
Lucene的基本使用
一、全文检索与Lucene介绍
1、全文检索
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出然后重新组织的信息,我们称之索引。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
2、Lucene技术
Lucene是apache下的一个开源的全文检索引擎工具包(类库)。它的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。Lucene提供了完整的查询引擎和索引引擎,部分文本分析引擎。
3、Lucene实现全文检索的流程
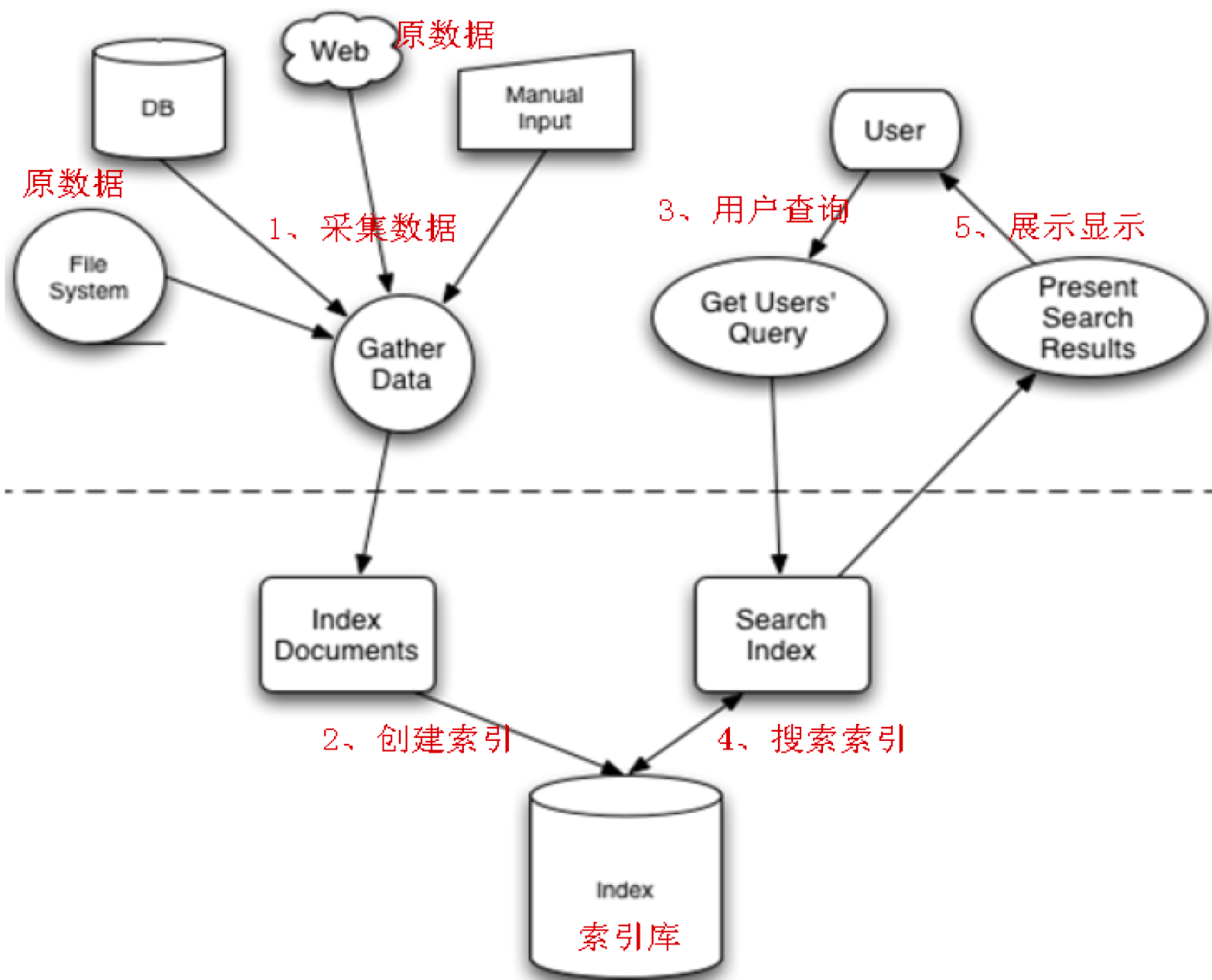
全文检索的流程分为两大部分:索引流程、搜索流程。
- 索引流程:即采集数据构建文档对象分析文档(分词)创建索引。
- 搜索流程:即用户通过搜索界面输入创建查询执行搜索,搜索器从索引库搜索渲染搜索结果。
Lucene是开发全文检索功能的工具包,使用时从官方网站下载,并解压。
官方网站:http://lucene.apache.org/
下载地址:http://archive.apache.org/dist/lucene/java/
下载版本:4.10.3
JDK要求:1.7以上(从版本4.8开始,不支持1.7以下)
二、创建索引
1 //创建索引 2 @Test 3 public void testIndex() throws IOException { 4 //1. 采集数据:(jdbc采集数据通过BookDao调用方法得到结果集) 5 BookDaoImpl dao = new BookDaoImpl(); 6 List<Book> bookList = dao.queryBookList(); 7 8 //2. 遍历book结果集,组装Document数据列表 9 for (Book book : bookList) { 10 Document doc = new Document(); 11 //3. 构建Field域,说白了就是将要存储的数据字段需要用到new TextField对象三个参数的构造方法,book中有多个字段,所以创建多个Field对象。 12 //参数一:域的名称,可随意起;参数二:域对应的值;参数三:是否存储 13 /*Field id = new TextField("id", book.getId().toString(), Field.Store.YES); 14 Field name = new TextField("name",book.getName(), Field.Store.YES); 15 Field price = new TextField("price",book.getPrice().toString(), Field.Store.YES); 16 Field pic = new TextField("pic",book.getPic(), Field.Store.YES); 17 Field description = new TextField("description",book.getDescription(), Field.Store.YES);*/ 18 19 //id不分词 要索引 要存储 20 Field id = new StringField("id", book.getId().toString(), Field.Store.YES); 21 // name 要分词 要索引 要存储 22 Field name = new TextField("name", book.getName(), Field.Store.YES); 23 // price 要分词 要索引 要存储,数字比较特殊 24 Field price = new FloatField("price", book.getPrice(), Field.Store.YES); 25 // pic 不分词 不索引 要存储 26 Field pic = new StoredField("pic", book.getPic()); 27 // description 要分词 要索引 不存储 28 Field description = new TextField("description", book.getDescription(), Field.Store.NO); 29 30 //4. 将Field域所有对象,添加到文档对象中。调用Document.add 31 doc.add(id); 32 doc.add(name); 33 doc.add(price); 34 doc.add(pic); 35 doc.add(description); 36 37 //5. 创建一个标准分词器(Analyzer与StandardAnalyzer),对文档中的Field域进行分词 38 StandardAnalyzer analyzer = new StandardAnalyzer(); 39 //6. 指定索引储存目录,使用FSDirectory.open()方法。 40 FSDirectory directory = FSDirectory.open(new File("/Users/Shared/index")); 41 //7. 创建IndexWriterConfig对象,直接new,用于接下来创建IndexWriter对象 42 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer); 43 //8. 创建IndexWriter对象,直接new 44 IndexWriter writer = new IndexWriter(directory, config); 45 //9. 添加文档对象到索引库输出对象中,使用IndexWriter.addDocuments方法 46 writer.addDocument(doc); 47 //10. 释放资源IndexWriter.close(); 48 writer.close(); 49 } 50 }
三、搜索流程
1 //搜索 2 @Test 3 public void testQuery() throws IOException { 4 // 1. 创建一个Directory对象,FSDirectory.open指定索引库存放的位置 5 FSDirectory directory = FSDirectory.open(new File("/Users/Shared/index")); 6 // 2. 创建一个IndexReader对象,DirectoryReader.open需要指定Directory对象 7 IndexReader indexReader = DirectoryReader.open(directory); 8 // 3. 创建一个Indexsearcher对象,直接new,需要指定IndexReader对象 9 IndexSearcher indexSearcher = new IndexSearcher(indexReader); 10 // 4. 创建一个TermQuery对象,直接new,指定查询的域和查询的关键词new Term(域名称,关键词) 11 TermQuery query = new TermQuery(new Term("name", "java")); 12 // 5. 执行查询,IndexSearcher.search,需要指定TermQuery对象与查询排名靠多少名前的记录数,得到结果TopDocs 13 TopDocs docs = indexSearcher.search(query, 10); 14 // 6. 遍历查询结果并输出,TopDocs.totalHits总记录数,topDocs.scoreDocs数据列表,通过scoreDoc.doc得到唯一id,再通过IndexSearcher.doc(id),得到文档对象Document再Document.get(域名称)得到结果 15 System.out.println("查询总记录数为:"+docs.totalHits); 16 for (ScoreDoc scoreDoc : docs.scoreDocs) { 17 //得到文档 18 int id = scoreDoc.doc; 19 Document doc = indexSearcher.doc(id); 20 System.out.println("id:"+doc.get("id")); 21 System.out.println("name:"+doc.get("name")); 22 System.out.println("price:"+doc.get("price")); 23 System.out.println("pic:"+doc.get("pic")); 24 System.out.println("description:"+doc.get("description")); 25 } 26 // 7. 关闭IndexReader对象 27 indexReader.close(); 28 }
四、Field域

五、搜索
1、通过Query子类搜索
①通过MatchAllDocsQuery(查询所有文档)
1 @Test 2 public void testFindall() throws Exception{ 3 //matachalldocsquery 4 Query query = new MatchAllDocsQuery(); 5 //创建一个indexSearcher 对象 6 //通过indexSearcher 调用search方法查询 7 doSearcherBy(query); 8 }
②TermQuery
1 @Test 2 public void testTermQuery() throws IOException { 3 TermQuery termQuery = new TermQuery(new Term("name", "apache")); 4 doSearchBy(termQuery); 5 }
③NumericRangeQuery
1 @Test 2 public void testNumbericRange() throws IOException{ 3 //第一个参数:域的名称 4 //第二个参数:最小值 5 //第三个参数:最大值 6 //第四个参数:是否包含最小值 7 //第五个参数:是否包含最大值 8 NumericRangeQuery query = NumericRangeQuery.newFloatRange("price", 55f, 60f, false, false); 9 doSearcherBy(query); 10 }
④BooleanQuery
1 @Test 2 publicvoid booleanQuery() throws Exception { 3 BooleanQuery query = new BooleanQuery(); 4 Query query1 = new TermQuery(new Term("id", "3")); 5 Query query2 = NumericRangeQuery.newFloatRange("price", 10f, 200f,true, true); 6 //MUST:查询条件必须满足,相当于AND 7 //SHOULD:查询条件可选,相当于OR 8 //MUST_NOT:查询条件不能满足,相当于NOT非 9 query.add(query1, Occur.MUST); 10 query.add(query2, Occur.SHOULD); 11 System.out.println(query); 12 doSearcherBy(query); 13 }
2、通过QueryParser搜索
①查询语法
查看语法,Query对象执行的查询语法可通过System.out.println(query),查看。
第一种简单的语法:
域名+":"+搜索的关键词 例如:name:java 表示搜索域名为name ,其关键词为java的文档对象。
第二种:查询所有的文档
*:*
第三种:数值范围的语法:
域名+“:”+[数值 TO 数值] 表示数值范围,并且包括数值。如果不包括数值 用"{}"比如:
price:[55.0 TO 70.0] 等同于 55=< price <=70
price:{55.0 TO 70.0] 等同于 55 < price <=70
数值范围类的查询语法,不支持在queryparser中查询。语法是没有错误的。在solr中可以查询出来。
第四种:组合条件查询
Occur.MUST 查询条件必须满足,相当于and
+(加号)
Occur.SHOULD 查询条件可选,相当于or
空(不用符号)
Occur.MUST_NOT 查询条件不能满足,相当于not非
-(减号)
1)+条件1 +条件2:两个条件之间是并且的关系and
例如:+filename:apache +content:apache
2)+条件1 条件2:必须满足第一个条件,忽略第二个条件
例如:+filename:apache content:apache
3)条件1 条件2:两个条件满足其一即可。
例如:filename:apache content:apache
4)-条件1 条件2:必须不满足条件1,要满足条件2
例如:-filename:apache content:apache
第二种写法:
- 条件1 AND 条件2
- 条件1 OR 条件2
- 条件1 NOT 条件2
②MultiFieldQueryParser
1 @Test 2 publicvoidtestMultiFieldQueryParser() throws Exception { 3 // 可以指定默认搜索的域是多个 4 String[] fields = { "name", "description" }; 5 // 创建一个MulitFiledQueryParser对象 6 QueryParser parser = new MultiFieldQueryParser(fields, new IKAnalyzer()); 7 // 指定查询语法,如果不指定域,就搜索默认的域 8 Query query = parser.parse("lucene"); 9 // 2、执行搜索 10 doSearcherBy(query); 11 }
