
潭州课堂25班:Ph201805201 爬虫高级 第五课 sclapy 框架 日志和 settings 配置 模拟登录(课堂笔记)





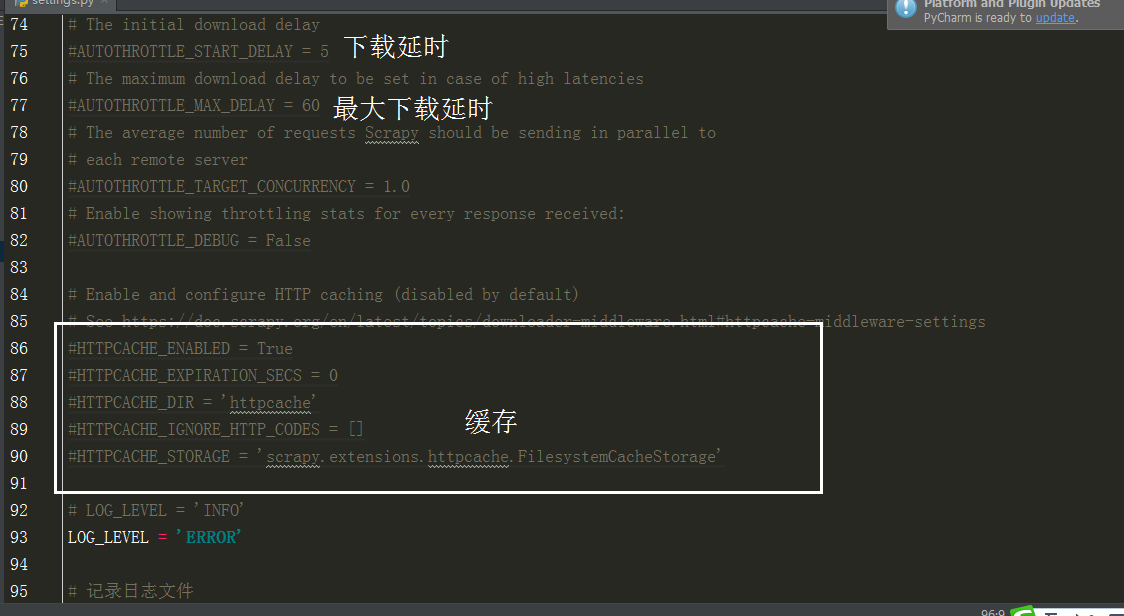
当要对一个页面进行多次请求时,
设 dont_filter = True 忽略去重
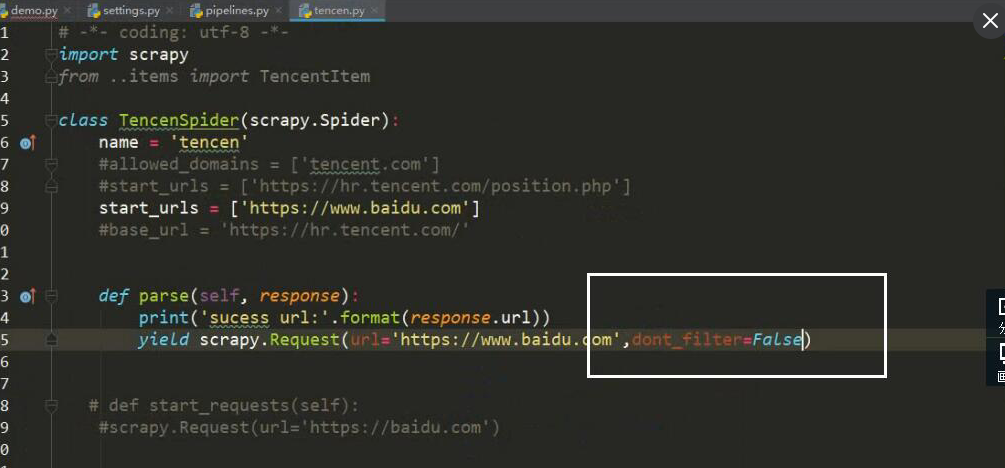
在 scrapy 框架中模拟登录
创建项目

创建运行文件
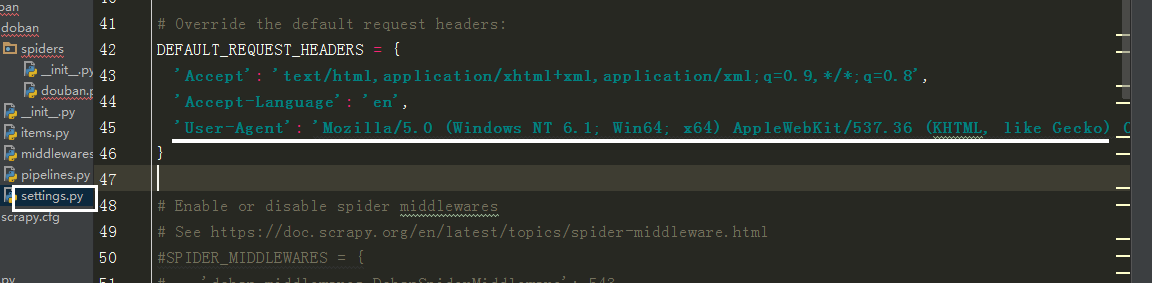
设请求头
# -*- coding: utf-8 -*-
import scrapy
import requests
class DoubanSpider(scrapy.Spider):
name = 'douban'
# allowed_domains = ['douban.com']
# 登录页面
start_urls = ['https://accounts.douban.com/login']
log_url = 'https://accounts.douban.com/login'
c_g_url = 'https://www.douban.com/'
def parse(self, response):
# 如果出现验证码
# 验证码
captcha_url = response.xpath('//img[@id="captcha_image"]/@src').extract_first()
# 如果没有验证码
if not captcha_url:
print('没有验证码')
data = {
'source': 'index_nav',
'redir':'https://www.douban.com/people/184159212/',
'form_email': '13605938437',
'form_password': '17906808lmlmlm',
'login':'登录'
}
else:
print('出现验证码')
captcha_id = response.xpath('//input[@name="captcha-id"]/@value').extract_first()
# 下载图片验证码
with open('1.jpg','wb')as f:
f.write(requests.get(captcha_url).content)
captcha_solution = input('>>>>>')
data = {
'source': 'None',
'redir':'https://www.douban.com/',
'captcha-solution':captcha_solution,
'captcha-id':captcha_id,
'form_email': '账号',
'form_password': '密码',
'login':'登录'
}
# 返回url , 参数 , 回调函数
yield scrapy.FormRequest(url=self.log_url,formdata=data,callback=self.login_after)
def login_after(self,response):
# 判断是否登录成功
text ={
'ck': '7nL_',
'comment':' 哈哈....哈哈....哈哈....'
}
name = response.xpath('//*[@id="db-global-nav"]/div/div[1]/ul/li[2]/a/span[1]//text()').extract()
if name:
print('登录成功,当前用户是%s'%name)
yield scrapy.FormRequest(url=self.c_g_url,formdata=text)
else:print('登录失败')

