潭州课堂25班:Ph201805201 django 项目 第二十九课 docker实例,文件下载前后台实现 (课堂笔记)
docker 实例
:wq!保存退出
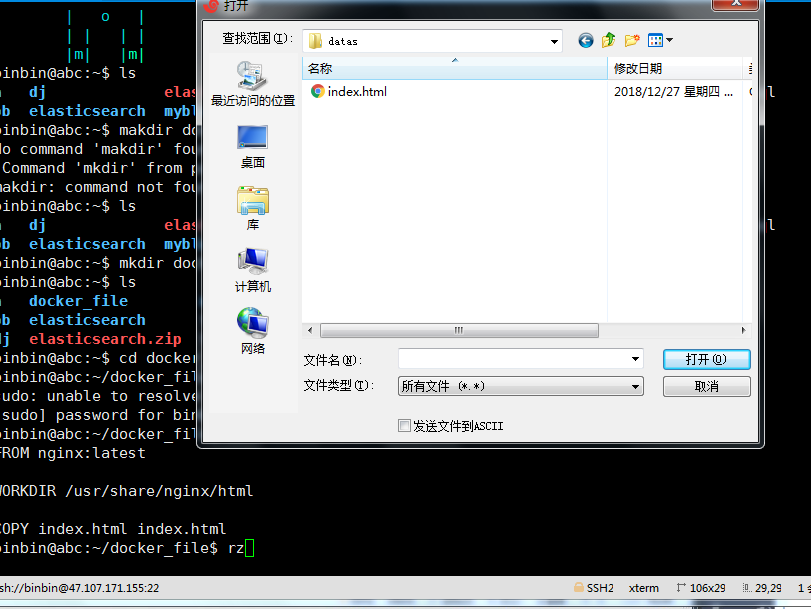
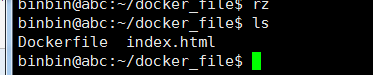
放入一个 html 文件
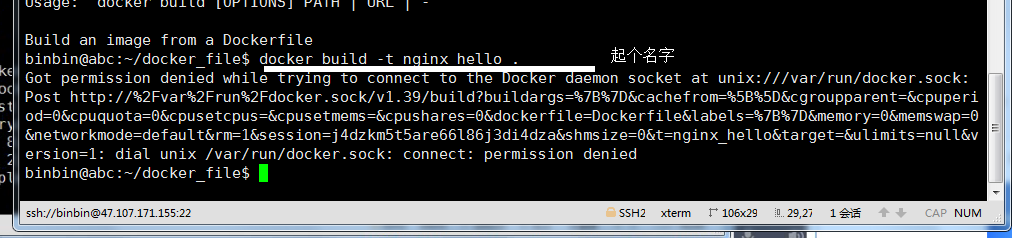
权限不够,加 sudo
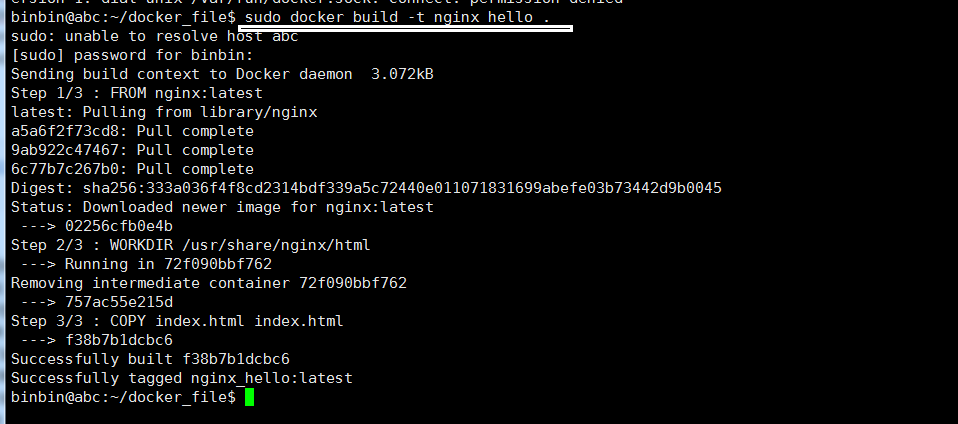
查看本地仓库的 image
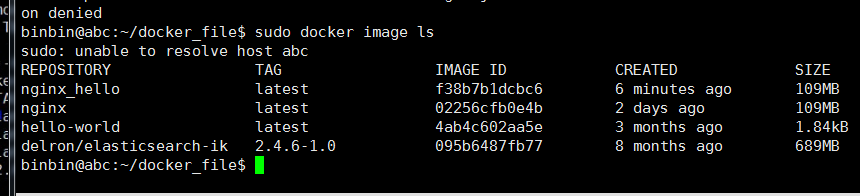
运行 docker

-- name,后跟个运行名, -p 物理机端口映射到容器端口, -d 后台运行,后跟创建的 docker 名
访问网址

查看容器
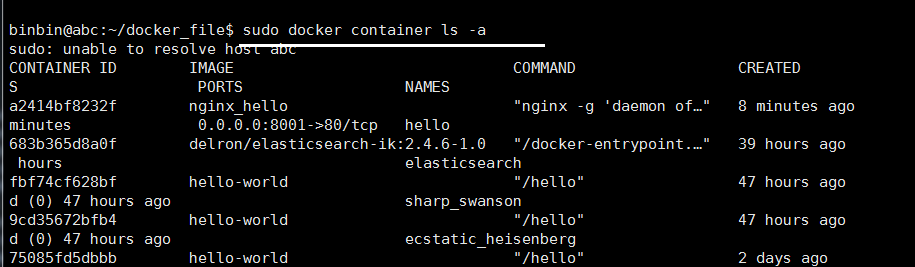
删除 一个容器 rm 跟 id

查看

进入一个正在运行的 docker 中用 exec -it

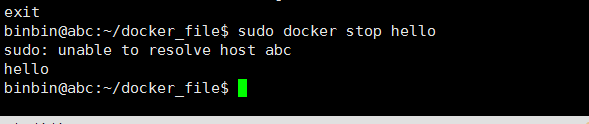
exit 退出
停止
一、文档下载功能
1.分析
业务处理流程:
-
判断前端传的文件id是否为空,对应的文件是否存在
请求方法:GET
url定义:/docs/<int:doc_id>/
请求参数:url路径参数
| 参数 | 类型 | 前端是否必须传 | 描述 |
|---|---|---|---|
| doc_id | 整数 | 是 | 文件id |
此功能是通过向前端返回FileResponse来实现的。
2.后端代码实现
导入 自定义模型 utils.models import ModelBase
-
# 在apps/doc/models.py中定义数据库模型 from django.db import models from utils.models import ModelBase class Doc(ModelBase): """create doc view """ file_url = models.URLField(verbose_name="文件url", help_text="文件url") title = models.CharField(max_length=150, verbose_name="文档标题", help_text="文档标题") desc = models.TextField(verbose_name="文档描述", help_text="文档描述") image_url = models.URLField(default="", verbose_name="图片url", help_text="图片url") author = models.ForeignKey('users.Users', on_delete=models.SET_NULL, null=True) class Meta: db_table = "tb_docs" # 指明数据库表名 verbose_name = "用户" # 在admin站点中显示的名称 verbose_name_plural = verbose_name # 显示的复数名称 def __str__(self): return self.title
迁移:

下载请求 视图:
import logging
import urllib3
import requests
from django.shortcuts import render
from django.http import FileResponse, Http404
from django.utils.encoding import escape_uri_path
from django.views import View
from django.conf import settings
from .models import Doc
# 导入日志器
logger = logging.getLogger('django')
#
# def doc(request):
# return render(request, 'doc/docDownload.html',locals())
#
#
def doc_index(request):
"""渲染
"""
docs = Doc.objects.defer('author', 'create_time', 'update_time', 'is_delete').filter(is_delete=False)
return render(request, 'doc/docDownload.html', locals())
class DocDownload(View):
"""创建下载视图
docs<int:doc_id>/
"""
def get(self, request, doc_id):
# 把不要的字段列出
doc = Doc.objects.only('file_url').filter(is_delete=False, id=doc_id).first()
if doc:
doc_url = doc.file_url
doc_url = settings.SITE_DOMAIN_PORT + doc_url
doc_name = doc.title
try:
# 流控制(不要等到下载完成再打开)
res = FileResponse(requests.get(doc_url, stream=True))
# 仅测试的话可以这样子设置
# res = FileResponse(open(doc.file_url, 'rb'))
except Exception as e:
logger.info("获取文档内容出现异常:\n{}".format(e))
raise Http404("文档下载异常!")
# 拿到文件的后缀名
ex_name = doc_url.split('.')[-1]
# https://stackoverflow.com/questions/23714383/what-are-all-the-possible-values-for-http-content-type-header
# http://www.iana.org/assignments/media-types/media-types.xhtml#image
if not ex_name:
raise Http404("文档url异常!")
else:
ex_name = ex_name.lower()
if ex_name == "pdf":
res["Content-type"] = "application/pdf"
elif ex_name == "zip":
res["Content-type"] = "application/zip"
elif ex_name == "doc":
res["Content-type"] = "application/msword"
elif ex_name == "xls":
res["Content-type"] = "application/vnd.ms-excel"
elif ex_name == "docx":
res["Content-type"] = "application/vnd.openxmlformats-officedocument.wordprocessingml.document"
elif ex_name == "ppt":
res["Content-type"] = "application/vnd.ms-powerpoint"
elif ex_name == "pptx":
res["Content-type"] = "application/vnd.openxmlformats-officedocument.presentationml.presentation"
else:
raise Http404("文档格式不正确!")
doc_filename = escape_uri_path(doc_url.split('/')[-1])
# 设置为inline,会直接打开
res["Content-Disposition"] = "attachment; filename*=UTF-8''{}".format(doc_filename)
return res
else:
raise Http404("文档不存在!")
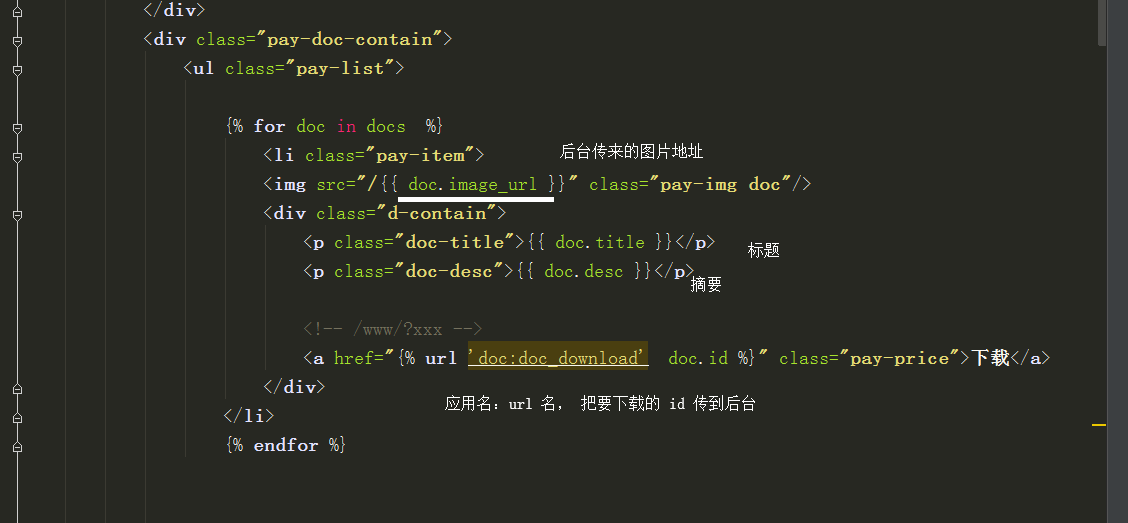
html 文件中