

MySQL HA面面观
MySQL HA面面观
一、以往的HA
(一)、replication

优势:MySQL的replication众所周知,之后很多的相关技术都是在此基础上发展而来的,replication无处不在,这当中有很多的原因
1.部署简单
关于这反面有很多资料,也有一些自动化添加从库的脚本,用亚马逊的RDS的用户,只需要点几下鼠标就能加一个从库
2.易扩展读
3.slave对master影响小
除了占用带宽,对master基本没有太大的影响
4.出名
5.failover
主库failed,可以提升一个作为主
6.备份
如果不想因为备份而增加主库的负载,可以在从库备份
问题:
1.复制延迟
过去是单线程复制,高并发的时候会出现延迟,MySQL5.6和MariaDB10.0针对从库引进了并行机制,在这上面新版本有了更近异步的改善,现在的新版本的从库比老版本的快了好多倍
2.数据一致性问题
主库变更,从库也变更,这看似简单,但是基于语句的更新存在做很多不确定的因素,官方已经修复了很多问题,基于行模式的复制是又一重大的改进,再有就是直接写从库也是有问题的,这可以设置slave为只读来避免普通用户的写,但是具有super权限的用户就没办法控制,不过现在新增了一个super_read_only设置。
其实上面的问题我们都可以通过 pt-table-checksum 和 pt-table-sync 工具来解决
3.对主库的影响
上面提到从库不影响主库,但是日志的变更更为琢磨不定的,最常见的就是在基于语句的复制中, 对有h自增列上的表,会加表级锁,这样的话,一次只能有一个线程能插入新行,但是这个问题是可以避免的,只要改成基于行复制,配置恰当即可。
4.数据丢失
由于replication是异步的,也就是说,不管从库有没有收到更新的日志,只要执行commit以后,主库都会回复done,如果这时候主库crash了,那么有些事务就可能会丢失了。
历史演进:
尽管这是一门历史久远的技术,但是对replication一直在做很多工作,下面是从5.0开始replication实现以来的相关历史
1.基于行复制的实现(5.1):对主从数据一致性有很大的贡献
2.GTID(5.6):事务被唯一标识,搭建复制不在需要查找binlog位点
3.Checksum(5.6):binlog event有验证完整性的checksum值
4.半同步复制(5.5):避免主库crash导致数据丢失,复制协议中新加功能
5.多源复制(5.7):允许一个从库有多个主库
6.多线程复制(5.6):允许从库使用多线程,有助于降低延迟
管理工具:
复制管理工作是相当枯燥的,下面是社区中的一些管理复制工具
1.MMM:古老的perl工具,过去很流行,有很多问题,现在用得少
2.MHA:管理复制最流行的工具,牛逼在可以不丢失数据的情况下重置复制环境,在failover方面做得相当不错,简单,也难怪这么流行
3.PRM:基于peacemaker的解决方案,主要是为了替换MMM。也很擅长failover的处理,但重置复制这一点就远比不上MHA,非常复杂,感谢peacemaker,用得不多
4.Orchestrator:一个非常新、非常炫的工具,能管理复制的拓扑结构,有基于web开发的完美的接口,用来监控、控制集群拓扑
(二)Shared Storage

回到十年前,共享存储这种HA架构用得非常普遍,就是在一个共享存储的HA环境中,两个server共用一份存储,一个active,一个passive,为了共享存储,数据库文件被固定放在某个存储设备上,而这两个server均能挂载到这个设备上,这个存储可以是物理上的物理设备,比如san;或者是逻辑上的,比如DRBD;在此之上,需要有一个cluster manager,比如peacemaker来做资源管理以及failover,这个解决方案灰常流行,因为failover不会造成数据丢失。
这个架构有个缺点就是始终有一个standby在那儿闲着,啥也不能干就是等着active挂掉,还有就是不支持文件级别的恢复,要是文件corruption掉就没法搞了,云上也不好玩
现在,很少有人会上这种架构了。
(三)NDB Cluster
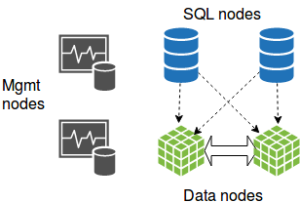
NDB这种集群解决方案已经存在多年了,NDB有三种节点:SQL,manage以及data节点,完整的NDB cluster至少四个节点。
NDB集群由于其具有的天然的分布式特性,并不适用于所有的场景,如果工作饱和的话,还是运行得挺好的,反之,那情况就不太乐观了,对NDB来说,工作饱和起码包括高并发,事务中的表的主键短的占比高,百万级别的tps不是什么稀罕事
反之,负载低的NDB集群,我见过的极端的情况是查询时间超过20分钟。
尽管NDB已经很完善,也一直在完善中,他们的应用也被推向了固定领域,总之,这门技术正在退出历史舞台,现在大多数在用的也就是电信行业以及在线游戏行业。
二、当下流行的HA
(一)Galera
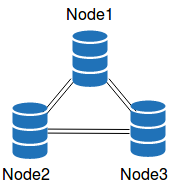
1.防止脑裂,至少三节点
2.事务几乎在所有节点同时执行
3.各节点事务顺序一致
4.认证,检测事务冲突,存在冲突,返回死锁的error
5.大事务导致内存溢出
6.表必须有主键,否则记录的唯一性识别会是一个非常致命的问题
7.事务提交时节点间的网络延迟,对于部署在WAN中的galera尤其要注意这一点
8.如果说集群中某个节点负载过高,不能实时处理事务的话,就会拖慢整个集群,解决办法,就是增加slave的并发线程数
9.热点记录更新
10.db持续可用性,就算是执行事务的节点在事务提交后挂掉了,这个事务其实已经存在于其他节点的队列中,并不会丢掉,这就要了传统共享存储的老命了,因为在此之前,共享存储是唯一的解决方案,崩溃后不丢数据
11.galera的所有节点几乎同步,所有节点都可以提供读,几乎没有多少复制延迟的压力
12.所有节点都支持写,但是死锁的风险会很高
13.SST/IST,SST采用Percona XtraBackup备份,SST期间集群是完全可用的,只是性能有所降低。
(二)RDS Aurora
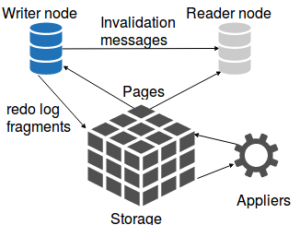
1.Aurora特殊在他存储层有自己的处理逻辑。这个处理逻辑是属于写节点还是存储层本身就不得而知了,因为源码没有对外开发,我们姑且称他为appliers,其作用就是apply redo log fragments,如果请求的页正好有fragment要apply,applier会先apply再返回。
2.从写节点的角度来看,写的更少了,也没有一个固定大小的文件来直接管理redo log了,这就像是innodb_log_file_size被设置了一个灰常大的值。
3.不需要flush pages,buffer pool中不存在脏页
4.不难看出,Aurora支持高并发的写入
5.如果需要更新的页已经存在于buffer pool中,那么server是直接修改他还是丢掉然后从存储读取
6.不用担心存储不够用,表空间不会收缩
7.存储共享,除非是多AZ,独立的IOPS
8.对大数据以及高并发应用,主从自动切换,提供读写终端节点做读写分离
10.更新大表的问题,数据量超过buffer pool,It is also quite easy to overload the appliers
三、新生代HA
(一)group replication
GR的出现是oracle对Galera做出的回应,目的就是提供与galera类似的功能,是Innodb cluster的一个组成部分
1.基于GTID replication模式,所有节点共享一个UUID序列,为了控制延迟,中间加了一个流控制层,不同的是,galera需要满足完全一致性,而GR只需要满足多数一致,多数一致采用的是Paxos协议,支持更友好。
2.流控:两队列,一个处理认证,一个apply log,What is interesting in the Oracle approach is the presence of a throttling mechanism. When flow control is requested by a node, instead of halting the processing of new transactions like Galera, the rate of transactions is throttled. That can help to meet strict timing SLAs
3.类似galera,GR也有同样的限制,大事务,延迟和热点行
4.here
(二)proxies
智能proxies可能是未来MySQL HA的另一种解决方案,他并不是严格意义上的MySQL,事实上,他是跟其他方案搭配作用的一个混合体
1.原理很简单,客户端两上proxy,然后他给你转发到你想连的MySQL server。proxy必须监控后端服务器的状态,并且可以在MySQL server上执行操作
2.proxy不能存在单点故障,至少得有两台server组成基本的proxy HA
3.如果多个proxy同时使用的话,他们之间对后端服务的状态监控应该是一致的,可想而知,在一个复制环境中,不同的proxy将写请求发送给不同的server会是什么样子
4.有几种方式可以解决这个问题,最简单就是ap这种架构的HA proxy,同时只有一个proxy在工作,这当中需要加一些判断proxy服务存活的逻辑,典型的作法是用keepalived或者peacemaker
5.二一种是由proxies来判断哪一个是写节点,比如,Galera集群中,wsrep_local_index值最小的就是写节点
6.proxies之间可以相互通信,协同工作,一个proxy监控,然后把结果同步给peers
可选proxy
1.ProxySQL
支持读写分离,查询缓存,sharding,binlog server,SQL firewalling
2.MaxScale
支持读写分离,sharding,binlog server,SQL firewalling
Innodb cluster组件,支持读写分离
4.HAProxy
商业proxy
(三)Distributed storage
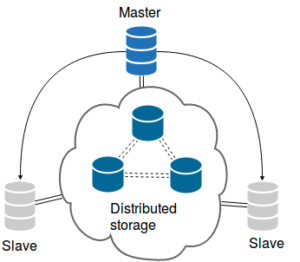
目前没有人用于生产环境,可以说是还处于襁褓期,连新生都算不上
1.最简单的分布式至少需要三节点的ceph集群,ceph节点上也跑MySQL server,datadir就是ceph RDB block设备,ceph中的数据会自动的复制到其余节点。内置的数据复制是分布式的重要组件,ceph RDB支持快照和clone复制。clone只是针对增量部分,我们三个MySQL server不仅不会用全量复制,而是一个全量加两个增量,随着时间推移,增量的增长,当达到一定大小的时候,我们会新生成一个快照和clone合并到全量数据集。这个过程一般也就花费几秒钟的时间,并不需要停止MySQL
2.可以用在大数据集,读密集型的应用。这种架构能处理大量的写操作,写负载越高,快照刷新就越频繁,不过,refresh10TB和1GB几乎没有什么差别。
3.For that purpose, I wrote an SST script for Percona XtraDB Cluster that works with Ceph. I blogged about it here。I also wrote a Ceph snapshot/clone backup script that can provision a slave from a master snapshot. I’ll blog about how to use this Ceph backup script in the near future.
4.更进一步,多实例也可以用数据页,ceph可以用作Innodb页的分布式存储,可以开发一个类似Aurora的单数据集HA的MySQL数据库
5.Percona Server for MySQL 5.7,增加了Ceph/Rados,My work can be found (here).

【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步