

正则
正则:用于检验字符串的格式
正则定义: var reg=new RegExp()
var reg=/格式/
正则的方法:
test() 匹配
exec() 捕获
正则的修饰符:i 区分大小写
g 代表全局匹配
m 代表多行匹配
使用方法:
var reg=new RegExp("hello",g)
var reg=/hello/gi
补:字符串中与正则相关的方法:
match() 查找一个或多个与正则相匹配的,有就返回查找的结果,没有就null
案例:

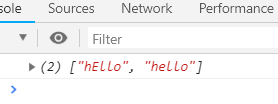
search() 匹配和正则相同的字符,有就返回索引,没有就是-1
案例:

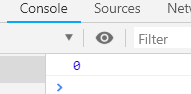
replace() 匹配与正则相同的,并替换 ,返回的是替换后的字符串
案例:
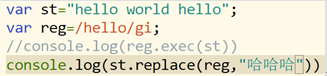
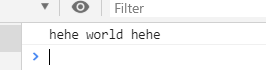
正则的方括号:
[abc] 代表查找方括号中的任何字符
[^abc] 代表查找任何一个不在方括号之间的字符
[0-9] 查找0到9之间的数字
[a-z] 查找任何小写a到小写z的字符
[A-Z] 查找任何大写A到大写Z的字符
[A-z] 查找任何 大写A到小写z的字符
(red|blue|green) 查找任何指定的选项
元字符:
. 代表单个字符
\w 代表单词字符 包括数字 字母 _
\W 代表非单词字符
\d 代表数字
\D 代表非数字
\s 代表空白字符
\S 代表非空白字符
\b 代表单词边界
\B 代表非单词边界
量词:
n+ 代表至少1个n的字符
n* 代表0个或多个n
n? 代表0个或1个n
n{x} 包含x个n
n{x,} 包含至少x个n
n{x,y} 包含大于等于x个小于等于y个n
n$ 包含以n结尾的字符串
^n 包含以n开头的字符串
?=n 指定字符串后面紧跟的n的字符串
正则的懒惰性:
每一次在exec()中捕获的时候,只捕获第一次匹配的内容,而不往下捕获了。我们把这叫正则的懒惰性,每一次捕获的位置都是从0开始的


解决方法:
修饰符g
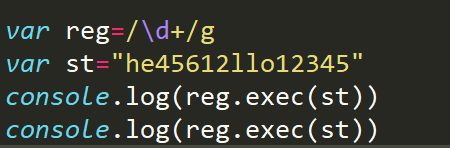
结果

正则的贪婪性:
每一次匹配都是按照最长的出结果,我们把这种功能叫正则的贪婪性
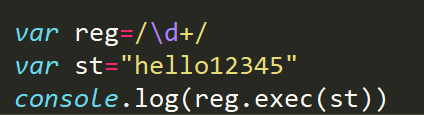
结果
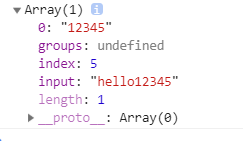
分组捕获:
var reg=/(a)(b)/ 就相当于大正则里面带了两个小正则
分组捕获的作用:
1、改变优先级
2、分组引用
案例:
 理解:
理解:
Reg中的规则是第一个是一个分组 且是一个单词字符 第二个是个分组引用要求和第一组一模一样,第三个是第二个分组且是一个单词字符,第四个是一个分组引用,要求和第二组一模一样。

