
潭州课堂25班:Ph201805201 爬虫高级 第一课 pyspider框架 (课堂笔记)
利用wheel安装
S1: pip install wheel
S2: 进入www.lfd.uci.edu/~gohlke/pythonlibs/,Ctrl + F查找pycurl
这个包名是pycurl-版本-你下载的python版本(如python3.4,就是cp34)-win32/64操作系统),选择你所需要的进行下载
S4: 安装编译包,命令行输入 pip install 你下载的whl文件的位置如(d:\pycurl-7.43.1-cp34-cp34m-win_amd64.whl)
S5: 继续pip install pyspider
pip install 安装好后
在 cmd 中运行
有这出现,说明安装成功
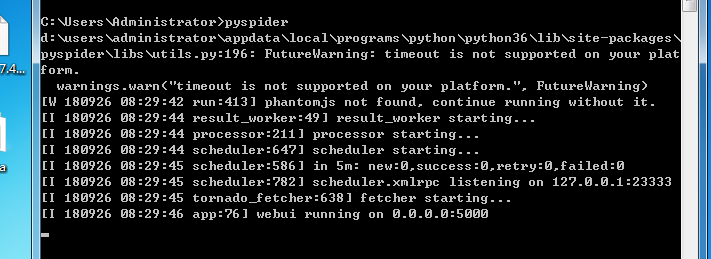
浏览器中输入 http://127.0.0.1:5000/


js渲染的页面数据不容易抓取,因为 http 请求库是能直接运行 js 代码 的 如urlilb, requests
而 pyspider 是支持 js 的
当出现 SSL错误时,
我们在 requests 中添加 参数 verify = False
在pyspider中我没设置 validate_cert = False
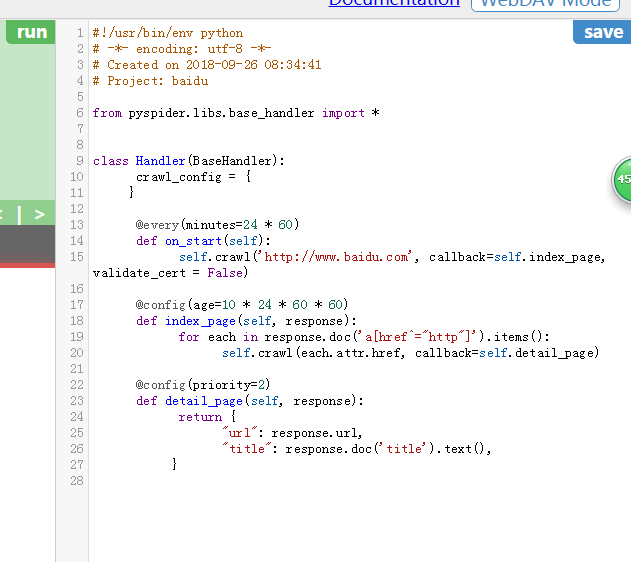
在这里,
on_start 是程序入口,当在web 页面点击 run 的时候调用
self.crawl 生成一个新的爬邓任务,
doc('a[href^="http"]')
匹配 a 标签中的 href 以 http 开头的内容
要在框架中显示js渲染后的页面
Phantomjs 无界面浏览器
在 win 下,下载后,添加环境变量
fetch_type =' js'
删除一个项目
把 name 改为: delete ,状态为 stop 24小时后自动删除
py操作数据库
# -*- coding:utf-8 -*-
# 斌彬电脑
# @Time : 2018/9/26 0026 下午 3:39
import pymysql
# import sclapy
class a():
def __init__(self):
self.db = pymysql.connect(
host = '127.0.0.1', # 远程 ip
port=3306, # mysql 端口
user='binbin', # 用户名
password = 'qwe123', # 密码
db = 'binbin', # 数据库
charset="utf8" # 编码
)
self.cur = self.db.cursor() # 定义游标
def add_items(self):
# def add_items(self,url,title,nr,h):
try:
# 往表格里写数据
sql ="insert into bb(url,title,内容,时间与点击次数) value(%s,%s,%s,%s)"
self.cur.execute(sql,['bindu','a','c','d'])
self.db.commit() # 提交事务
a = self.cur.execute( 'select * from bb' )
print(a)
except Exception as e:
self.db.rollback() # 数据回滚
a = a()
a.add_items()
# print(a)
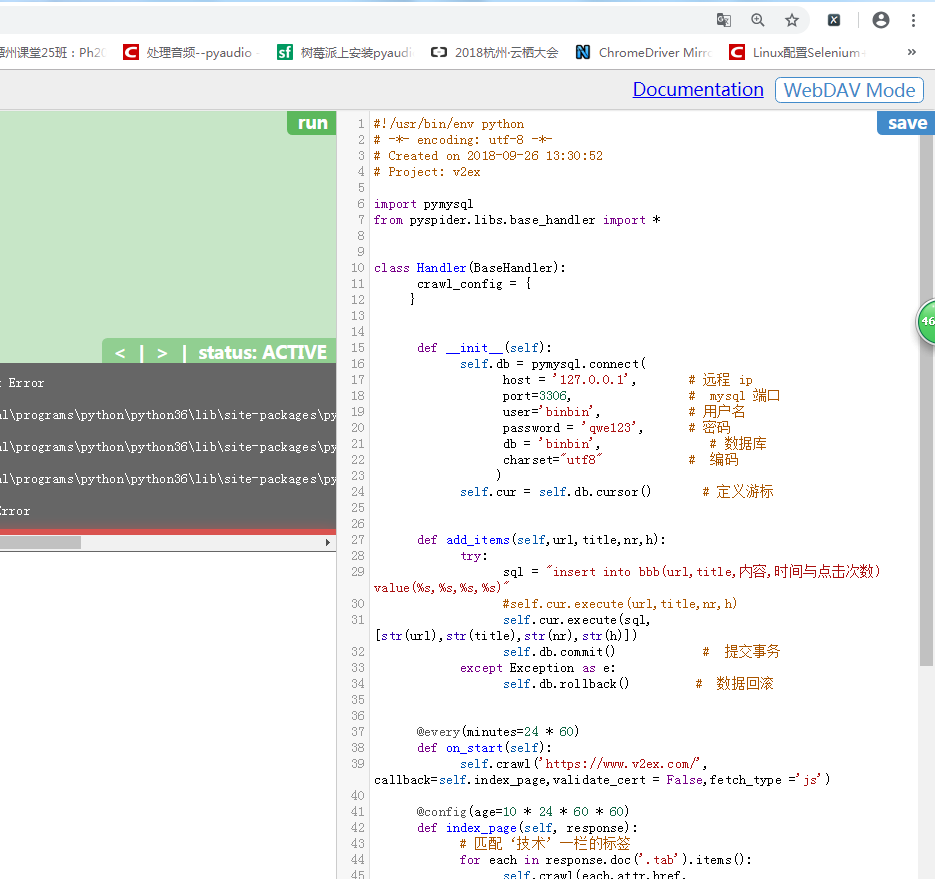
将爬到的数据写入数据库

