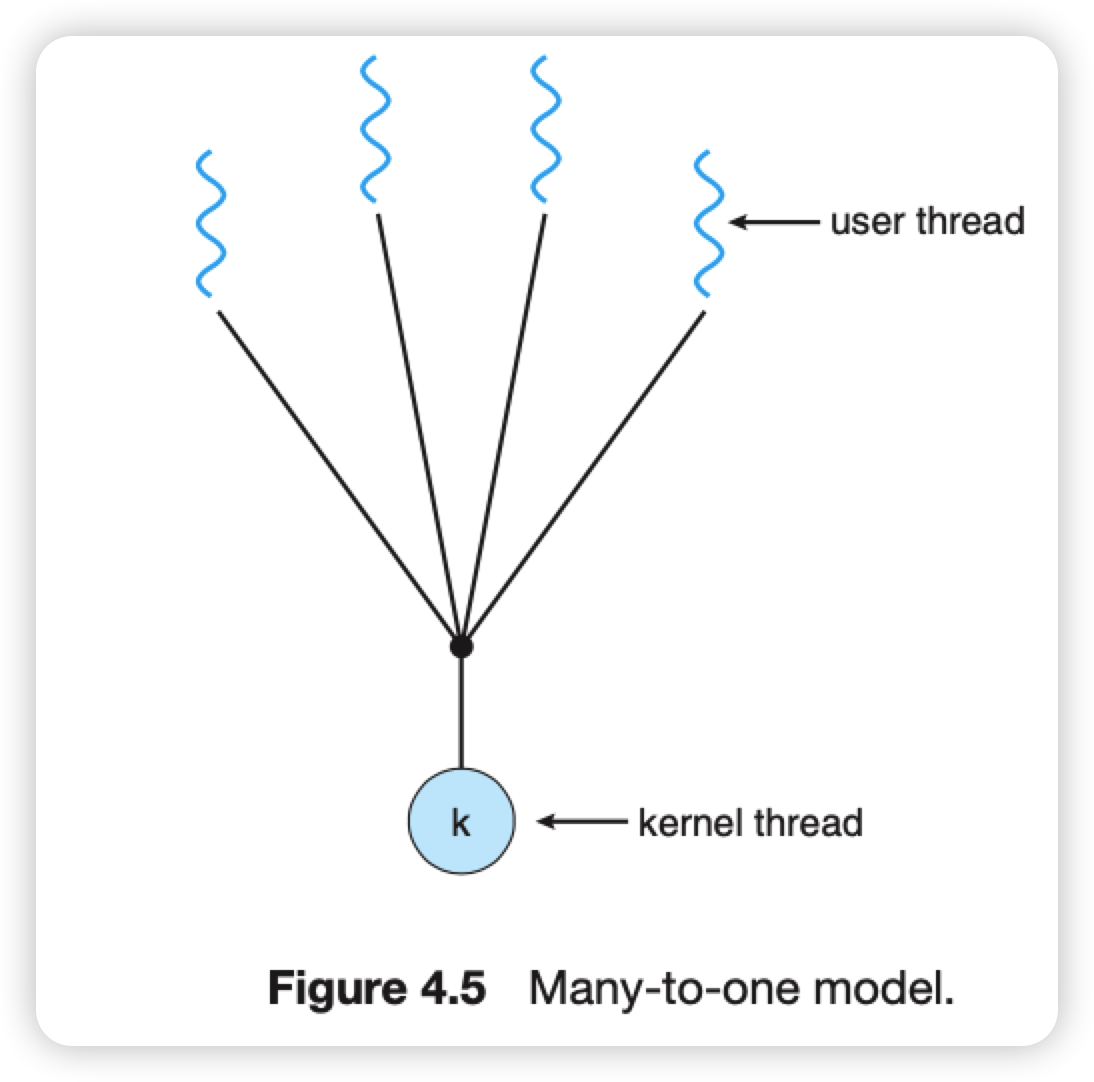
缺点:
- 虽然是多线程的,但是实际上只有一个内核线程在执行,因此一个线程阻塞,那么进程还是会阻塞。
- 在多核cpu上,多线程也不能并行运行,因为一个时间只有一个线程能访问内核。
一对一模型
映射每个用户线程到一个内核线程
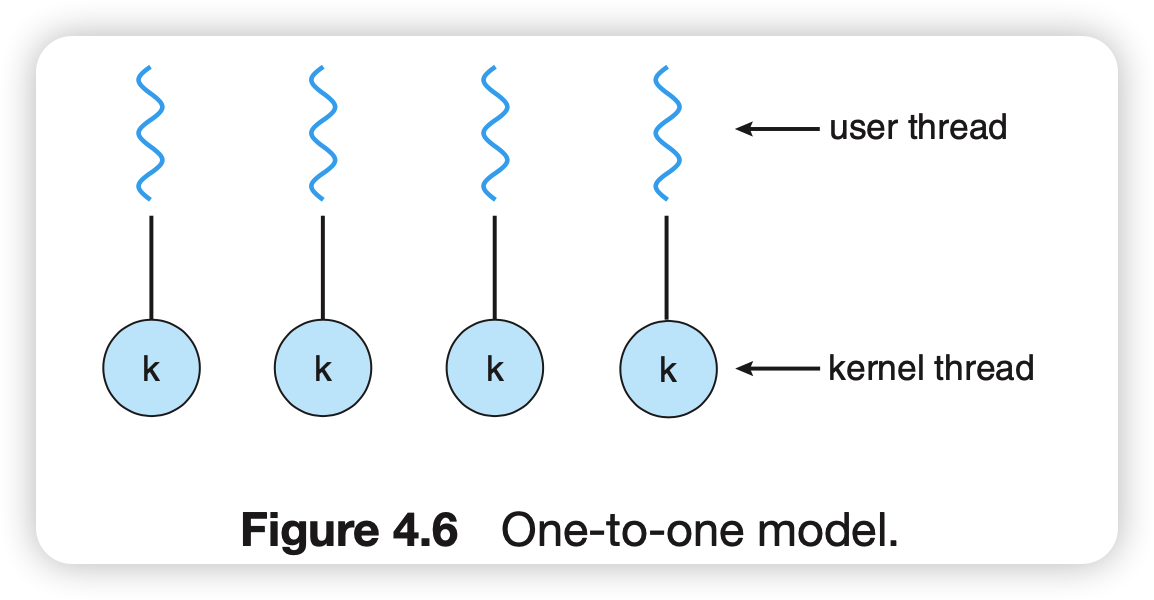
这种方式就解决了多对一模型中线程模型阻塞会导致进程阻塞的缺点,同时也可以在多个cpu上并行执行。缺点是创建内核线程开销很大,会影响程序性能。因此这种模型限制了系统支持的线程数量。
(linux和windows都是实现的这个模型)
多对多模型
多路复用多个用户级线程到同样多或者更少的内核线程。内核线程数量和特定机器或者应用程序有关。
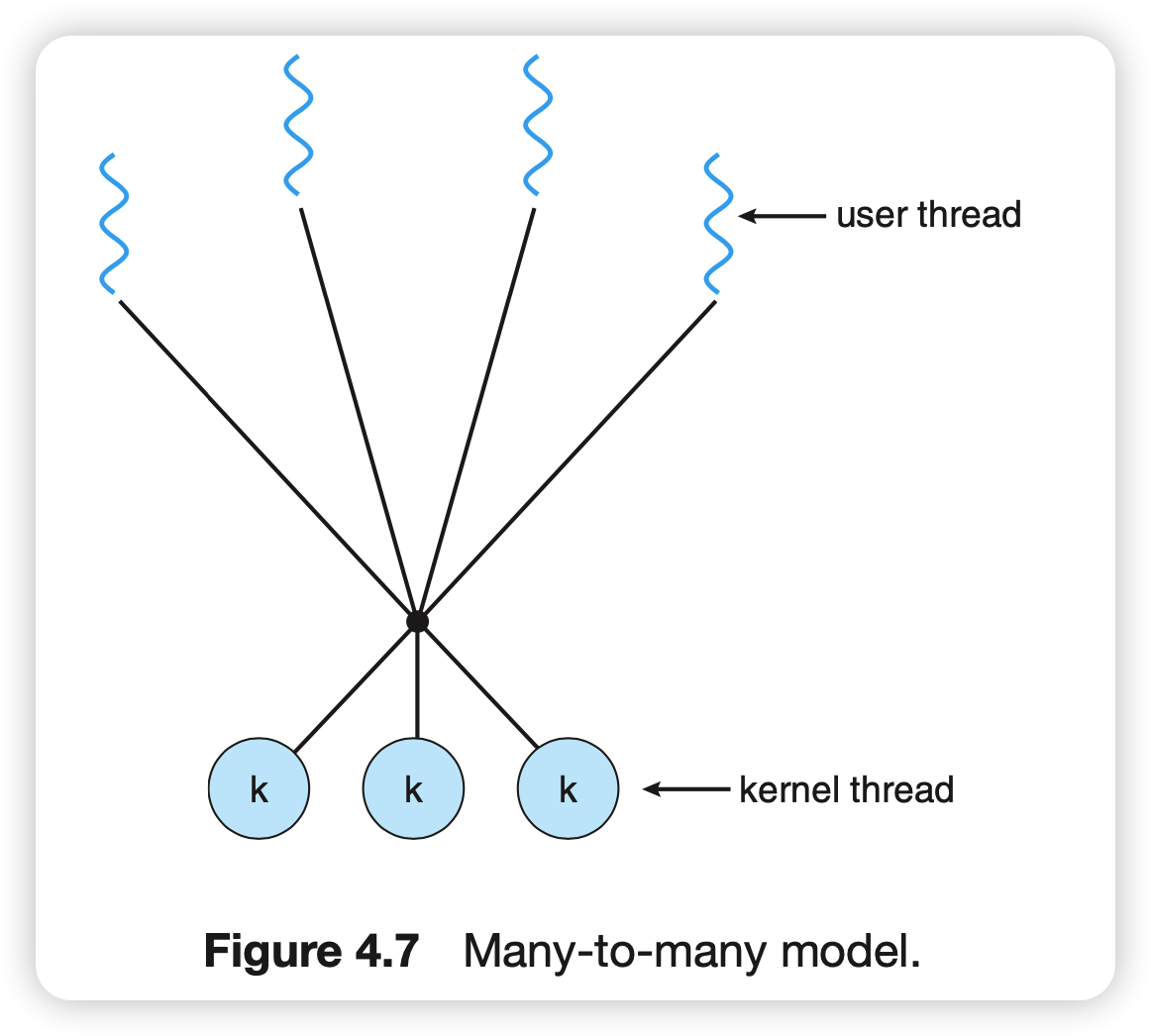
双层模型
多对多模型的变种,允许绑定某个用户线程到一个内核线程。
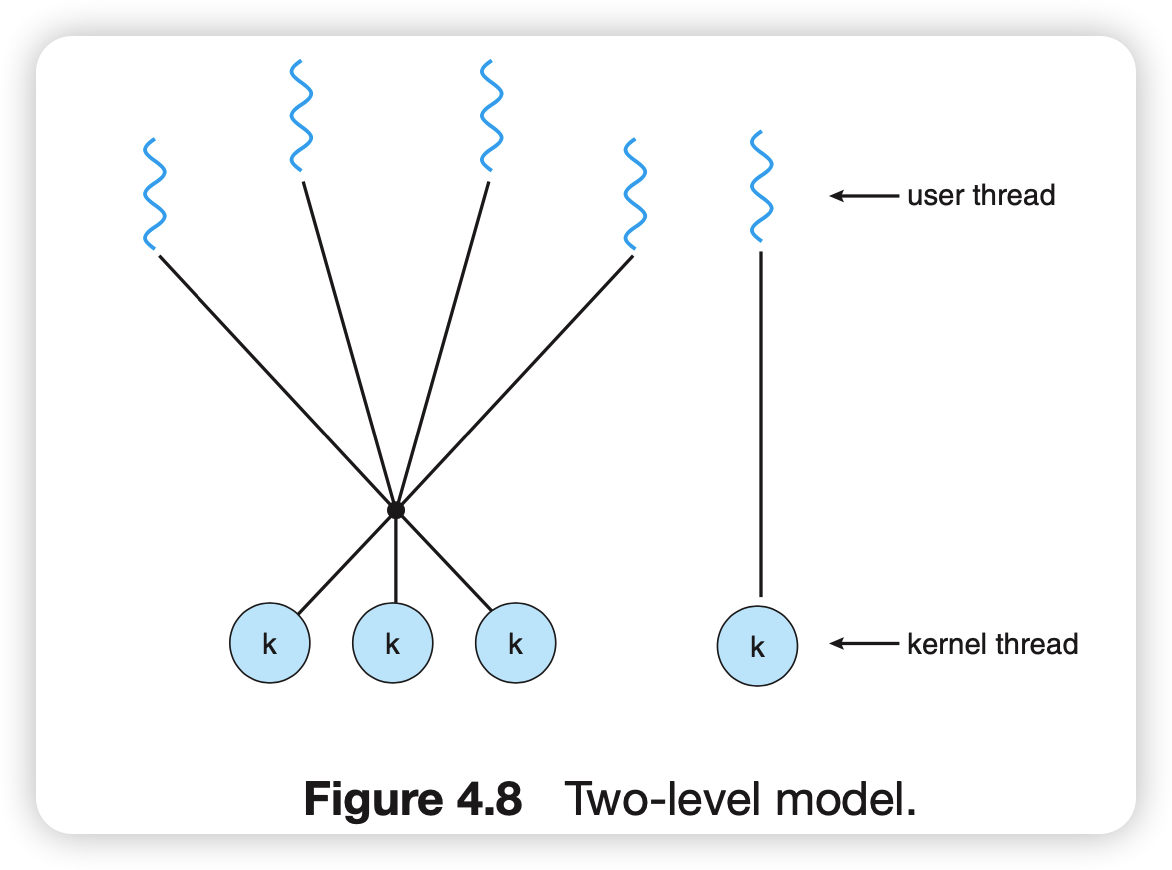
这个模型解决了一对一模型内核线程开销大的问题,但是需要实现一个用户线程和内核线程之间的调度问题。实现起来很复杂。
NGPT 和 NPTL
NGPT:(Next Generation POSIX Threads,下一代POSIX线程)实现的方式就是多对多的问题,但是由于调度的问题,再2003年中NGPT被放弃。
NPTL :一对一模型(Native POSIX Thread Library)
NPTL首次是随Red Hat Linux 9发表的。此前老式的Linux POSIX线程偶尔会发生系统无法产生线程的毛病,这个毛病的原因是因为在新线程开始的时候系统没有借机先占。当时的Windows系统对这个问题的解决比较好。Red Hat在关于Red Hat Linux 9上的Java的网页上发表了一篇文章称NPTL解决了这个问题。
线程创建
线程库也分为两类:
- 用户空间提供: 没有内核支持的情况下完全在用户空间中提供一个库,所有线程库支持的数据结构都存在用户内存空间。所以调用库中的函数会导致用户空间中的本地函数调用,而不是系统调用
- 内核提供:由操作系统直接支持,线程库的数据结构和代码都在内核空间,调用库中的函数会导致系统调用
三种线程库:
POSIX Pthreads: POSIX 标准的线程扩展,可以作为用户级或内核级库提供。
Windows: 提供的是内核线程库
Java: 由java 进程直接创建和管理,但是由于jvm 一般都是运行在操作系统上的,所以java的线程库API通常使用主机系统上可用的线程库来实现.因此如果jvm 再windows 上则使用windos的api线程库,如果在linux 上,则使用Pthreads。
代码
实现一个程序,输入一个数字,计算这个数字从0开始的累加和
pthread.c
#include <pthread.h>
#include <stdio.h>
int sum; /* this data is shared by the thread(s) */
void *runner(void *param); /* threads call this function */
int main(int argc, char *argv[])
{
pthread_t tid; /* the thread identifier */
pthread_attr_t attr; /* set of thread attributes */
if (argc != 2) {
fprintf(stderr,"usage: a.out <integer value>\n");
return -1;
}
if (atoi(argv[1]) < 0) {
fprintf(stderr,"%d must be >= 0\n",atoi(argv[1]));
return -1;
}
/* get the default attributes,dynamic memory space is allocated for the attribute object,*/
pthread_attr_init(&attr);
/* create the thread */
pthread_create(&tid,&attr,runner,argv[1]);
/* wait for the thread to exit */
pthread_join(tid,NULL);
printf("sum = %d\n",sum);
}
/* The thread will begin control in this function */
void *runner(void *param)
{
int i, upper = atoi(param);
sum = 0;
for (i = 1; i <= upper; i++)
sum += i;
pthread_exit(0);
}
编译执行:
gcc -pthread -o pthread pthread.c
./pthread
pthread create()函数创建一个线程,他需要传入线程标识符(tid),属性(attr),线程将要执行的方法(runner)和传递给方法的参数pthread_join函数等待子进程退出再继续执行主进程相应的代码。这里主进程就是main 函数,子进程执行的就是runner 函数。他们共同操作全局变量sum
多线程问题
fork()和exec()
我们都知道fork创建进程的时候,并没有真正的copy内存(听着好像矛盾了,资源的赋值为什么有没有真正的赋值呢?),因为我们知道,对于fork来讲,有一个很讨厌的东西叫exec系列的系统调用,它会勾引子进程另起炉灶。如果创建子进程就要内存拷贝的的话,一执行exec,辛辛苦苦拷贝的内存又被完全放弃了。由于fork()后会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,处于效率考虑,linux中引入了“写时复制技术-Copy-On-Write”。
换言之,在fork()之后exec之前两个进程用的是相同的物理空间(内存区),先把页表映射关系建立起来,并不真正将内存拷贝。
子进程的代码段、数据段、堆栈都是指向父进程的物理空间,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。当父进程中有更改相应段的行为发生时,如进程写访问,再为子进程相应的段分配物理空间,如果不是因为exec,内核会给子进程的数据段、堆栈段分配相应的物理空间(至此两者有各自的进程空间,互不影响),而代码段继续共享父进程的物理空间(两者的代码完全相同)。
而如果是因为exec,由于两者执行的代码不同,子进程的代码段也会分配单独的物理空间。fork时子进程获得父进程数据空间、堆和栈的复制所以变量的地址(当然是虚拟地址)是一样的。
以上摘自 https://blog.csdn.net/gogokongyin/article/details/51178257
假如程 序内的某个线程调用fork()系统调用,那么新进程会复制所有线程还是只是复制这一个线程到进程中?一些 UNIX 系统选择了两种版本的 fork(),一种复制所有线程,另一种仅复制调用 fork() 系统调用的线程。
我们知道,如果一个线程调用exec() 系统调用,exec() 参数指定的程序将会取代整个进程,包括所有线程。
- 如果调用fork()分叉之后立即调用exec(),那么没有必要复制所有线程,因为exec()参数指定的程序比如(
ls -l) 会替换整个进程。所有复制 调用线程就可以 - 如果不调用exec() ,新进程会重复所有线程
fork() 和clone()
系统调用fork()是无参数的,而clone()则带有参数。fork()是全部复制,而clone()是则可以将父进程资源有选择地复制给子进程,而没有复制的数据结构则通过指针的复制让子进程共享.因此如果调用 clone()不带任何参数,就不会发生任何共享,所以就会出现类似系统调用 fork()的功能
下图为调用clone()时传递的一些标志


 浙公网安备 33010602011771号
浙公网安备 33010602011771号