Elasticsearch搜索功能的实现(二)--Elasticsearch中的核心概念与DSL
一、Elasticsearch中的核心概念
1、索引 index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引
一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字
2、映射 mapping
ElasticSearch中的映射(Mapping)用来定义一个文档
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分词器、是否被索引等等,这些都是映射里面可以设置的
3、字段Field
相当于是数据表的字段|列
4、字段类型 Type
每一个字段都应该有一个对应的类型,例如:Text、Keyword、Byte等
5、文档 document
一个文档是一个可被索引的基础信息单元,类似一条记录。文档以JSON(Javascript Object Notation)格式来表示;
6、集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能
7、节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中
这意味着,如果在网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中
在一个集群里,可以拥有任意多个节点。而且,如果当前网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
8、分片和副本 shards&replicas
8.1 分片
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片
当创建一个索引的时候,可以指定你想要的分片的数量
每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上
分片很重要,主要有两方面的原因
允许水平分割/扩展你的内容容量
允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户来说,这些都是透明的
8.2 副本
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做副本分片,或者直接叫副本
副本之所以重要,有两个主要原因
- 在分片/节点失败的情况下,提供了高可用性。
注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的 (错峰 和redis cluster一样)
- 扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行
每个索引可以被分成多个分片。一个索引有0个或者多个副本
一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数量可以在索引
创建的时候指定在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变分片的数量
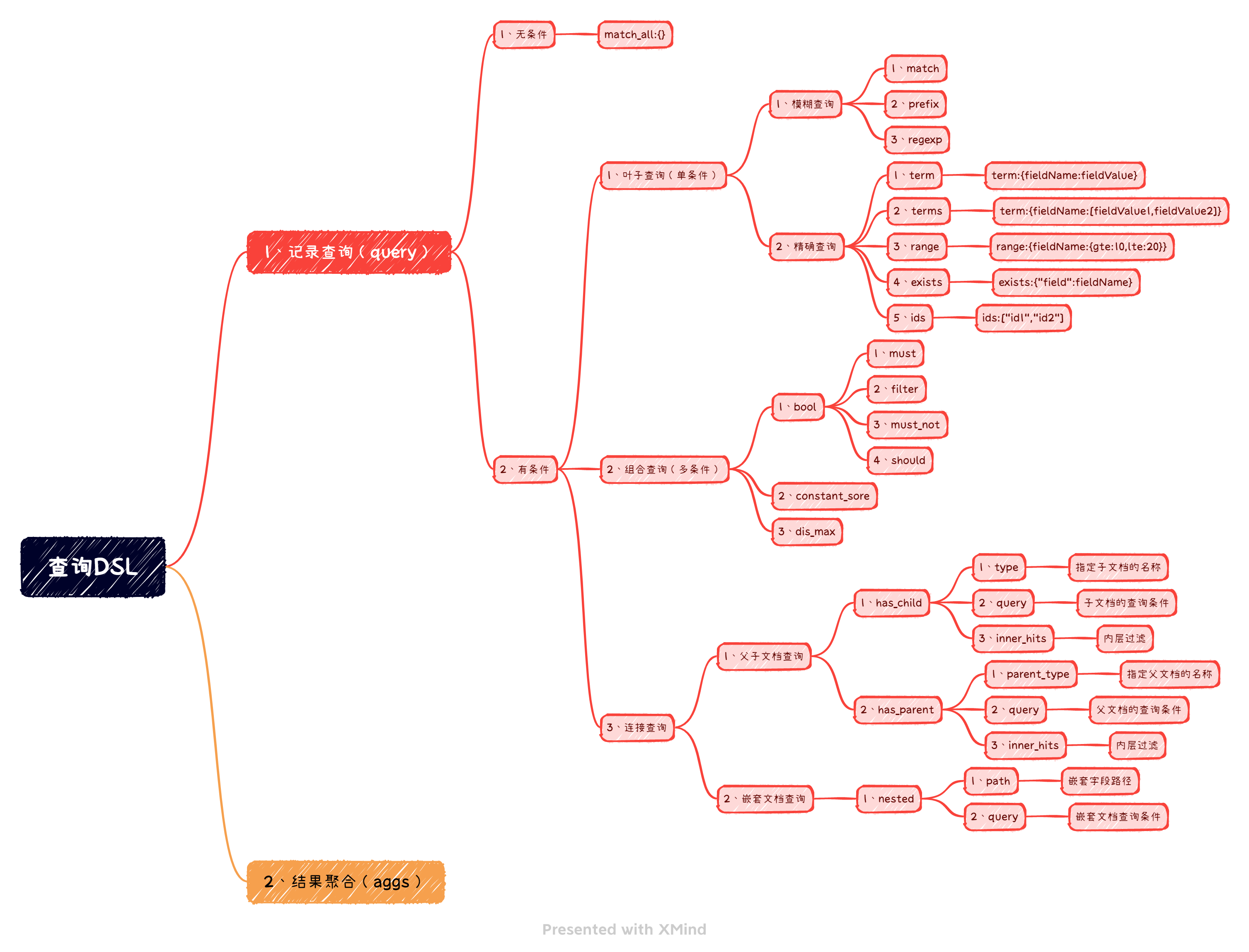
二、DSL
Domain Specific Language
Elasticsearch提供了基于JSON的DSL来定义查询。
DSL由叶子查询子句和复合查询子句两种子句组成。