使用浏览器模拟器获取动态网站数据
抓取静态网站的数据,只是根据需要组合出合适的url列表,之后编写方法spider获取指定url上的数据就可以了。但如果网站是动态的,例如在这个站点“http://www.zgyyjgw.com/front/cn/hospitalPrice”,从源代码中我们可以看出,该站点使用的是javascript与css。我们查询“胰高血糖素试验”的价格,首先需要在“省份”中填入对应的省份,在项目名称中填入“胰高血糖素试验”,点击右侧的查找,会在下侧显示查询到的信息。
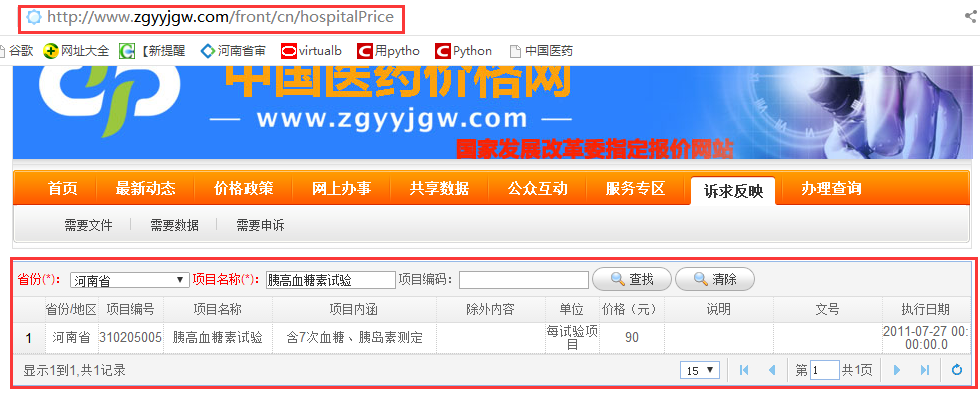
可以注意到,整个过程,浏览器地址栏中一直都是“http://www.zgyyjgw.com/front/cn/hospitalPrice”没有发生改变,所以像静态页面那样通过修改url的方法来获取对应的信息在这里根本就行不通了。
虽然python中的urllib模块中有相应的函数来处理这类动态页面,但过于麻烦,这里我们选用一个简便的方法,使用浏览器模拟器。
在网上下载无界面浏览器PhantomJS,利用pip下载模块selenium(这里推荐版本2.53.6,而不是最新版本,最新版本的selenium不支持PhantomJS),建立main.py,编写涉及和使用到的类与方法,代码如下:
1 from selenium import webdriver 2 from selenium.webdriver.support.select import Select 3 from myLog import MyLog 4 import time 5 import xlwt 6 7 class Item(object): 8 shengfen = None #省份 9 xiangmubianhao = None #项目编号 10 xiangmumingcheng = None #项目名称 11 xiangmuneihan = None #项目内涵 12 chuwaineirong = None #除外内容 13 danwei = None #单位 14 jiage = None #价格 15 shuoming = None #说明 16 wenhao = None #文号 17 zhixingriqi = None #执行日期 18 19 class Get_medicalprice(object): 20 def __init__(self): 21 self.hospitalPriceurl = 'http://www.zgyyjgw.com/front/cn/hospitalPrice' 22 self.log = MyLog() 23 self.filename = u'医疗服务价格.xls'.encode('GBK') 24 self.namelist = self.getname('name.txt') 25 self.hospitallist = self.gethospitalprice(self.hospitalPriceurl,self.namelist) 26 self.savefiletoxls(self.filename,self.hospitallist) 27 28 def getname(self,filename): 29 namelist = [] 30 with open(filename,'r') as fp: 31 s = fp.read() 32 for name in s.split(): 33 namelist.append(name) 34 self.log.info('open namelist success , the length of list is %d' % len(namelist)) 35 return namelist 36 37 def gethospitalprice(self,url,namelist): 38 list_hospitalprice = [] 39 return list_hospitalprice 40 41 def savefiletoxls(self,filename,hospitallist): 42 self.log.info('save data to excel') 43 book = xlwt.Workbook(encoding = 'utf8',style_compression=0) 44 sheet = book.add_sheet(u'医疗服务项目收费') 45 sheet.write(0,0,u'省份'.encode('utf8')) 46 sheet.write(0,1,u'项目编号'.encode('utf8')) 47 sheet.write(0,2,u'项目名称'.encode('utf8')) 48 sheet.write(0,3,u'项目内涵'.encode('utf8')) 49 sheet.write(0,4,u'除外内容'.encode('utf8')) 50 sheet.write(0,5,u'单位'.encode('utf8')) 51 sheet.write(0,6,u'价格'.encode('utf8')) 52 sheet.write(0,7,u'说明'.encode('utf8')) 53 sheet.write(0,8,u'文号'.encode('utf8')) 54 sheet.write(0,9,u'执行日期'.encode('utf8')) 55 for i in range(1,len(hospitallist)+1): 56 item = hospitallist[i-1] 57 sheet.write(i,0,item.shengfen) 58 sheet.write(i,1,item.xiangmubianhao) 59 sheet.write(i,2,item.xiangmumingcheng) 60 sheet.write(i,3,item.xiangmuneihan) 61 sheet.write(i,4,item.chuwaineirong) 62 sheet.write(i,5,item.danwei) 63 sheet.write(i,6,item.jiage) 64 sheet.write(i,7,item.shuoming) 65 sheet.write(i,8,item.wenhao) 66 sheet.write(i,9,item.zhixingriqi) 67 book.save(filename) 68 self.log.info('save excel success') 69 70 71 if __name__ == '__main__': 72 Get_medicalprice()
其中,类Item定义了我们需要从网页获取到的所有信息;类Get_medicalprice为爬虫主程序;方法__init__定义了整个爬虫的工作流程;方法getname从“name.txt”中获取需要查找的医疗服务项目名称,返回名称列表;方法gethospitalprice为爬虫的关键,负责根据getname返回的名称列表在页面中查找对应的信息并保存;方法savefiletoxls负责将gethospitalprice获取到的所有信息保存到电子表中。
我们现在开始来补充方法gethospitalprice中的代码。
使用selenium模拟调用浏览器PhantomJS,首先用“#”注释掉__init__中的“self.savefiletoxls(self.filename,self.hospitallist)”,出于测试目的,这里只让浏览器截图查看模拟效果而不进一步抓取数据。在gethospitalprice中增加代码如下:
1 def gethospitalprice(self,url,namelist): 2 browser = webdriver.PhantomJS() 3 list_hospitalprice = [] 4 browser.get(url) 5 #browser.implicitly_wait(10) 6 for name in namelist: 7 textelement = browser.find_element_by_id('projectname') 8 textelement.clear() #清除text中已输入的项目 9 try: 10 textelement.send_keys(name.decode('GBK')) #text中填入项目名称 11 except: 12 self.log.error('get data %s error ' % name) 13 continue 14 else: 15 self.log.info('get data %s \n' % name.decode('GBK')) 16 selectelement = browser.find_element_by_id('provName') 17 Select(selectelement).select_by_value(u'河南省') #使用select控件选择河南省 18 submitelement = browser.find_element_by_class_name('l-btn-left') 19 submitelement.click() #点击查询按钮 20 time.sleep(10) 21 browser.get_screenshot_as_file('%s.png' % name) #进行查询后让浏览器截图,以查看程序是否运行正常
在这里,模块selenium本身自带的implicitly_wait效果比time里的sleep要好,所以平时尽量优先使用implicitly_wait,而这里依旧使用time.sleep是为防止被服务器拦截而强制让程序降速。根据页面源代码,找到相应控件的id,如这里的“projectname”、“provName”,利用find_element_by_id来定位。其中用于选择省份的控件是个select,需要用到selenium.webdriver.support.select中的Select。通过send_keys来向“provName”的文本框控件中发送项目名称时,特别需要注意的是汉字编码,因为name.txt是在windows下创建的,编码用的是"GBK'',所以这里需要先用decode("GBK")把项目名称进行反编码。
但有个问题是“查找”按钮不好定位,没有明显的id和class。右键点击“查找”按钮,选择“审查元素”,这里可以看到该控件的class为“l-btn-left”(虽然那个“清空”按钮的class也是“l-btn-left”,但并没太大的影响,“查找”比“清空”位置靠前,find_element_by_class_name返回的是检索到的第一个符合条件的控件),利用find_element_by_class_name('l-btn-left')来定位。

在最后增加一条语句 browser.get_screenshot_as_file('%s.png' % name) 来让浏览器自动截图并保存成“项目名称.png”的图片,以便方便查看确定程序是否在正常运行。
点击run运行程序,在目录下随便打开一张png图片,如下图:

爬虫程序已经成功选择了设定的“省份”,填入了读取到的项目名称,并成功点击了“查找”按钮,而且成功地获取到了我们需要的信息。
好了,下面我们就开始和以前一样抓取页面上的信息。
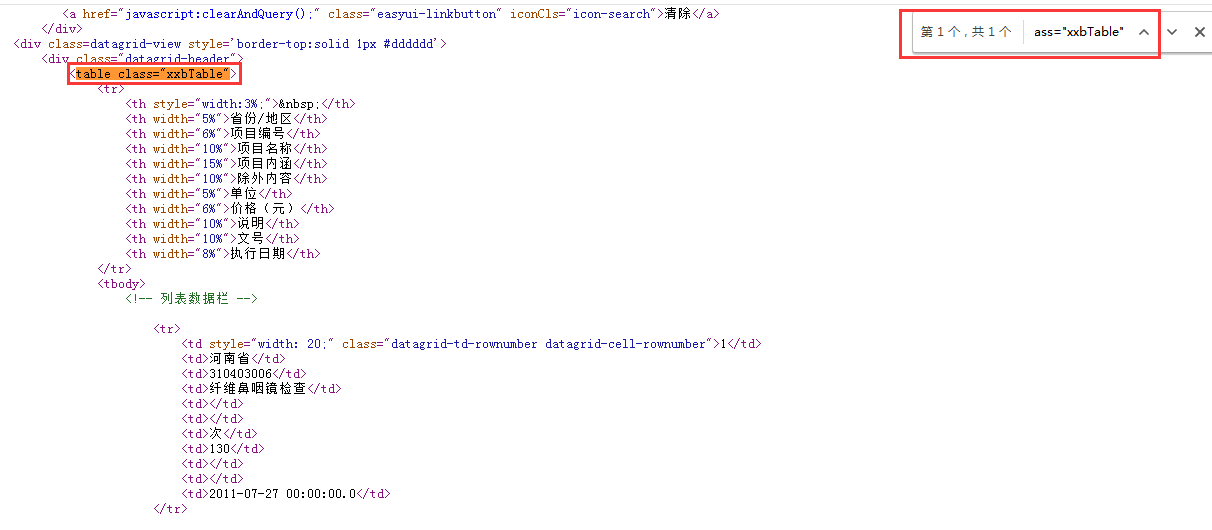
查看页面源代码,可以看到存放数据的位置在标签tbody下,但tbody不唯一,而上层的标签table,class值为“xxbTable”,通过搜索后发现是唯一的。所以这里我们先定位class值为“xxbTable”的标签table,随后再依次定位tbody,tr,td。
1 resultelement = browser.find_element_by_class_name('xxbTable') 2 #print resultelement.text 3 elements=resultelement.find_elements_by_xpath('./tbody[2]/tr/td') 4 item = Item() 5 if len(elements)==0: 6 self.log.info('%s has no data' % name.decode('GBK')) 7 else: 8 self.log.info('save data %s to list' % name.decode('GBK')) 9 item.shengfen = elements[1].text 10 item.xiangmubianhao = elements[2].text 11 item.xiangmumingcheng = elements[3].text 12 item.xiangmuneihan = elements[4].text 13 item.chuwaineirong = elements[5].text 14 item.danwei = elements[6].text 15 item.jiage = elements[7].text 16 item.shuoming = elements[8].text 17 item.wenhao = elements[9].text 18 item.zhixingriqi = elements[10].text 19 list_hospitalprice.append(item)
tbody不是唯一的,所以在确定需求的是哪一部分的时候,可以先用定位到tbody处,使用for循环打印下此处的文本,代码如下:
1 resultelement = browser.find_element_by_class_name('xxbTable') 2 #print resultelement.text 3 elements=resultelement.find_elements_by_xpath('./tbody') 4 for i in elements: 5 print i.text
运行结果如下:
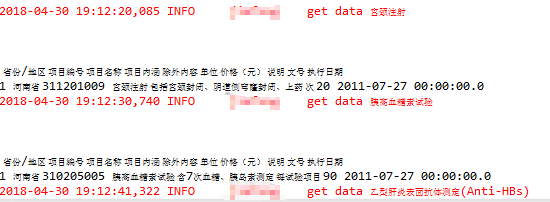
tbody[0]为空,tbody[1]是列名,tbody[2]才是我们需要的数据。
最终运行后,生成的结果被方法savefiletoxls保存到电子表'医疗服务价格.xls'中
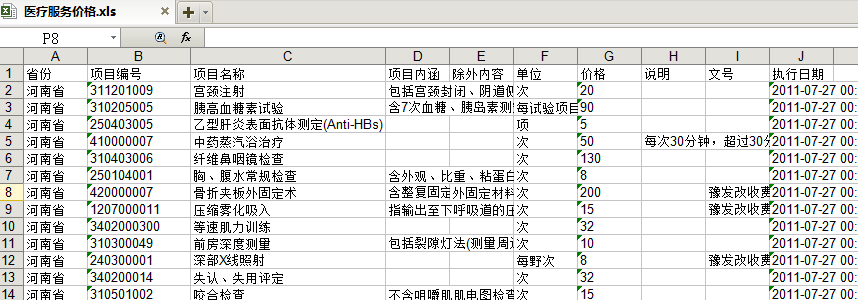
以下为“main.py”文件的完整代码:


1 from selenium import webdriver 2 from selenium.webdriver.support.select import Select 3 from myLog import MyLog 4 import time 5 import xlwt 6 7 class Item(object): 8 shengfen = None 9 xiangmubianhao = None 10 xiangmumingcheng = None 11 xiangmuneihan = None 12 chuwaineirong = None 13 danwei = None 14 jiage = None 15 shuoming = None 16 wenhao = None 17 zhixingriqi = None 18 19 class Get_medicalprice(object): 20 def __init__(self): 21 self.hospitalPriceurl = 'http://www.zgyyjgw.com/front/cn/hospitalPrice' 22 self.log = MyLog() 23 self.filename = u'医疗服务价格.xls'.encode('GBK') 24 self.namelist = self.getname('name.txt') 25 self.hospitallist = self.gethospitalprice(self.hospitalPriceurl,self.namelist) 26 self.savefiletoxls(self.filename,self.hospitallist) 27 28 def getname(self,filename): 29 namelist = [] 30 with open(filename,'r') as fp: 31 s = fp.read() 32 for name in s.split(): 33 namelist.append(name) 34 self.log.info('open namelist success , the length of list is %d' % len(namelist)) 35 return namelist 36 37 def gethospitalprice(self,url,namelist): 38 browser = webdriver.PhantomJS() 39 list_hospitalprice = [] 40 n = 1 41 self.log.info('open the link %s' % url) 42 browser.get(url) 43 #browser.implicitly_wait(10) 44 for name in namelist: 45 textelement = browser.find_element_by_id('projectname') 46 textelement.clear() 47 try: 48 textelement.send_keys(name.decode('GBK')) #text中填入项目名称 49 except: 50 self.log.error('get data %s error (%d)' % (name,n)) 51 n += 1 52 continue 53 else: 54 self.log.info('get data %s (%d)\n' % (name.decode('GBK'),n)) 55 n += 1 56 selectelement = browser.find_element_by_id('provName') 57 Select(selectelement).select_by_value(u'河南省') #省份select控件选择河南省 58 submitelement = browser.find_element_by_class_name('l-btn-left') 59 submitelement.click() #点击查询按钮 60 time.sleep(10) 61 #print browser.page_source 62 #browser.get_screenshot_as_file('test.png') 63 resultelement = browser.find_element_by_class_name('xxbTable') 64 #print resultelement.text 65 elements=resultelement.find_elements_by_xpath('./tbody[2]/tr/td') 66 item = Item() 67 if len(elements)==0: 68 self.log.info('%s has no data' % name.decode('GBK')) 69 else: 70 self.log.info('save data %s to list' % name.decode('GBK')) 71 item.shengfen = elements[1].text 72 item.xiangmubianhao = elements[2].text 73 item.xiangmumingcheng = elements[3].text 74 item.xiangmuneihan = elements[4].text 75 item.chuwaineirong = elements[5].text 76 item.danwei = elements[6].text 77 item.jiage = elements[7].text 78 item.shuoming = elements[8].text 79 item.wenhao = elements[9].text 80 item.zhixingriqi = elements[10].text 81 list_hospitalprice.append(item) 82 return list_hospitalprice 83 84 def savefiletoxls(self,filename,hospitallist): 85 self.log.info('save data to excel') 86 book = xlwt.Workbook(encoding = 'utf8',style_compression=0) 87 sheet = book.add_sheet(u'医疗服务项目收费') 88 sheet.write(0,0,u'省份'.encode('utf8')) 89 sheet.write(0,1,u'项目编号'.encode('utf8')) 90 sheet.write(0,2,u'项目名称'.encode('utf8')) 91 sheet.write(0,3,u'项目内涵'.encode('utf8')) 92 sheet.write(0,4,u'除外内容'.encode('utf8')) 93 sheet.write(0,5,u'单位'.encode('utf8')) 94 sheet.write(0,6,u'价格'.encode('utf8')) 95 sheet.write(0,7,u'说明'.encode('utf8')) 96 sheet.write(0,8,u'文号'.encode('utf8')) 97 sheet.write(0,9,u'执行日期'.encode('utf8')) 98 for i in range(1,len(hospitallist)+1): 99 item = hospitallist[i-1] 100 sheet.write(i,0,item.shengfen) 101 sheet.write(i,1,item.xiangmubianhao) 102 sheet.write(i,2,item.xiangmumingcheng) 103 sheet.write(i,3,item.xiangmuneihan) 104 sheet.write(i,4,item.chuwaineirong) 105 sheet.write(i,5,item.danwei) 106 sheet.write(i,6,item.jiage) 107 sheet.write(i,7,item.shuoming) 108 sheet.write(i,8,item.wenhao) 109 sheet.write(i,9,item.zhixingriqi) 110 book.save(filename) 111 self.log.info('save excel success') 112 113 114 if __name__ == '__main__': 115 Get_medicalprice()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号