

存储器结构层次(三)
Generic Cache Memory Organization:
这个结构可以用一个四元组表示:
(S, E, B, m)
图示:

S表示set的数量,标志了s的长度。如果在address里的set index也为3,那么应该把这个缓存放在Set3
B代表cache block的大小,标志了b的长度。如果在adresss里block offset为5,那么应该将缓存放在B5。
E反应在tag上,t的值要和E吻合
m代表地址长度
所以知道了S,B,m,也就知道了address各段的划分长度
直接映射高速缓存的定义:
Caches are grouped into different classes based on E, the number of cache lines per set. A cache with exactly one line per set (E = 1) is known as a direct-mapped cache
举例说明这个问题:
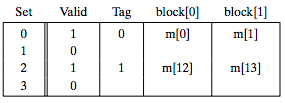
假设(S,E,B,m) = (4,1,2,4),CPU一次读一个字节,开始的时候cache如下:
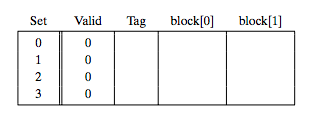
地址0表示为0 00 0,(t,s,b),读地址0的时候,因为s为00,所以Set 0;t=0,所以写入cache之后,Tag为0;又因为b为0,所以块偏移为0,应该放入block[0]:
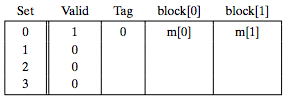
接下来读地址1, cache命中,继续往下走
读地址13:1 10 1 Set 2, 偏移1,同时将Tag置为1,如下图所示:
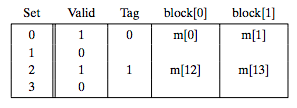
读地址8,1 00 0, Set0, 偏移0,Tag1,如下图:
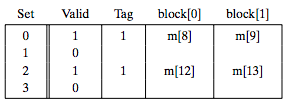
读地址0,情况又回到了最初的时候,如下:
CSAPP为我们总结了当Set确定之后的匹配流程:

Conflict Misses in Direct-Mapped Caches:
前提:Suppose that floats are 4 bytes, that x is loaded into the 32 bytes of contiguous memory starting at address 0, and that y starts immediately after x at address 32. For simplicity, suppose that a block is 16 bytes (big enough to hold four floats) and that the cache consists of two sets, for a total cache size of 32 bytes. We will assume that the variable sum is actually stored in a CPU register and thus does not require a memory reference. Given these assumptions, each x[i] and y[i] will map to the identical cache set(也就是B=16,S=2,m=32):
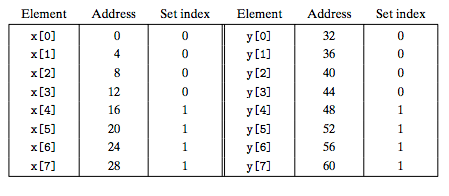
注意由于只有2个set,所以只看地址的s域的最后一位。
这样计算点乘的时候会不断冲突,The term thrashing describes any situation where a cache is repeatedly loading and evicting the same sets of cache blocks.
由于数组x和y是连续存放的,当我们将x,y定义成float x[12], float y[12]的时候,就消除了thrashing
为什么不用高位作为set index的原因:

可见,如果使用高位来做set index,If a program has good spatial locality and scans the elements of an array sequentially, then the cache can only hold a block-sized chunk of the array at any point in time. This is an inefficient use of the cache.
Set Associative Caches:A cache with 1 < E < C/B is often called an E-way set associative cache.
工作流程:Set Selection, Line Matching and Word Selection. 如下图:
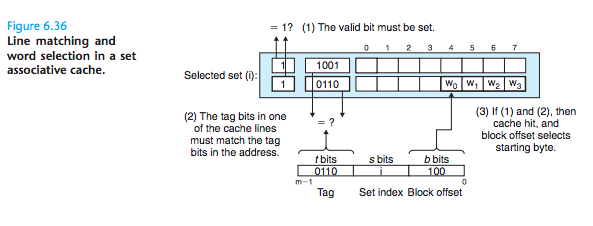
关键: An important idea here is that any line in the set can contain any of the memory blocks that map to that set. So the cache must search each line in the set, searching for a valid line whose tag matches the tag in the address. If the cache finds such a line, then we have a hit and the block offset selects a word from the block, as before.
缓存不命中的情形:
1 Of course, if there is an empty line, then it would be a good candidate. But if there are no empty lines in the set, then we must choose one of the nonempty lines and hope that the CPU does not reference the replaced line anytime soon.
2 Other more sophisticated policies draw on the principle of locality to try to minimize the probability that the replaced line will be referenced in the near future. For example, a least-frequently-used (LFU) policy will replace the line that has been referenced the fewest times over some past time window. A least-recently-used (LRU) policy will replace the line that was last accessed the furthest in the past. All of these policies require additional time and hardware. But as we move further down the memory hierarchy, away from the CPU, the cost of a miss becomes more expensive and it becomes more worthwhile to minimize misses with good replacement policies.

