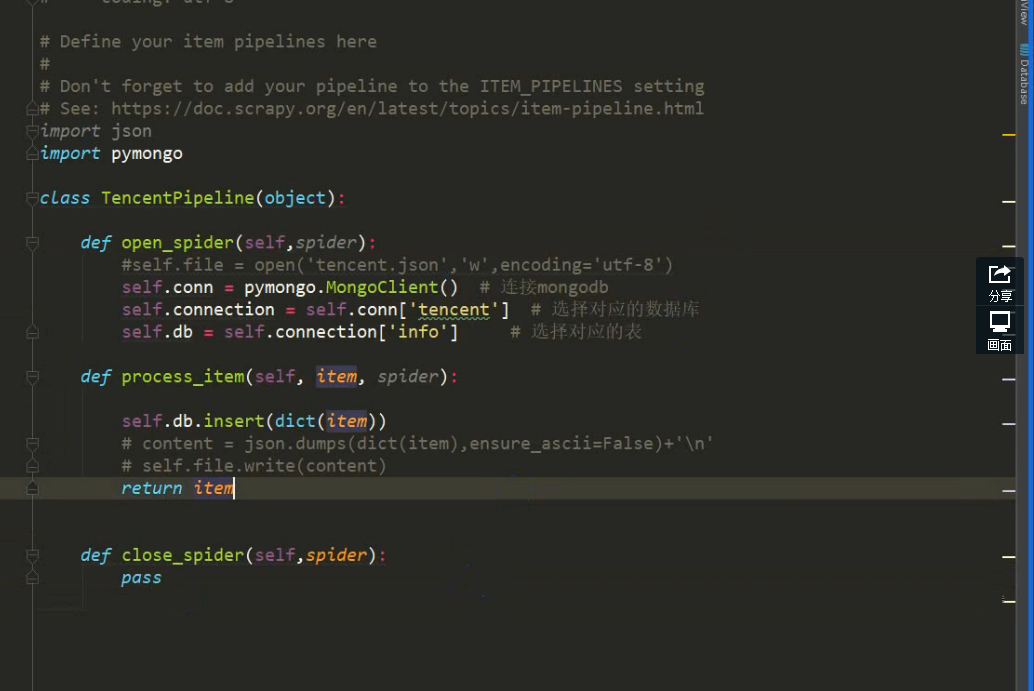
潭州课堂25班:Ph201805201 爬虫高级 第三课 sclapy 框架 腾讯 招聘案例 (课堂笔记)
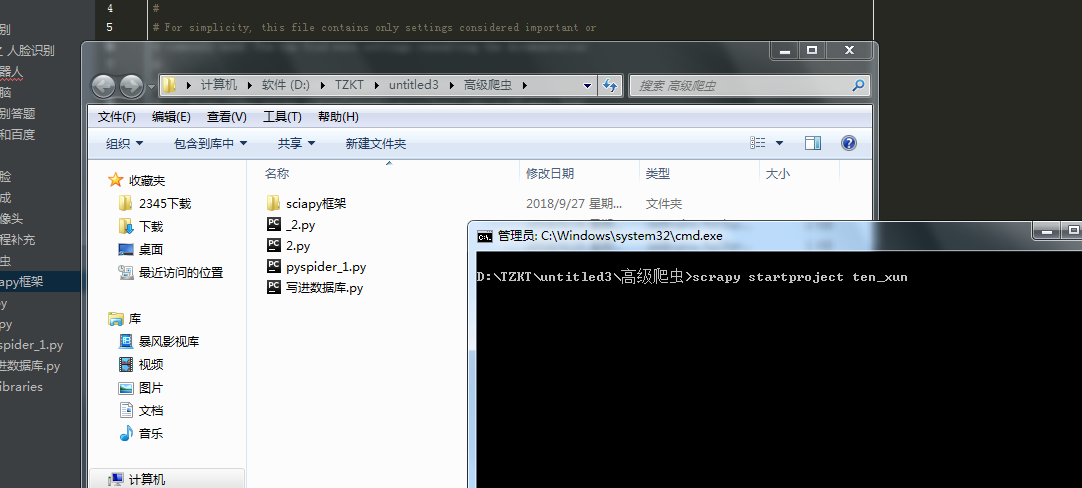
到指定目录下,创建个项目
进到 spiders 目录 创建执行文件,并命名
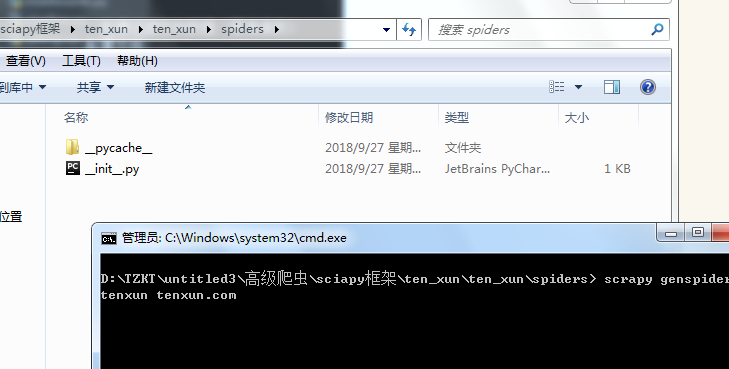
运行调试
执行代码,:
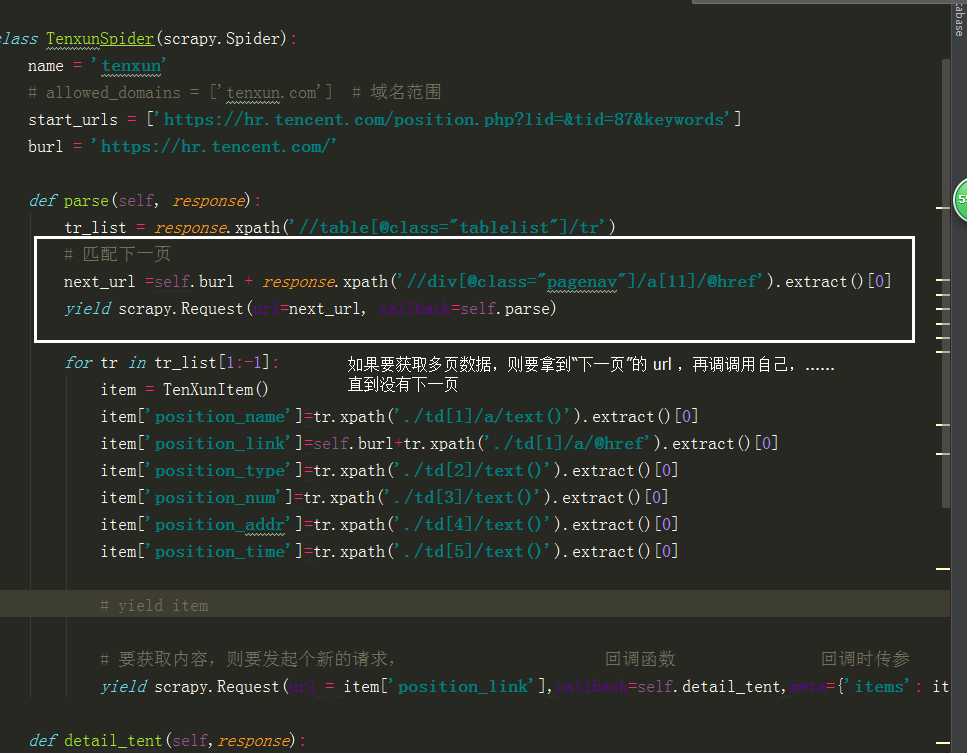
# -*- coding: utf-8 -*-
import scrapy
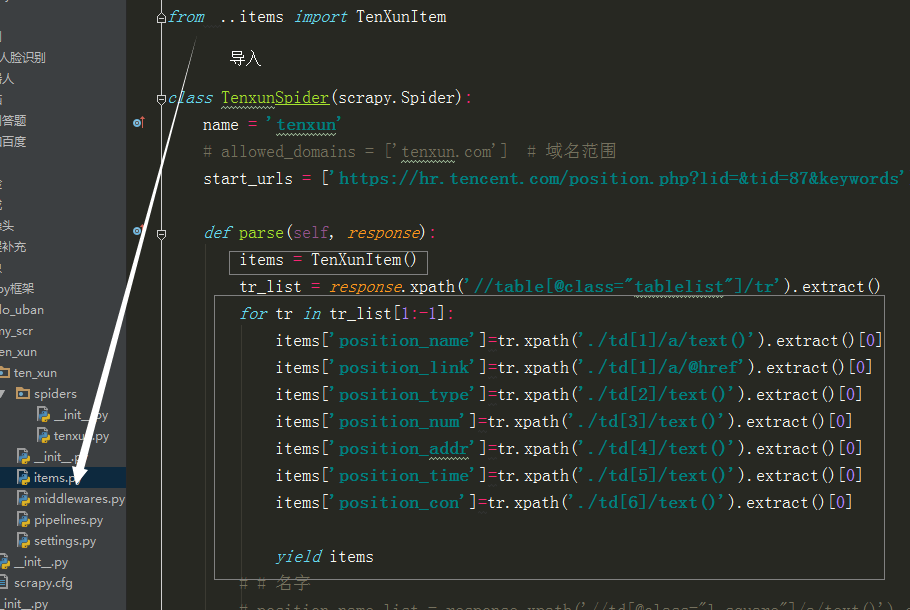
from ..items import TenXunItem
class TenxunSpider(scrapy.Spider):
name = 'tenxun'
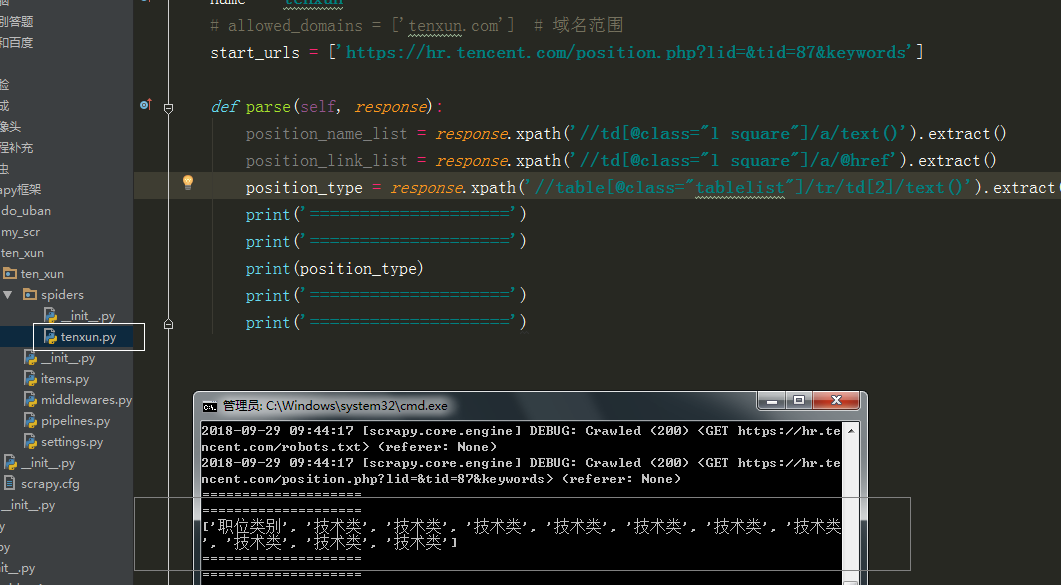
# allowed_domains = ['tenxun.com'] # 域名范围
start_urls = ['https://hr.tencent.com/position.php?lid=&tid=87&keywords']
burl = 'https://hr.tencent.com/'
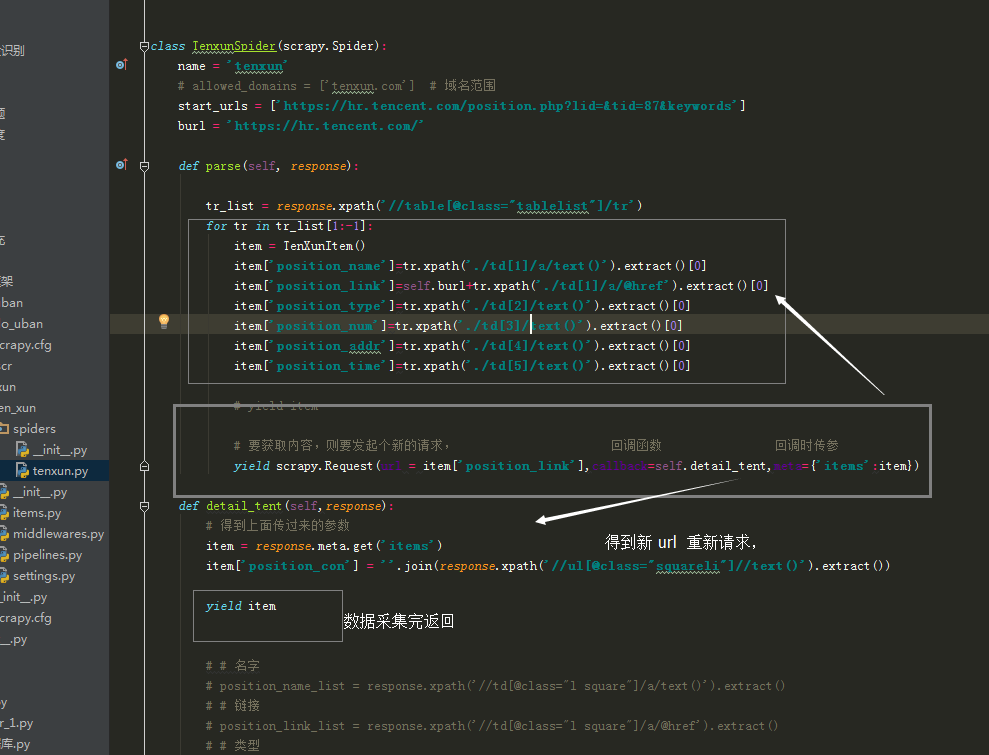
def parse(self, response):
tr_list = response.xpath('//table[@class="tablelist"]/tr')
for tr in tr_list[1:-1]:
item = TenXunItem()
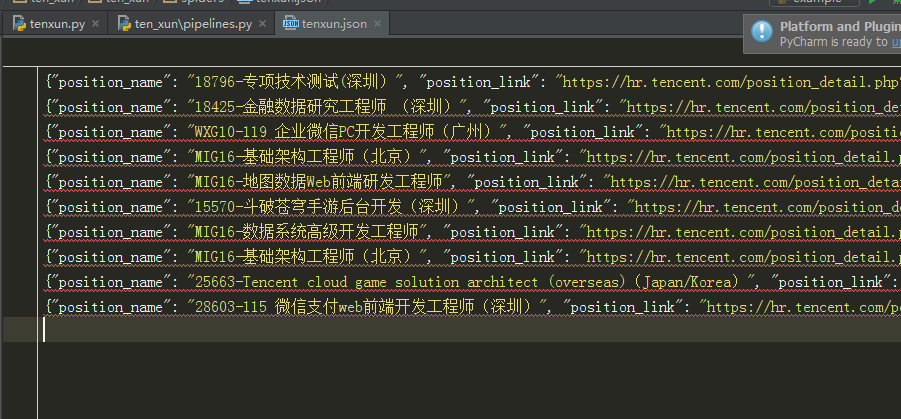
item['position_name']=tr.xpath('./td[1]/a/text()').extract()[0]
item['position_link']=self.burl+tr.xpath('./td[1]/a/@href').extract()[0]
item['position_type']=tr.xpath('./td[2]/text()').extract()[0]
item['position_num']=tr.xpath('./td[3]/text()').extract()[0]
item['position_addr']=tr.xpath('./td[4]/text()').extract()[0]
item['position_time']=tr.xpath('./td[5]/text()').extract()[0]
# yield item
# 匹配下一页
next_url =self.burl + response.xpath('//div[@class="pagenav"]/a[11]/@href').extract()[0]
yield scrapy.Request(url=next_url, callback=self.parse)
# 要获取内容,则要发起个新的请求, 回调函数 回调时传参
yield scrapy.Request(url = item['position_link'],callback=self.detail_tent,meta={'items': item})
def detail_tent(self,response):
# 得到上面传过来的参数
item = response.meta.get('items')
item['position_con'] = ''.join(response.xpath('//ul[@class="squareli"]//text()').extract())
yield item
# # 名字
# position_name_list = response.xpath('//td[@class="l square"]/a/text()').extract()
# # 链接
# position_link_list = response.xpath('//td[@class="l square"]/a/@href').extract()
# # 类型
# position_type_list = response.xpath('//table[@class="tablelist"]/tr/td[2]/text()').extract()
# # 人数
# position_num_list = response.xpath('//table[@class="tablelist"]/tr/td[3]/text()').extract()
# print('====================')
# print('====================')
# print(self.burl + tr_list[2].xpath('./td[1]/a/@href').extract()[0])
# print('====================')
# print('====================')
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
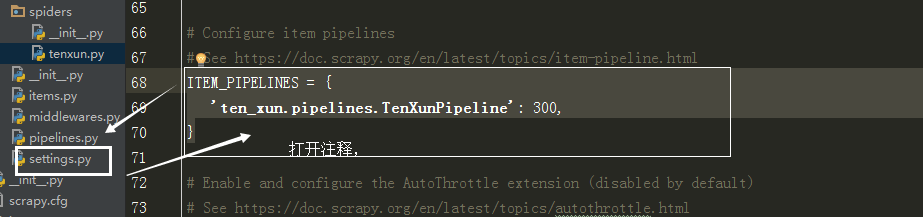
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
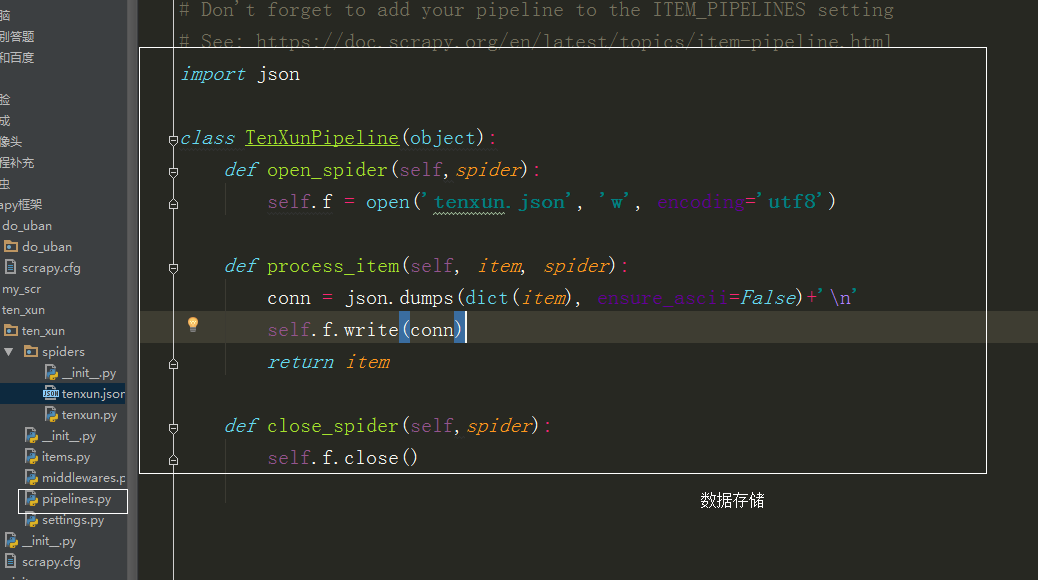
import json
class TenXunPipeline(object):
def open_spider(self,spider):
self.f = open('tenxun.json', 'w', encoding='utf8')
def process_item(self, item, spider):
conn = json.dumps(dict(item), ensure_ascii=False)+'\n'
self.f.write(conn)
return item
def close_spider(self,spider):
self.f.close()
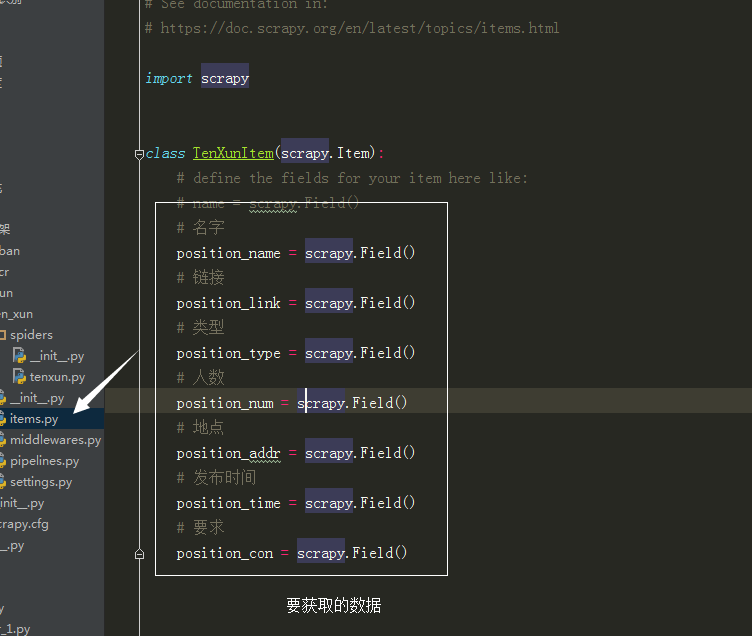
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class TenXunItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 名字
print('00000000000000001111111111111111')
position_name = scrapy.Field()
# 链接
position_link = scrapy.Field()
# 类型
position_type = scrapy.Field()
# 人数
position_num = scrapy.Field()
# 地点
position_addr = scrapy.Field()
# 发布时间
position_time = scrapy.Field()
# 要求
position_con = scrapy.Field()
存入数据库: