
Orchestrator:MySQL复制拓扑结构管理工具
What is Orchestrator?
orchestrator是MySQL复制结构的一个拓扑管理工具
其主要有以下几个特征
1.自动监测数据库复制的结构及其状态
2.提供了GUI,CLI,API等接口来检查复制拓扑的状态以及做一些调整的操作
3.支持自动的master failover,当复制结构的server挂掉以后(不管手动还是自动的),能够重新形成复制的拓扑结构
4.不依赖于特定的server版本或分支(MySQL, Percona Server, MariaDB or even MaxScale binlog servers)
5.支持多种类型的拓扑结构,不管是单个的主从还是成百上千个server组成的多级复制都不在话下
6.他的GUI不只是做向你report拓扑状态而已,你可以在Orchestrator web页面通过拖拽或者删除节点来改变复制拓扑(CLI和API也能做)
从下面的动态图能看出这一炫酷的功能

Orchestrator的manual讲解非常的详尽--他的manual已经搬家了,请看这,所以这里就不在讲他的完整的安装配置,我们只是从宏观上来讲一下Orchestrator的工作原理,同时来聊聊一些重要的、好玩的配置
How Does It Work?
1.Orchestrator是用go来写的(binaries, including rpm and deb packages are available for download).
2.它本身需要自己的数据库后台来存储管理数据库集群拓扑结构的相关信息
3.至少需要一个Orchestrator后台进程,但是推荐在多个不同的主机上运行多个Orchestrator后台,这些后台节点共用一个后台数据库,但是同时只有一个是active的(可以在web界面的status菜单中查看哪一个节点是active的,也可以通过数据库中的active_node表查看)
Using MySQL As Database Backend, Isn’t That A SPOF?
中间件的HA也应该是DBA必须应该考虑到的问题,后台数据库使用单点,会不会出现SPOF呢?
答案是不是不会,而是不用担心。
如果Orchestrator后台数据库挂了,并不是我们监控的MySQL集群就不提供服务了,只是说不受orchestrator的监控了,这跟MHA的原理类似,一切照旧,就是不能执行failover,直至MHA failback。
稍显别扭的是他需要后台数据库存储,对HA也明确的支持,在这一点上,希望将来有所改变吧
Database Server Installation Requirements
Orchestrator只需要带有SUPER, PROCESS, REPLICATION SLAVE, RELOAD权限的一个用户来连接数据库server集群,有了这些权限,他就能够检查节点的复制状态以及执行复制结构变换,他支持多种不同的方式的复制:基于binlog位点的,GTID的,伪GTID以及binlog server
没有必要在db server上安装其他软件
Automatic Master Failure Recovery
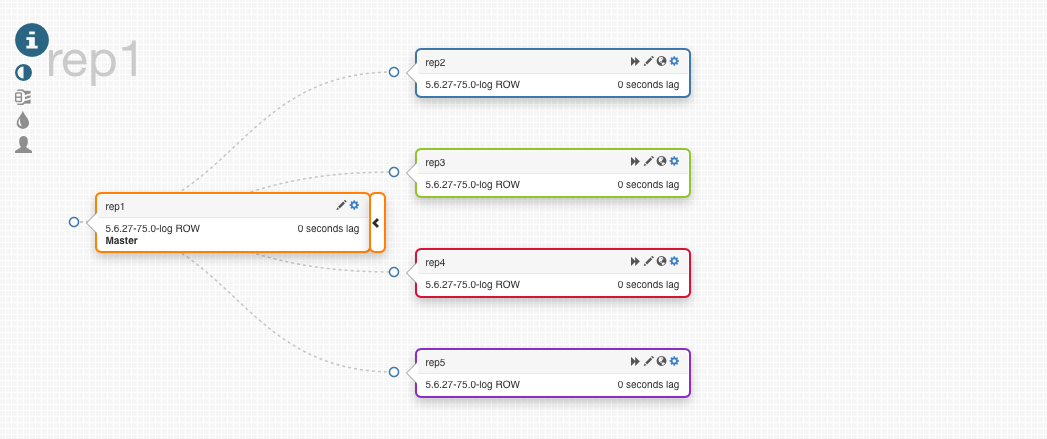
下面是一个master挂掉然后提升一个slave为master的例子,他将会选择最新的slave来提升为master。
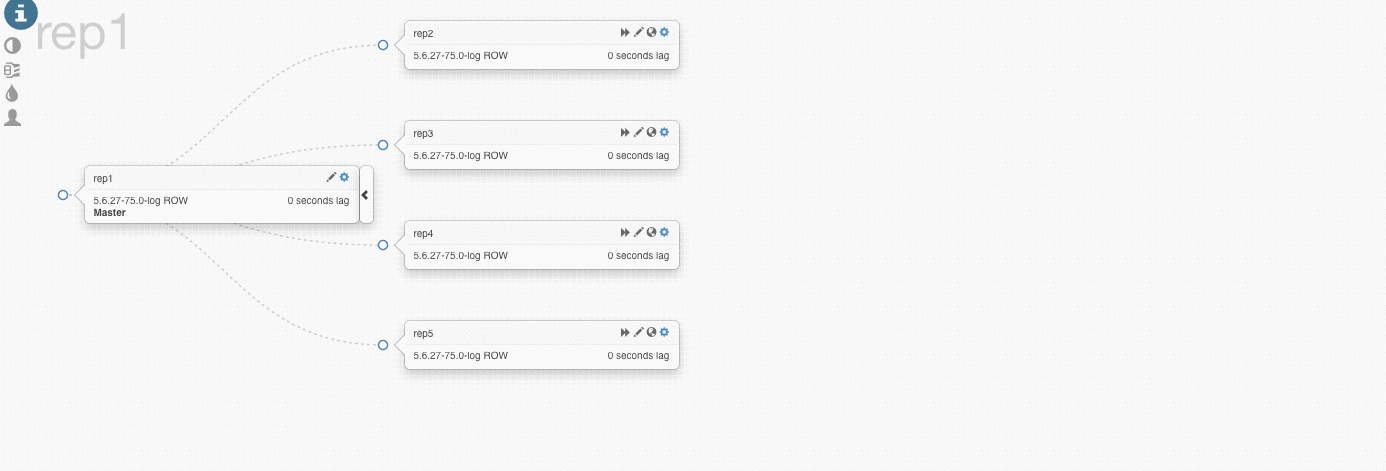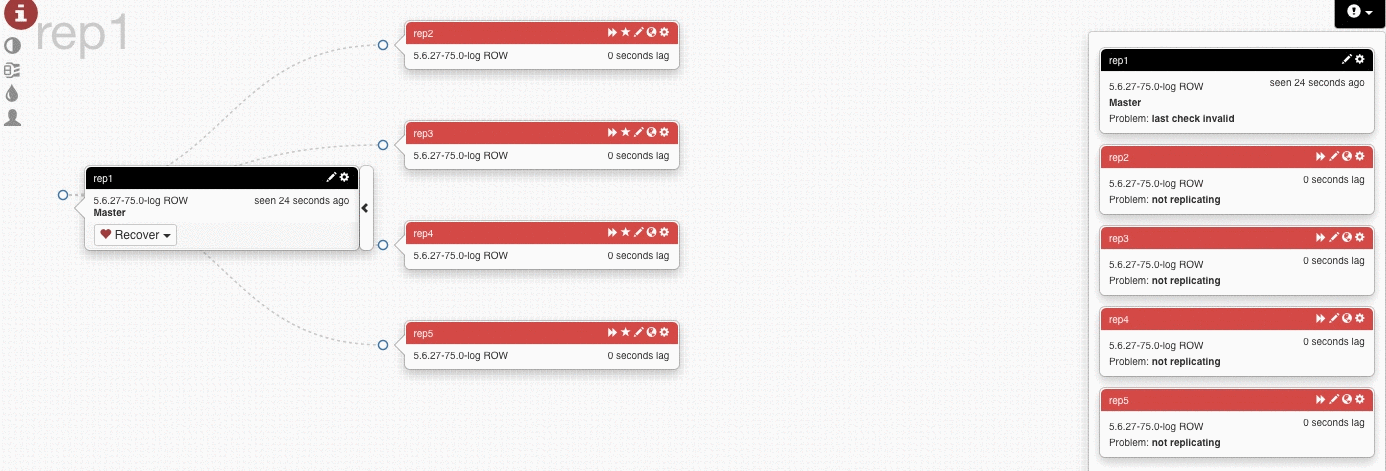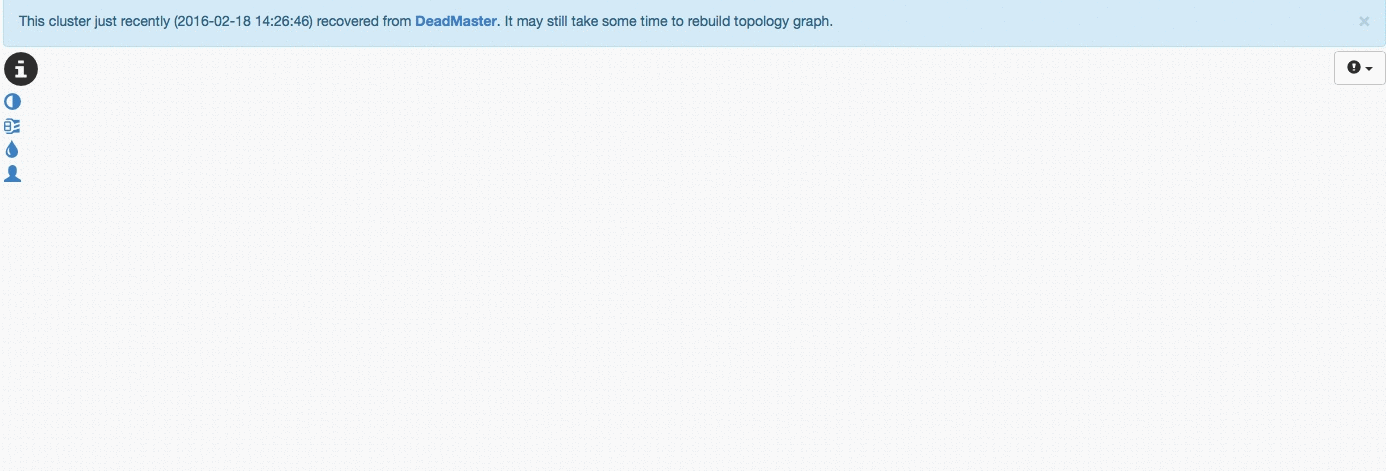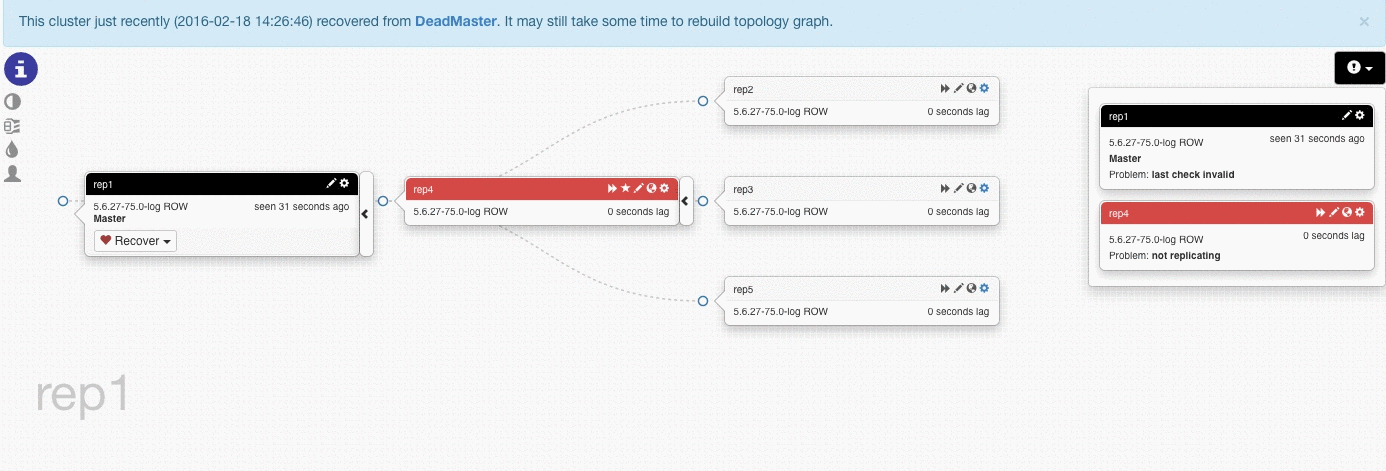
在上面的测试中,我们挂掉rep1(master),Orchestrator将rep4提升为new master,别的slave从新master开始复制数据
一般默认的设置是,rep1 failback回来的话,将恢复成原来rep1作为master的结构,如果不想用这个默认设置的话,可以在配置中配置ApplyMySQLPromotionAfterMasterFailover:True
Command Line Interface
下面是使用CLI的一些例子
1.打印拓扑结构
> orchestrator -c topology -i rep1:3306 cli
rep1:3306 [OK,5.6.27-75.0-log,ROW,>>]
+ rep2:3306 [OK,5.6.27-75.0-log,ROW,>>,GTID]
+ rep3:3306 [OK,5.6.27-75.0-log,ROW,>>,GTID]
+ rep4:3306 [OK,5.6.27-75.0-log,ROW,>>,GTID]
+ rep5:3306 [OK,5.6.27-75.0-log,ROW,>>,GTID]
2.移动slave
orchestrator -c relocate -i rep2:3306 -d rep4:3306
结果如下
> orchestrator -c topology -i rep1:3306 cli
rep1:3306 [OK,5.6.27-75.0-log,ROW,>>]
+ rep3:3306 [OK,5.6.27-75.0-log,ROW,>>,GTID]
+ rep4:3306 [OK,5.6.27-75.0-log,ROW,>>,GTID]
+ rep2:3306 [OK,5.6.27-75.0-log,ROW,>>,GTID]
+ rep5:3306 [OK,5.6.27-75.0-log,ROW,>>,GTID]
正如所想,rep2级联到rep4上去了
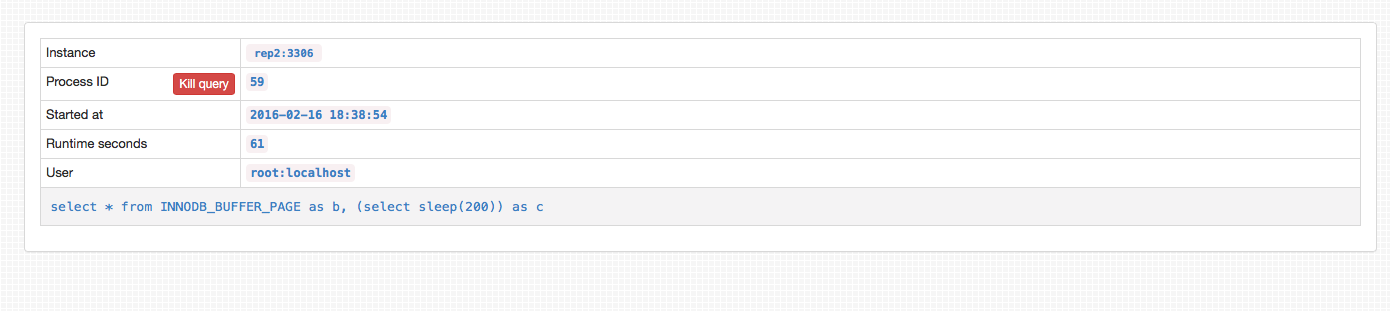
Long Queries
GUI上还有一个很nice的功能是他能展现整个复制结构中所有内部节点上的慢查询,而且我们还可以通过GUIkill掉这些慢查询
Orchestrator Configuration Settings
orchestraor的配置保存在/etc/orchestrator.conf.json文件中,包含有很多的配置选项,下面抽取一些比较重要的解释一下:
1.SlaveLagQuery:检查复制延迟
2.AgentAutoDiscover:设置为true的话,orchestrator将会自动发现复制拓扑的变化
3.HTTPAuthPassword and HTTPAuthUser:避免谁都可以登录web管理页面来改变复制拓扑
4.RecoveryPeriodBlockSeconds:避免资源抖动
5.RecoverMasterClusterFilters:定义哪些集群可以自动failover/recover
6.PreFailoverProcesses:定义failover前orchestrator做什么操作
7.PostFailoverProcesses:定义failover后orchestrator做什么操作
8.ApplyMySQLPromotionAfterMasterFailover:failover后将提升为master的slave独立出来
9.DataCenterPattern:如果有多个数据中心,可以采用不同颜色标记
Limitations
orchestrator提供给我们丰富的功能,同时,我们也应该意识到他说存在的限制于不足
关键一点是一个简单的方式来让我们将一个slave提升为master,这在master需要升级的时候会用到这一功能,还有就是计划好的failover(known)
功能限制
1.slave不能手动提升为master
2.不支持多源复制
3.不支持并行复制
4.不支持与PXC联合使用
Is Orchestrator Your High Availability Solution?
如果你还在手动的处理一些复制的问题,你都可以将他们集成到你的HA架构中,或者囊括到你的failover处理逻辑中,为了实现这一切,我们只需在orchestrator中配置相关的功能即可
1.应用连接变更
a.vip处理
b.DNS变更
c.proxy server连接变更
。 。 。
2.自动将从库设置为只读,以免发生在非主节点上写出数据导致的数据一致性问题
3.隔离宕掉的master,以免crashed master failback而发生脑裂
4.是否采用半同步以免master failure而导致数据丢失,这个功能也需要手动添加到配置里面
相比MHA或者failover而言,上面这些都是需要orchestrator做的事情
更多信息blog

【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步