
第二章 InnoDB存储引擎
2.1 InnoDB存储引擎概述
特点是行锁设计、支持MVCC、支持外键、提供一致性非锁定读,同时被设计用来最有效地利用以及使用内存和CPU
2.2 InnoDB存储引擎的版本
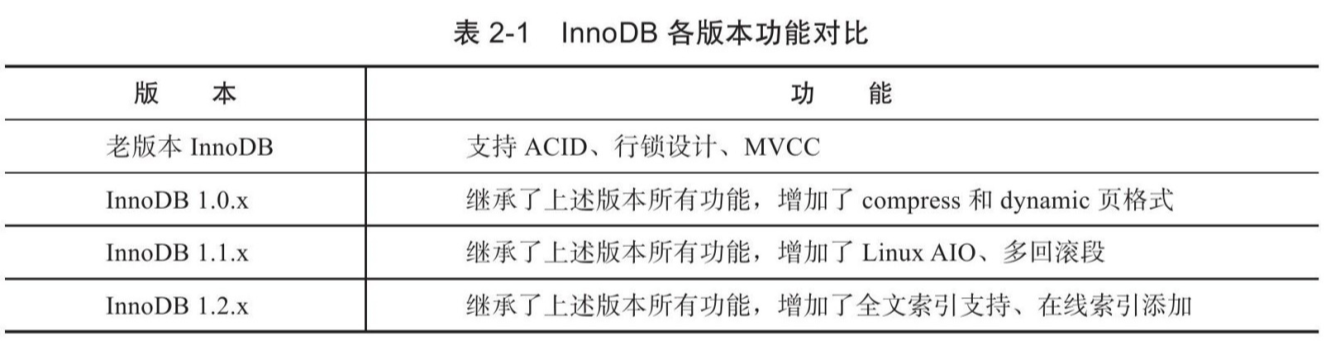
InnoDB存储引擎被包含于所有MySQL数据库的二进制发行版本中。早期其版本随着MySQL数据库的更新而更新。从MySQL 5.1版本时,MySQL数据库允许存储引擎开发商以动态方式加载引擎,这样存储引擎的更新可以不受MySQL数据库版本的限制。所以在MySQL 5.1中,可以支持两个版本的InnoDB,一个是静态编译的InnoDB版本,可将其视为老版本的InnoDB;另一个是动态加载的InnoDB版本,官方称为InnoDB Plugin,可将其视为InnoDB 1.0.x版本。MySQL 5.5版本中又将InnoDB的版本升级到了1.1.x。而在最近的MySQL 5.6版本中InnoDB的版本也随着升级为1.2.x版本。从5.6.11开始,innodb引擎的版本好号跟server版本号相同。
InnoDB Plugin是不支持Linux Native AIO功能的。此外,由于不支持多回滚段,InnoDB Plugin支持的最大支持并发事务数量也被限制在1023。
2.3 InnoDB体系架构
- 维护所有进程/线程需要访问的多个内部数据结构。
- 缓存磁盘上的数据,方便快速地读取,同时在对磁盘文件的数据修改之前在这里缓存。
- 重做日志(redo log)缓冲。
2.3.1 后台线程
1.master thread
Master Thread是一个非常核心的后台线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新、合并插入缓冲(INSERT BUFFER)、UNDO页的回收等。
2.io thread
在InnoDB存储引擎中大量使用了AIO(Async IO)来处理写IO请求,这样可以极大提高数据库的性能。而IO Thread的工作主要是负责这些IO请求的回调处理。InnoDB 1.0版本之前共有4个IO Thread,分别是write、read、insert buffer和log IO thread。在Linux平台下,IO Thread的数量不能进行调整。从InnoDB 1.0.x版本开始,read thread和write thread分别增大到了4个,并且不再使用innodb_file_io_threads参数,而是分别使用innodb_read_io_threads和innodb_write_io_threads参数进行设置,读线程的ID总是小于写线程
3.pruge thread
事务被提交后,其所使用的undolog可能不再需要,因此需要PurgeThread来回收已经使用并分配的undo页,从InnoDB 1.2版本开始,InnoDB支持多个Purge Thread,这样做的目的是为了进一步加快undo页的回收。同时由于Purge Thread需要离散地读取undo页,这样也能更进一步利用磁盘的随机读取性能。如用户可以设置4个Purge Thread
4.Page Cleaner Thread
Page Cleaner Thread是在InnoDB 1.2.x版本中引入的。其作用是将之前版本中脏页的刷新操作都放入到单独的线程中来完成。而其目的是为了减轻原Master Thread的工作及对于用户查询线程的阻塞
2.3.2 内存
1.缓冲池
提高读写性能
在数据库中进行读取页的操作,首先将从磁盘读到的页存放在缓冲池中,这个过程称为将页“FIX”在缓冲池中。下一次再读相同的页时,首先判断该页是否在缓冲池中。若在缓冲池中,称该页在缓冲池中被命中,直接读取该页。否则,读取磁盘上的页。
数据库中页的修改操作,则首先修改在缓冲池中的页,然后再以一定的频率刷新到磁盘上。Checkpoint的机制刷新回磁盘
缓冲池中缓存的数据页类型有:索引页、数据页、undo页、插入缓冲(insert buffer)、自适应哈希索引(adaptive hash index)、InnoDB存储的锁信息(lock info)、数据字典信息(data dictionary)等
从InnoDB 1.0.x版本开始,允许有多个缓冲池实例。每个页根据哈希值平均分配到不同缓冲池实例中。这样做的好处是减少数据库内部的资源竞争,增加数据库的并发处理能力
SELECT POOL_ID,POOL_SIZE,FREE_BUFFERS,DATABASE_PAGES FROM information_schema.INNODB_BUFFER_POOL_STATS;
2.LRU List、Free List和Flush List
数据库中的缓冲池是通过LRU(Latest Recent Used,最近最少使用)算法来进行管理的。即最频繁使用的页在LRU列表的前端,而最少使用的页在LRU列表的尾端。当缓冲池不能存放新读取到的页时,将首先释放LRU列表中尾端的页。
在InnoDB存储引擎中,缓冲池中页的大小默认为16KB,同样使用LRU算法对缓冲池进行管理。稍有不同的是InnoDB存储引擎对传统的LRU算法做了一些优化。在InnoDB的存储引擎中,LRU列表中还加入了midpoint位置。新读取到的页,虽然是最新访问的页,但并不是直接放入到LRU列表的首部,而是放入到LRU列表的midpoint位置。这个算法在InnoDB存储引擎下称为midpoint insertion strategy。在默认配置下,该位置在LRU列表长度的5/8处。midpoint位置可由参数innodb_old_blocks_pct控制
在InnoDB存储引擎中,把midpoint之后的列表称为old列表,之前的列表称为new列表。可以简单地理解为new列表中的页都是最为活跃的热点数据。
LRU列表用来管理已经读取的页,但当数据库刚启动时,LRU列表是空的,即没有任何的页。这时页都存放在Free列表中。当需要从缓冲池中分页时,首先从Free列表中查找是否有可用的空闲页,若有则将该页从Free列表中删除,放入到LRU列表中。否则,根据LRU算法,淘汰LRU列表末尾的页,将该内存空间分配给新的页。当页从LRU列表的old部分加入到new部分时,称此时发生的操作为page made young,而因为innodb_old_blocks_time的设置而导致页没有从old部分移动到new部分的操作称为page not made young。
Free buffers表示当前Free列表中页的数量,Database pages表示LRU列表中页的数量。可能的情况是Free buffers与Database pages的数量之和不等于Buffer pool size。
因为缓冲池中的页还可能会被分配给自适应哈希索引、Lock信息、Insert Buffer等页,而这部分页不需要LRU算法进行维护,因此不存在于LRU列表中。
ages made young显示了LRU列表中页移动到前端的次数,因为该服务器在运行阶段没有改变innodb_old_blocks_time的值,因此not young为0。youngs/s、non-youngs/s表示每秒这两类操作的次数。
show engine innodb status;
INNODB_BUFFER_POOL_STATS
INNODB_BUFFER_PAGE_LRU
nnoDB存储引擎从1.0.x版本开始支持压缩页的功能,即将原本16KB的页压缩为1KB、2KB、4KB和8KB。而由于页的大小发生了变化,LRU列表也有了些许的改变。对于非16KB的页,是通过unzip_LRU列表进行管理的
首先,在unzip_LRU列表中对不同压缩页大小的页进行分别管理。其次,通过伙伴算法进行内存的分配。例如对需要从缓冲池中申请页为4KB的大小,其过程如下:
1)检查4KB的unzip_LRU列表,检查是否有可用的空闲页;
2)若有,则直接使用;
3)否则,检查8KB的unzip_LRU列表;
4)若能够得到空闲页,将页分成2个4KB页,存放到4KB的unzip_LRU列表;
5)若不能得到空闲页,从LRU列表中申请一个16KB的页,将页分为1个8KB的页、2个4KB的页,分别存放到对应的unzip_LRU列表中。
SELECT TABLE_NAME,SPACE,PAGE_NUMBER,COMPRESSED_SIZE FROM INNODB_BUFFER_PAGE_LRU
在LRU列表中的页被修改后,称该页为脏页(dirty page),即缓冲池中的页和磁盘上的页的数据产生了不一致。这时数据库会通过CHECKPOINT机制将脏页刷新回磁盘,而Flush列表中的页即为脏页列表。需要注意的是,脏页既存在于LRU列表中,也存在于Flush列表中。LRU列表用来管理缓冲池中页的可用性,Flush列表用来管理将页刷新回磁盘,二者互不影响。
脏页查询:SELECT TABLE_NAME,SPACE,PAGE_NUMBER,PAGE_TYPE,FROM INNODB_BUFFER_PAGE_LRU,WHERE OLDEST_MODIFICATION>0;
3.重做日志缓冲
重做日志缓冲一般不需要设置得很大,因为一般情况下每一秒钟会将重做日志缓冲刷新到日志文件,因此用户只需要保证每秒产生的事务量在这个缓冲大小之内即可
重做日志在下列三种情况下会将重做日志缓冲中的内容刷新到外部磁盘的重做日志文件中。
- Master Thread每一秒将重做日志缓冲刷新到重做日志文件;
- 每个事务提交时会将重做日志缓冲刷新到重做日志文件;
- 当重做日志缓冲池剩余空间小于1/2时,重做日志缓冲刷新到重做日志文件。
4.额外的内存池
在InnoDB存储引擎中,对内存的管理是通过一种称为内存堆(heap)的方式进行的。在对一些数据结构本身的内存进行分配时,需要从额外的内存池中进行申请,当该区域的内存不够时,会从缓冲池中进行申请。例如,分配了缓冲池(innodb_buffer_pool),但是每个缓冲池中的帧缓冲(frame buffer)还有对应的缓冲控制对象(buffer control block),这些对象记录了一些诸如LRU、锁、等待等信息,而这个对象的内存需要从额外内存池中申请。因此,在申请了很大的InnoDB缓冲池时,也应考虑相应地增加这个值。
2.4 Checkpoint技术
前滚:当前事务数据库系统普遍都采用了Write Ahead Log策略,即当事务提交时,先写重做日志,再修改页。当由于发生宕机而导致数据丢失时,通过重做日志来完成数据的恢复。
-- 无checkpoint设置过大带来的问题:宕机后数据库的恢复时间
Checkpoint(检查点)技术的目的是解决以下几个问题:
- 缩短数据库的恢复时间;
- 缓冲池不够用时,将脏页刷新到磁盘;
- 重做日志不可用时,刷新脏页。
当数据库发生宕机时,数据库不需要重做所有的日志,因为Checkpoint之前的页都已经刷新回磁盘。故数据库只需对Checkpoint后的重做日志进行恢复。这样就大大缩短了恢复的时间。
此外,当缓冲池不够用时,根据LRU算法会溢出最近最少使用的页,若此页为脏页,那么需要强制执行Checkpoint,将脏页也就是页的新版本刷回磁盘。
对于InnoDB存储引擎而言,其是通过LSN(Log Sequence Number)来标记版本的。而LSN是8字节的数字,其单位是字节。每个页有LSN,重做日志中也有LSN,Checkpoint也有LSN。可以通过命令SHOW ENGINE INNODB STATUS来观察:
在InnoDB存储引擎内部,有两种Checkpoint,分别为:
- Sharp Checkpoint
- Fuzzy Checkpoint
在InnoDB存储引擎中可能发生如下几种情况的Fuzzy Checkpoint:
- Master Thread Checkpoint
- FLUSH_LRU_LIST Checkpoint
- Async/Sync Flush Checkpoint
- Dirty Page too much Checkpoint
Master Thread中发生的Checkpoint,差不多以每秒或每十秒的速度从缓冲池的脏页列表中刷新一定比例的页回磁盘。这个过程是异步的,即此时InnoDB存储引擎可以进行其他的操作,用户查询线程不会阻塞。
FLUSH_LRU_LIST Checkpoint是因为InnoDB存储引擎需要保证LRU列表中需要有差不多100个空闲页可供使用。在InnoDB1.1.x版本之前,需要检查LRU列表中是否有足够的可用空间操作发生在用户查询线程中,显然这会阻塞用户的查询操作。倘若没有100个可用空闲页,那么InnoDB存储引擎会将LRU列表尾端的页移除。如果这些页中有脏页,那么需要进行Checkpoint,而这些页是来自LRU列表的,因此称为FLUSH_LRU_LIST Checkpoint。而从MySQL 5.6版本,也就是InnoDB1.2.x版本开始,这个检查被放在了一个单独的Page Cleaner线程中进行,并且用户可以通过参数innodb_lru_scan_depth控制LRU列表中可用页的数量
innodb_lru_scan_depth
A parameter that influences the algorithms and heuristics for the flush operation for the InnoDB buffer pool. Primarily of interest to performance experts tuning I/O-intensive workloads. It specifies, per buffer pool instance, how far down the buffer pool LRU page list the page cleaner thread scans looking for dirty pages to flush. This is a background operation performed once per second.
意思是说:这是一个触发IBP刷脏的一个参数,以调优数据库IO密集型工作负载
A setting smaller than the default is generally suitable for most workloads. A value that is much higher than necessary may impact performance. Only consider increasing the value if you have spare I/O capacity under a typical workload. Conversely, if a write-intensive workload saturates your I/O capacity, decrease the value, especially in the case of a large buffer pool.
对于写密集型的应用,I/O容量已达到饱和,特别是IBP本身设置比较大的情况下,降低这个参数设置
When tuning innodb_lru_scan_depth, start with a low value and configure the setting upward with the goal of rarely seeing zero free pages. Also, consider adjusting innodb_lru_scan_depth when changing the number of buffer pool instances, since innodb_lru_scan_depth * innodb_buffer_pool_instances defines the amount of work performed by the page cleaner thread each second.
Log sequence number 16738826933778 -- 当前redo lsn
Log flushed up to 16738826933778 -- 刷新到磁盘的redo lsn
Pages flushed up to 16738826925299 -- 刷新到磁盘的数据页的redo lsn
Last checkpoint at 16738826925299 -- 最后checkpoint的redo lsn
Async/Sync Flush Checkpoint指的是重做日志文件不可用的情况,这时需要强制将一些页刷新回磁盘,而此时脏页是从脏页列表中选取的,可见,Async/Sync Flush Checkpoint是为了保证重做日志的循环使用的可用性。
从InnoDB 1.2.x版本开始——也就是MySQL 5.6版本,这部分的刷新操作同样放入到了单独的Page Cleaner Thread中,故不会阻塞用户查询线程。
最后一种Checkpoint的情况是Dirty Page too much,即脏页的数量太多,导致InnoDB存储引擎强制进行Checkpoint。innodb_max_dirty_pages_pct
2.5 master thread工作方式
innodb1.0.x之前的master thread
master thread具有最高的线程优先级别。其内部由多个循环组成:主循环,后台循环,刷新循环,暂停循环
主循环
每秒一次的操作
日志缓冲刷新到磁盘(总是)
合并插入缓冲(可能)
刷新100个脏页(可能)
误操作会切换到后台循环(可能)
每10秒的操作
刷新100个脏页(可能)
合并至多5个插入缓冲(总是)
日志缓冲刷新到磁盘(总是)
删除无用的undo页(总是)
后台循环
当前用户没有活动或者数据库shutdown时会切换到这个循环,后台循环执行的操作
删除无用的undo页(总是)
合并20个插入缓冲(总是)
跳回到主循环(总是)
不断刷新100个页直到符合条件(可能跳转到刷新循环中完成)
挂起循环
如果刷新循环也没有什么事情可做了,就会切换到挂起循环
innodb_max_dirty_pages_pct=90
innodb1.2.x之前的master thread
引入innodb_io_capacity参数
规则
合并插入缓冲时,合并插入缓冲的数量为innodb_io_capacity值的5%
刷脏时,刷新脏页的数量为innodb_io_capacity
innodb_max_dirty_pages_pct=75
innodb_adaptive_flushing=1通过判断产生redo的速度来决定最合适的刷新脏页的数量
undo(为了支持自动truncate,至少两个),8.0.23前,其初始化大小跟innodb_page_size参数配置有关,默认innodb_page_size为16KB的情况下,初始化大小为10MiB,根据业务并发可能会自动扩展某个undo的大小,额外创建表空间有助于防止表空间扩大参考17.6.3.4 Undo Tablespaces
innodb_purge_threads 默认值4,单表(无法使用多线程)、多表
The innodb_purge_threads setting is the maximum number of purge threads permitted. The purge system automatically adjusts the number of purge threads that are used
innodb1.2.x的master thread
将刷脏操作从master thread心中独立出来,单独采用page cleaner线程来进行刷脏
2.6 innodb关键特性
2.6.1 插入缓冲(性能相关)
1.insert buffer
针对非唯一二级索引(可能不能顺序写入导致的性能问题)
问题:写密集型insert buffer可能占用过多的IBP
2.change buffer
innodb_change_buffer_max_size=25(表示最大占IBP的25%)
2.6.2 double write(安全相关)
IBP刷脏时写double write,分两次写共享表空间,每次1MB,写完即调用fsync同步刷盘,顺序写,最后将double write buffer中的也写入表空间文件(离散写入)
- Innodb_dblwr_pages_written
The number of pages that have been written to the doublewrite buffer. See Section 17.11.1, “InnoDB Disk I/O”.
- Innodb_dblwr_writes
The number of doublewrite operations that have been performed. See Section 17.11.1, “InnoDB Disk I/O”.
Innodb_dblwr_pages_written/Innodb_dblwr_writes(判断当前系统负载)
2.6.3 自适应hash索引(性能相关)
满足条件比较苛刻
2.6.4 异步io
iostat rrqm/s,wrqm/s指标表示每秒进行 merge 的读、写操作数
相关参数:innodb_use_native_aio
2.6.5 刷新邻近页
参数:innodb_flush_neighbors
传统机械盘建议开启该参数,ssd盘建议关闭
2.7 启动、关闭与恢复
关闭:innodb_fast_shutdwon
恢复:innodb_force_recovery
资料来源于姜承尧老师的《MySQL技术内幕 InnoDB存储引擎》

