爬虫中多线程的运用
检索百张的页面,爬虫运行下来往往在一小时以内,时间上还是可以接受的。但当整理后的URL数量过多的时候,就只能考虑采取多线程分步爬取了。Python里控制多线程只需要用到模板threading,而且只需要用到其中的Thread。
简单的使用方法如下:
1 import time 2 import threading 3 4 def spider(number): 5 print u"%d 号爬虫开始运行! 时间: %s" % (number,time.strftime('%H:%M:%S',time.localtime())) 6 time.sleep(2) 7 print u"%d 号爬虫运行结束! 时间: %s" % (number,time.strftime('%H:%M:%S',time.localtime())) 8 9 if __name__ == "__main__": 10 thread = 5 11 print u"主程序开始运行! 时间: %s" % time.strftime('%H:%M:%S',time.localtime()) 12 for i in range(1,thread+1): 13 t = threading.Thread(target=spider,args=(i,)) 14 t.start() 15 16 print u"主程序运行结束! 时间: %s" % time.strftime('%H:%M:%S',time.localtime())
Thread使用方法为:
threading.Thread(target=线程运行的函数,args=(参数)) 其中参数用逗号分隔,并以逗号结尾。
随后使用start启动。
运行结果如下:
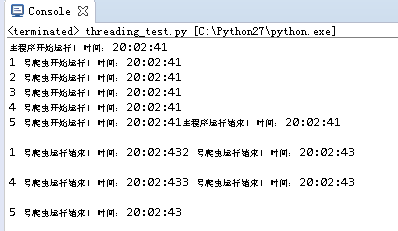
可以看到五个线程同步运行,因sleep设置的时间相同,所以也同步结束。
但有一个缺点是第16行代码在五个线程启动后随即也就运行了,相当于此时主线程已经结束了而那五个子线程还在运行。
控制策略有两个
在start之前把子线程设置为守护线程
修改代码如下:
1 for i in range(1,thread+1): 2 t = threading.Thread(target=spider,args=(i,)) 3 t.setDaemon(True) 4 t.start()
运行结果如下:
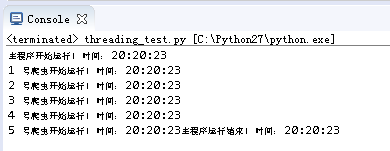
子线程在主线程结束的时候也同步结束,未运行的部分也就不再运行了。
在主线程中使用join,让主线程挂起等待子线程结束
修改代码如下:
1 for i in range(1,thread+1): 2 t = threading.Thread(target=spider,args=(i,)) 3 t.start() 4 t.join()
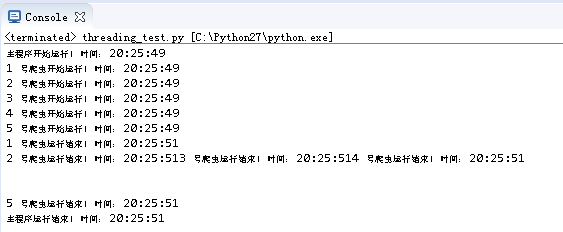
从运行结果可以看到主线程停留在t.join()的位置,一直等到五个子线程全部结束后才开始继续向后运行。
以上就是需要用到的threading模板里所有的东西了。
在整理好需要处理的数据列表后,我们只需要将列表分段分别交给不同的线程来处理,主线程等待所有数据处理完毕之后再进行下一步操作,如下:
1 import time 2 import threading 3 4 def spider(number,data_list): 5 print u"%d 号爬虫开始运行! 时间: %s" % (number,time.strftime('%H:%M:%S',time.localtime())) 6 print u"%d 号爬虫需要处理的数据有%s ! 时间: %s" % (number,str(data_list),time.strftime('%H:%M:%S',time.localtime())) 7 time.sleep(2) 8 print u"%d 号爬虫运行结束! 时间: %s" % (number,time.strftime('%H:%M:%S',time.localtime())) 9 10 if __name__ == "__main__": 11 thread = 5 12 ls = [] 13 ls2 = [] 14 for n in range(1,58): 15 ls.append(n) 16 length = len(ls)//thread+1 17 for m in range(thread): 18 ls2.append(ls[length*m:length*m+length]) 19 20 print u"主程序开始运行! 时间: %s" % time.strftime('%H:%M:%S',time.localtime()) 21 for i in range(1,thread+1): 22 t = threading.Thread(target=spider,args=(i,ls2[i-1],)) 23 t.start() 24 t.join() 25 print u"主程序运行结束! 时间: %s" % time.strftime('%H:%M:%S',time.localtime())
运行结果如下:
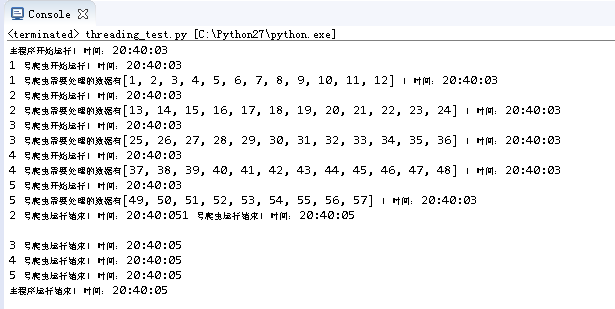
五个线程分步处理各自被分配到的数据,总体运行时间大幅缩减。当然机器给力的话,可以增加线程数,得到更快的速度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号