20189221 2018-2019-2 《密码与安全新技术专题》第六周作业
20189221 2018-2019-2 《密码与安全新技术专题》第六周作业
课程:《密码与安全新技术专题》
班级: 201892
学号:20189221
上课教师:谢四江
上课日期:2019年5月7日
必修/选修: 选修
1.本次讲座的学习总结
讲座主题:漏洞挖掘及攻防技术
1.1 背景及意义
-
安全漏洞定义:
指信息系统在设计、实现或者运行管理过程中存在的缺陷或不足,从而使攻击者能够在未授权的情况下利用这些缺陷破坏系统的安全策略。
-
安全漏洞事件:
- openssl (心脏出血);
- bash:原因是未检查输入边界;
- 脱裤门:主要包括天涯、CSDN、人人、多玩、cnbeta、QQ关系数据库、携程;
- 棱镜门;
1.2 常见漏洞挖掘技术
-
手工测试——最古老:
手工测试是由测试人员手工分析和测试被测目标,发现漏洞的过程,是最原始的漏洞挖掘方法。
- 优点:能发挥人的主观能动性
- 缺点:人无规律可循、不可大规模
-
补丁对比:
一种通过对比补丁之间的差异来挖掘漏洞的技术。
- 优点:发现速度快
- 缺点:已知漏洞
补丁技术是实际漏洞挖掘中运用得十分普遍,对于定位漏洞的具体位置、寻找漏洞解决方式具有十分积极的现实意义。
-
程序分析
- 静态:在不运行程序的条件下,通过一系列分析的技术对代码进行扫描。
- 动态:在运行计算机程序的条件下,验证代码是否满足规范性、安全性等指标的一种代码分析技术。
- 优点:覆盖率100%,自动化程度高
- 缺点:容易有漏报和误报
- 数据流分析:Fortify SCA、Coverity Prevent、FindBugs等
- 污点分析:Pixy、TAJ(基于WALA)
- 符号执行:Clang、KLEE
- 模型检测:BLAST、MAGIC、MOPS
-
二进制审核
二进制审核是源代码不可得,通过逆向获取二进制代码,在二进制代码层次上进行安全评估
- 优点:覆盖率高,自动化程度高
- 缺点:逆向导致信息丢失,可能会引入逻辑错误。
-
模糊测试
模糊测试是通过向被测目标输入大量的畸形数据并检测异常来发现漏洞。
- 优点:无须源码、误报低、自动化程度高
- 缺点:覆盖率低
1.3 漏洞挖掘示例
-
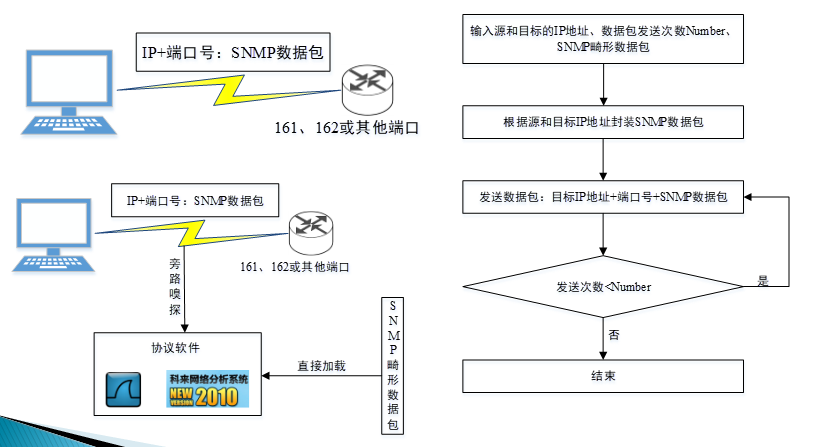
路由器
- 当远程向路由器的161端口发送大量畸形SNMP Get/Set请求报文时,Cisco路由器和华为路由器的进程Agent出现CPU使用率异常,分别为98%和100%。
- 当远程发送SNMP空数据包时,Cisco路由器和华为路由器的CPU使用率出现异常,但远小于100%,发生“轻度拒绝服务”。
- 当远程发送一个畸形ASN.1/BER编码(超长字符串)的SNMP数据包时,wireshark捕获并解析数据包,导致wireshark 1.4等多个版本栈溢出,导致空指针引用并崩溃。
- 当向SNMP协议端口(161)远程发送一个使用“\x”等字符构造的畸形UDP数据包,科来网络分析系统7.2.1及以前版本均会因边界条件检查不严导致崩溃。
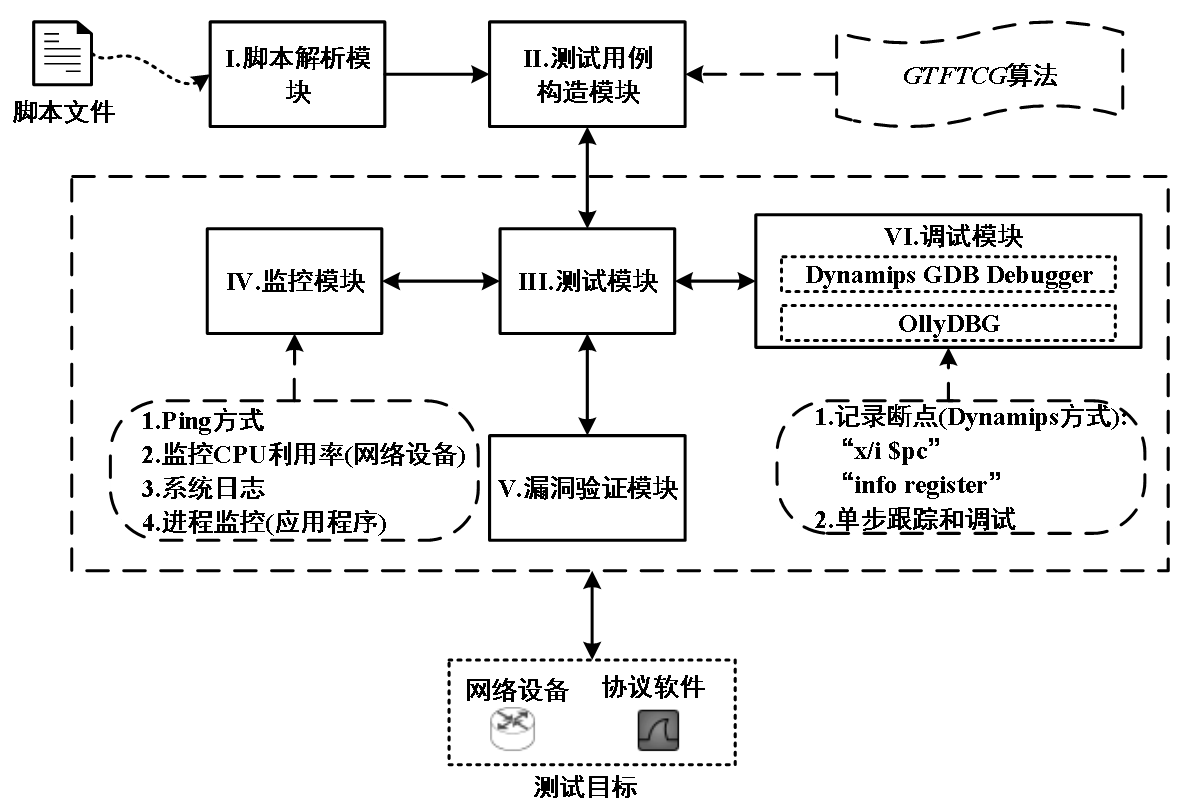
![]()
-
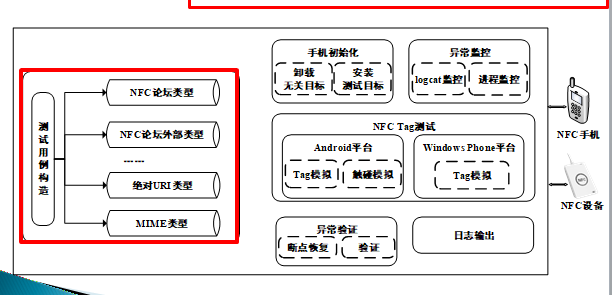
NFC漏洞挖掘
-
目标选择:NFC手机系统和应用!
从数据可以看出,NFC手机逐渐开始流行和推广。
NFC(Near Field Communication)技术是一种近距离的双向高频无线通信技术,能够在移动终端、智能标签(Tag)等设备间进行非接触式数据交换。
NFC技术具有通信距离短、一次只和一台设备连接(1V1)、硬件安全模块加密等特点,具有较好的保密性和安全性。
![]()
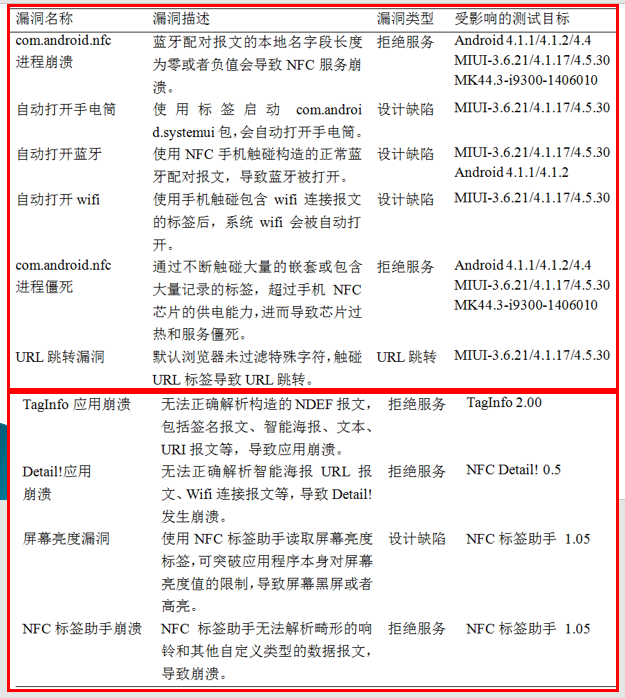
结果:
![]()
-
1.4 攻防实例
- 被动防御
-
路由器
![]()
- 过滤特殊字符,eg. 科来网络分析系统对\x的处理;
- 限制特定端口的传输速率;
- 阻塞SNMP请求的端口;
- 折中:编写ACL
-
NFC
![]()
- 协议解析:检查长度字段、数值范围、格式化字符串、特殊字符等;
- 设计缺陷:修改设计逻辑,例如,蓝牙、wifi、屏幕亮度等;
- 被动防御:滞后性
-
- 主动防御
- 针对路由器和软件
- 成熟产品
- 入侵检测(Snort/OSSEC HIDS/BASE/Sguil……)
- 防火墙
- 杀毒软件
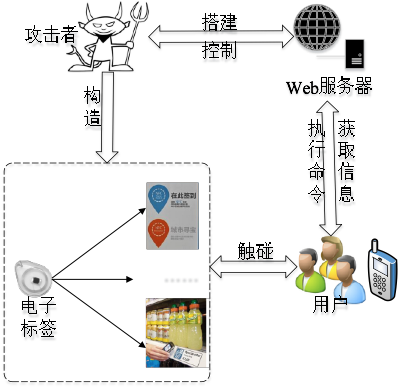
2.学习中遇到的问题及解决
问题1:模糊测试
问题1解决:
模糊测试是一种介于完全的手工渗透测试与完全的自动化测试之间的安全性测试类型。它充分利用了机器的能力:随机生成和发送数据;同时,也尝试将安全专家在安全性方面的经验引入进来。
从执行过程来说,模糊测试的执行过程非常简单:
- 测试工具通过随机或是半随机的方式生成大量数据;
- 测试工具将生成的数据发送给被测试的系统(输入);
- 测试工具检测被测系统的状态(如是否能够响应,响应是否正确等);
- 根据被测系统的状态判断是否存在潜在的安全漏洞。
模糊测试的框架有:
-
antiparser
antiparser框架以python语言编写,是一个专门帮助模糊测试器创建随机数据的API。该工具可以跨平台,仅仅要求有python解释器就行。
你可以在这个网站得到该框架的源码和一些文档:http://antiparser.sourceforge.net/
说明:
该框架很简单,且缺少一些自动化功能,文档较少。总的来说,他不适合做一些复杂的工作。
-
Dfuz
该框架是Diego Bauche用C开发的,经常更新。该框架已经发现了很多漏洞。Dfuz是开源的,可以下载。但是该框架的源代码采用了一种严格的开原许可,未得到作者的允许不可以使用复制该框架的源代码。
网站:http://www.genexx.org/dfuz/
说明:
该框架学习曲线比较平坦,开发效率比较高,Dfuz要求开发者完全使用框架的脚本语言来进行编程,没法利用成熟的语言发挥更大的威力。不过总的来说还是可以的。
-
SPIKE
最广泛使用最知名的一个框架。使用C语言编写,提供了一系列允许快速和高效的开发网络协议模糊测试器的API。在SPIKE中,数据结构被分解表示成块,也叫SPIKE,这个块同时包含二进制数据和块大小。
说明:
SPIKE只有零星的文档,一些还是废弃的,但是我们可以找到很多工作样例。SPIKE缺乏对windows的支持。最大的贡献就是基于块的模糊测试方法。很多其他的模糊测试框架也采用了这样的方法。
-
Peach
python编写的,是一个开源的框架。
Peach体系结构允许研究者聚焦于一个个的特定的协议的子组件,然后组合起来创建完整的模糊测试器。这种方法可能不如基于块的开发速度,但是对代码的复用的支持比其他模糊测试工具好。
说明:
Peach处于活跃开发中,但是文档少,学习起来比较困难。
-
通用目的模糊测试器(GPF)
GPF可以产生无数个测试,无数个变异。(其他的根据规则不会是无数个),该框架主要的有点是可以用很低的成本建立并运行一个模糊测试器,通过GPF的多种模式对外提供功能。
-
Autodafe
这个框架可以简单的描述成下一带的SPIKE,该框架能够对网络协议和文件格式进行模糊测试。他最吸引人的就是调试组件。
问题2:NFC相关
问题2解决:
-
NFC主要应用于:
- 1、启动服务,将NFC用于“开启”另一种服务(例如为数据传输开启另一条通信链接);
- 2、点到点,NFC可以用于实现两个装置之间的通信;
- 3、付款和票务,将NFC搭建在新兴的智能票务和电子付款基础设施之上。
因此可以在支付,身份识别,读Tag, 签到等多种场景下用到NFC,不仅仅只有公交卡的应用。
-
NFC卡和其他卡的区别?
- NFC是在RFID的基础上发展而来,NFC从本质上与RFID没有太大区别,都是基于地理位置相近的两个物体之间的信号传输。
- 但NFC与RFID还是有区别的,NFC技术增加了点对点通信功能,可以快速建立蓝牙设备之间的P2P(点对点)无线通信,NFC设备彼此寻找对方并建立通信连接。P2P通信的双方设备是对等的,而RFID通信的双方设备是主从关系。
- ID卡它是身份识别卡的总称, ID 卡分接触型和非接触型(RF类型), 非接触类的无线RF类的又可称 RFID 卡, RFID 卡又有远距离的和近距离的。NFC 卡也就是近场卡,属于近距离卡。
3.本次讲座的学习感悟、思考等
真正进行漏洞挖掘需要具备的知识
从事漏洞挖掘工作需要具备的知识是极其广泛的,并且随着时间在不断改变,也取决于你所研究的对象(web程序、桌面程序、嵌入式等等)。不过,万变不离其宗,所需要掌握的知识领域却总可以认为是确定的,我认为大致可以分为以下四个方面:
-
程序正向开发技术。这是一个开发者需要掌握的能力,包括编程语言、系统内部设计、设计模式、协议、框架等。拥有丰富编程经验与开发能力的人在漏洞挖掘过程中往往比那些只对安全相关领域有所了解的人员对目标应用能有更深入的理解,从而有更高的产出。
-
攻防一体的理念。这些知识涵盖了从基本的安全原则到不断变换的漏洞形态及漏洞缓解措施。攻击和防御结合的理念,能够有效帮助研究者既能够发现漏洞,同时也能够快速给出有效的漏洞缓解措施和规避方法。
-
有效使用工具。能够高效的使用工具能够快速将思路转化为实践,这需要通过花时间去学习如何配置和使用工具,将其应用于自己的任务并构建自己的工作流程来不断积累经验。更进一步,需要深入掌握所使用工具的原理,以及如何对其进行二次开发,以使得其能够更加高效的应用于当前的工作实际。事实上,我认为面向过程的学习方法往往比面向工具的学习方法更加高效以及有价值,当自己发现一个在使用一个工具遇到瓶颈时,先不要退缩,尝试去改造它,或者通过自己动手实践去完成能够适应当前工作的工具,这往往能够帮助快速积累大量实践经验。帮助我们以后更加高效的去实践漏洞挖掘工作。
-
对目标应用的理解。最后,也是最重要的,作为一个漏洞挖掘人员,对自己研究的应用程序在安全性方面必须要比这个程序的开发者或维护者有更深的理解。这样你才能尽可能的发现这个程序中的漏洞并修复它。
要学的还有很多,须日日精进,务求学有所成。
4.漏洞挖掘研究现状
A study on software vulnerability prediction model
作者:P. K. Shamal ; K. Rahamathulla ; Ali Akbar
投稿:2017 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET)
年份:2017
主题:本文介绍了两种类型的软件漏洞模型用于预测软件中的漏洞组件。
许多软件系统,特别是Web应用程序在其生命周期中报告了漏洞问 因此,开发安全软件是软件工程的关键部分。软件是程序和相关数据的集合。因此,由于资源有限,无法对所有软件组件进行详细的漏洞检查。开发人员只需将检查重点放在易受攻击性上。因此,需要一种机制来检测软件中的易受攻击的文件。该解决方案是一种软件漏洞预测模型。软件漏洞预测模型将软件组件(如模块,文件等)分为两类; 脆弱而干净。因此,开发人员需要将他们的漏洞检查仅关注于易受攻击的类中的文件。
软件漏洞预测模型基于机器学习。分类器经过训练,具有已知的漏洞及其功能。
在基于软件度量的预测模型中,不同的软件度量被用作软件漏洞的指示符。在基于文本分析的方法中,软件的源代码用作预测模型的输入。源代码转换为令牌和频率。
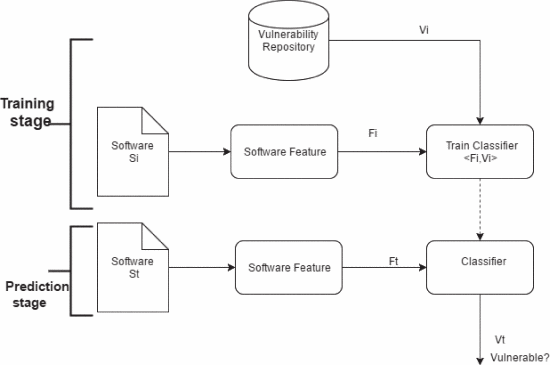
基于软件度量的预测模型
软件度量通过数值表示软件的特征。例如,软件的大小由代码行(LOC)或软件中定义的函数总数表示。在基于软件度量的软件度量预测模型中,这些软件度量被用作特征并被映射到相应软件组件的漏洞状态。许多软件度量标准是作为软件开发生命周期各个阶段的一部分创建的。因此,这些指标用于构建软件漏洞预测模型。
软件漏洞预测模型:
软件度量标准:

基于软件度量的文本挖掘预测模型
这是一种基于机器学习的方法,用于预测软件应用程序的哪些组件具有安全威胁。
在此方法中,完成源代码的文本分析。每个组件都表示为源代码中的一组术语,即令牌,它在源代码中的出现次数。这些令牌及其计数用于构建预测模型。例如,Android应用程序包含许多Java文件作为软件组件。每个java文件都转换为一个标记集合和文件中每个标记的计数。用于将源代码转换为标记的方法使用分隔符。分隔符中包含数学和逻辑运算符,空格,Java标点字符。
令牌转化:

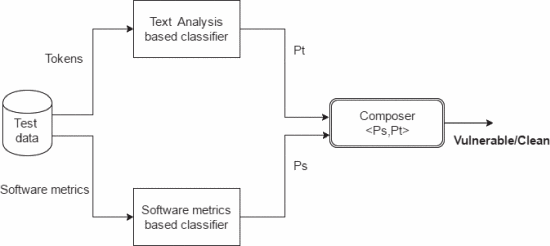
结合软件度量和文本挖掘方法预测漏洞文件的新方法
第一阶段六个基础分类器产生输出,在第二阶段由作曲家组合这些输出。存在不同的分类方案,针对不同的数据集和不同的方法给出不同的结果。因此,将这两种方法,软件度量和文本挖掘与不同的机器学习技术相结合。在这项工作中,作者为每种方法使用三个分类器,并使用组合器来组合这些分类器的输出。随机森林被用作作曲家。
简单组合预测模型:
Research of Industrial Control System Device Firmware Vulnerability Mining Technology Based on Taint Analysis
作者:Yi Li ; Xiaoman Liu ; Huirong Tian ; Cheng Luo
投稿:2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS)
年份:2018
主题:一种挖掘工业控制系统固件漏洞的新方法
这篇论文个人认为比较有实用性
针对固件漏洞挖掘研究和基于模糊测试的传统漏洞挖掘方法研究效率低下的问题,提出了一种挖掘工业控制系统固件漏洞的新方法。该方法基于污点分析技术,可以针对可能触发漏洞的变量构建测试用例,从而减少无效测试用例的数量,提高测试效率。实验结果表明,该方法可以减少约23%的测试用例,可以有效提高测试效率。
随着工业信息化的发展,越来越多的传统网络技术应用于工业控制系统。一方面,这改善了工业生产,另一方面,它在ICS之前引入了许多安全问题。虽然工业企业在Stuxnet事件和乌克兰电力系统袭击事件后普遍提高了对ICS安全保护的关注程度,但近年来,与ICS相关的安全事件仍然无休止地出现。一家名为Business Advantage的市场研究咨询公司去年与来自21个国家的359家公司一起对卡巴斯基实验室进行了采访,结果显示其中54%的公司在一年内至少在其ICS中发生过一次安全事故。在这些公司面临的安全威胁中。大多数这些威胁利用ICS软件或硬件中的漏洞来实现其攻击目的。因此,及时发现和修复ICS中的漏洞成为ICS安全保护的重要手段之一。而自2016年以来,一个重要的安全趋势是终端设备暴露的安全问题日益严重,已成为攻击者的重要推动力。控制大量终端设备以在目标系统上执行加密货币挖掘或DDoS攻击的情况已经暴露。因此,如何探索ICS中可能存在的漏洞,切断攻击者的潜在攻击路径,进而防止工业控制设备成为攻击者的工具,已成为研究的热点。
污点分析
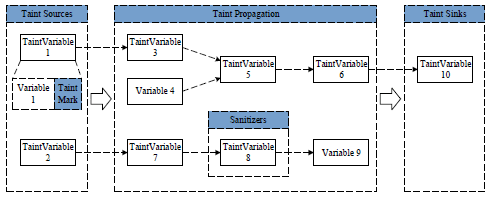
污点分析(也称为信息流跟踪技术)是一种实用的信息流分析技术,它通过在系统中标记敏感数据然后跟踪过程中标记数据的传播来检测系统安全问题[8]。
污点分析可以抽象为三元组(源,汇,消毒剂),其中,源是污点的来源,这意味着不受信任或机密的数据被指示到系统中。接收器是接收点,表示直接生成安全敏感操作(违反数据完整性)或私有数据泄漏到外部(这违反了数据机密性)。消毒剂是无害的过程,这意味着数据传输不再通过数据加密或去除危险来损害软件系统的信息安全。污点分析是分析程序中污点源引入的数据是否可以直接传输到汇点而不会进行无害处理。如果不是,则系统在信息流方面是安全的; 否则,表示系统存在安全问题,如隐私数据泄露或危险数据操作。
污点分析过程:
漏洞挖掘状态机中检测到的程序段中每个变量的状态转换图:
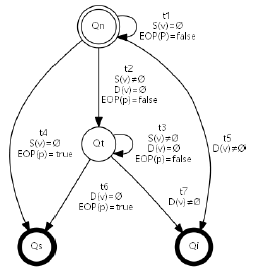
污点跟踪算法
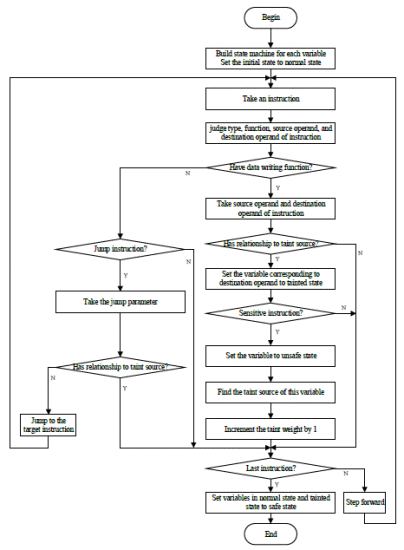
污点跟踪算法是循环过程。分析检测到的程序段的每个指令以确定它是否涉及污染变量的扩散以及它是否是敏感指令。详细步骤解释如下:
- 为检测到的程序段中的每个变量建立状态机,并将初始状态设置为正常状态。
- 从被检测程序段的第一条指令开始,分析当前运行位置的指令,取指令,判断其类型,指令功能,指令源操作数和指令目标操作数,为下一步判断做准备。然后转到步骤3。
- 判断该指令是否具有数据写入功能,或者是根据步骤2获得的指令功能和类型的跳转指令。如果不是,则前进一步,返回步骤2.如果该指令具有数据写入功能而不是跳转请执行步骤4.否则,请执行步骤5。
- 获取操作数,并判断目标操作数是否存在受污染数据的传播。也就是说,根据上述状态模型的定义判断目标操作数是否与受污染源相关。如果是,请将变量设置为污染状态,然后转到步骤6.否则,前进并返回步骤3。
- 如果指令是跳转指令,则判断跳转参数是否与受污染的数据有关。如果参数是从污染变量派生的,则前进一步然后转到步骤2.否则,跳转到目标指令并转到步骤2。
- 根据上述敏感指令的定义判断步骤4中的指令。如果是这样,请将与操作数关联的变量设置为不安全状态。同时,找到污点源并将相关字段的权重增加1.如果该指令是检测到的程序段的最后一条指令,则转到步骤7.否则,前进并转到步骤2。
- 将所有变量设置为正常状态和污染状态为安全状态。
污点跟踪算法过程:
在相同数量的漏洞下,不同plc固件挖掘所需的测试用例数量的比较:
作为近年来研究的新方向,工业控制系统的安全性受到广泛关注。ICS的安全事件时有发生,并且开放漏洞的数量不断增加。但最近工业控制系统漏洞挖掘研究工作主要集中在控制协议和控制软件上,对工业控制设备固件漏洞挖掘的关注较少,大多数现有方法是通过随机构建测试用例来实现的,这种方法较差。挖掘效率,因而业界迫切需要一种工业控制设备固件的挖掘方法。本文提出了一种工业控制设备固件漏洞挖掘方法。此方法使用污点分析方法过滤可能在检测到的程序段中易受攻击的变量,并针对这些变量构建测试用例,以减少无效测试用例的数量并提高测试效率。实验结果表明,该方法可以平均节省大约四分之一的测试用例,并且可以在挖掘相同数量的漏洞时显着提高漏洞挖掘的效率。在未来的工作中,可以进一步优化生成漏洞测试用例的方法,以提高漏洞挖掘的效率。实验结果表明,该方法可以平均节省大约四分之一的测试用例,并且可以在挖掘相同数量的漏洞时显着提高漏洞挖掘的效率。在未来的工作中,可以进一步优化生成漏洞测试用例的方法,以提高漏洞挖掘的效率。实验结果表明,该方法可以平均节省大约四分之一的测试用例,并且可以在挖掘相同数量的漏洞时显着提高漏洞挖掘的效率。在未来的工作中,可以进一步优化生成漏洞测试用例的方法,以提高漏洞挖掘的效率。
A Mining Approach to Obtain the Software VulnerabilityCharacteristics
作者:Xiang Li ; Jinfu Chen ; Zhechao Lin ; Lin Zhang ; Zibin Wang ; Minmin Zhou ; Wanggen Xie
投稿:2017 Fifth International Conference on Advanced Cloud and Big Data (CBD)
年份:2017
主题:一种分析和获取基于软件漏洞的数据挖掘技术的基本特征的漏洞挖掘算法
作者首先使用数据挖掘技术和常见漏洞数据库提取和预处理软件漏洞。作者使用通用漏洞和暴露(CVE)数据库,通用弱点枚举(CWE)数据库,国家漏洞数据库(NVD)数据集来评估所提出的技术。实证结果表明,所提出的漏洞挖掘算法在漏洞挖掘过程中有显着的改进。
一般漏洞挖掘框架

获得基本特征:一种新方法
- 涉及使用punct []函数从项目中删除标点符号和特殊字符(例如@ &%* /:?#。,!$)。
- 在这个阶段,删除了数据库中经常出现的所有停用词,例如(例如,此,,或,,am,it,on,at,how,with,that)。作者处理了空格,数字以及大小写,因为所有这些元素都不会影响漏洞挖掘过程的结果。
- 作者为三个漏洞数据库分配了术语权重,以确定软件漏洞文本指示符在数据库中出现的频率。
在针对每种情况应用加权方案(tfidj)之后,基于每个文本指示符在数据库中的频率为每个文本指示符分配统计相关性评分函数,并且将最高得分作为在挖掘阶段中使用的最终指标。计算的术语总数计算为搜索数和t项的比率。
软件漏洞特征的挖掘算法
在本研究中,作者提出了一种漏洞挖掘算法,利用CWE,CVE和NVD数据库中存在的软件漏洞信息挖掘并获取软件漏洞的本质特征。该研究结果表明,与手动方法相比,用于提取软件漏洞基本特征的漏洞挖掘算法有显着改进。作者分析的最重要发现是,作者观察到,在所有三个项目中,召回率约为70%,精确度约为60%。这表明漏洞挖掘算法在检测基本和非必要漏洞方面有显着改进。这意味着本研究采用的方法可以有效地应用于提取和获取软件漏洞的基本特征。虽然作者使用了三个以不同格式存储软件漏洞的漏洞数据库,但作者的方法没有考虑用于存储这些漏洞的其他功能。将来,作者计划通过添加其他功能扩展研究范围,并挖掘从各种数据库中提取的基本漏洞之间的关联。这意味着本研究采用的方法可以有效地应用于提取和获取软件漏洞的基本特征。虽然作者使用了三个以不同格式存储软件漏洞的漏洞数据库,但作者的方法没有考虑用于存储这些漏洞的其他功能。将来,作者计划通过添加其他功能扩展研究范围,并挖掘从各种数据库中提取的基本漏洞之间的关联。这意味着本研究采用的方法可以有效地应用于提取和获取软件漏洞的基本特征。虽然作者使用了三个以不同格式存储软件漏洞的漏洞数据库,但作者的方法没有考虑用于存储这些漏洞的其他功能。将来,作者计划通过添加其他功能扩展研究范围,并挖掘从各种数据库中提取的基本漏洞之间的关联。
Data mining for web vulnerability detection: A critical review
作者:Duha A. Al-Darras ; Ja'far Alqatawna
投稿:2017 8th International Conference on Information Technology (ICIT)
年份:2017
主题:本文分析了如何使用数据挖掘技术来提高漏洞检测的质量。
本首先讨论Web应用程序漏洞以及静态检测方法及其局限性。然后,本文探索数据挖掘技术及其改进漏洞检测的潜力,回顾和讨论了在文献中使用这些技术的结果。
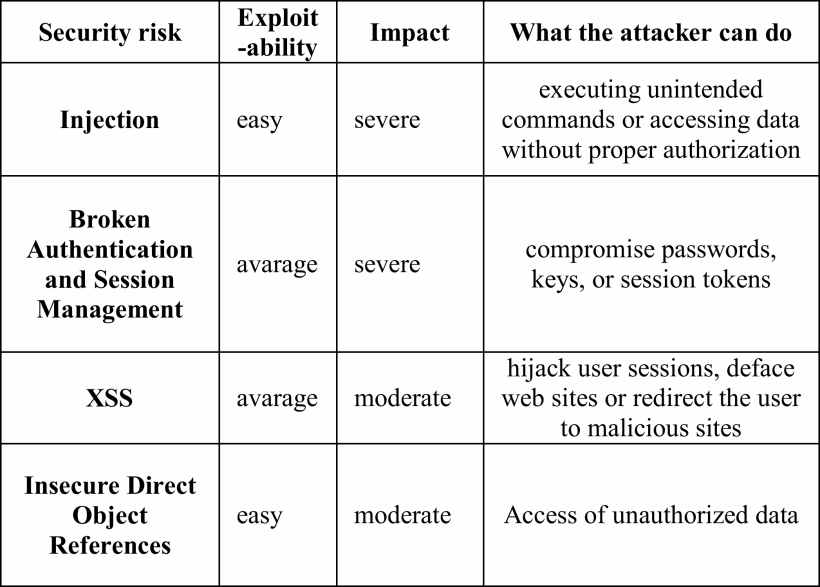
Web漏洞
赛门铁克公司2015年安全报告统计数据显示,78%的网站至少有一个漏洞,其中15%的漏洞是关键漏洞[1]。2016年White-Hat报告的统计数据显示,每个站点的平均漏洞数量为23个,其中13个是严重漏洞。此外,它表明漏洞可以在很长一段时间内保持开放状态。严重漏洞的平均年龄为300天[5]。这些结果表明Web应用程序仍包含许多漏洞.
数据挖掘与用于检测代码中的漏洞的模式匹配
最常用的漏洞检测方法之一是模式匹配。有两种类型可以检测注册的模式是漏洞,积极的安全模型和消极的安全模型。积极的安全模型注册了许多非易受攻击的Web代码模式,当新模式与任何已注册的模式不匹配时,它被归类为易受攻击的。相反,当新模式与任何已注册模式不匹配时,负安全模型会注册许多恶意Web代码模式,它被归类为非易受攻击。此模式仅限于预先注册的模式,这意味着它对恶意Web代码的更改不灵活。另一种方法使用数据挖掘算法来检测漏洞。该方法包含两个主要阶段:学习阶段和分类阶段。在学习阶段,提取特征并定义规则。在分类阶段,分类器根据特征向量将给定代码分类为易受攻击或不易受攻击。使用机器学习算法的一个优点是它可以利用更广泛的漏洞检测。
数据挖掘和静态分析
程序员经常使用静态分析技术来自动搜索和删除应用程序源代码中的漏洞。开发静态分析工具需要明确编码如何检测每个漏洞的知识,这是一个复杂的过程。
Machine Learning in Vulnerability Databases
作者:Zhechao Lin ; Xiang Li ; Xiaohui Kuang
投稿:2017 10th International Symposium on Computational Intelligence and Design (ISCID)
年份:2017
主题:机器学习在漏洞数据库中的应用
通过分析现有的开源漏洞数据库,本文作者提取相关属性并构建属性列表,然后利用机器学习技术挖掘属性列表,希望发现一些新颖,有趣,对研究者有价值的知识。本文作者仅在本文中的漏洞数据库中挖掘关联规则。通过这些关联规则,本文作者可以发现一些共同存在的漏洞属性,这可以进一步推断出漏洞的规律。
当前领域中众所周知的开源漏洞数据库是美国国家漏洞数据库(NVD),其中包含所有CVE信息。CVE是用于安全信息共享的关键字,可帮助用户在单独的漏洞数据库和漏洞评估工具中共享数据。每个CVE由CVE编号(即CVE的名称),一些常见漏洞评分系统(CVSS)度量标准和参数组成,其中包含有关漏洞类型,严重性等的信息。此外,NVD还包含Common Weakness Enumeration(CWE)。CWE将弱点划分为不同的类别,例如跨站点脚本或操作系统命令注入,CWE有超过1,000个不同的条目。
中国,有一个国家漏洞数据库:中国国家信息安全漏洞数据库(CNNVD)。CNNVD是中国信息技术安全评估中心的成员。旨在发现,传播和修复漏洞。CNNVD建立了一个全面的多层次数据收集渠道。它包含补丁,受影响的产品,安全事件和其他相关数据。
数据库的来源
在本文中,作者使用Common Weakness Enumeration(CWE)数据库[6]作为数据库的来源,CWE定义了软件设计和实现的共同弱点,并将弱点分类为类别。大约1000种弱点描述了从软件设计到实现的安全弱点。
与CVE类似,每个CWE都有一个唯一的ID,不同的CWE对应不同的ID。CVE还包含CWE ID,表明可以在CWE中找到CVE中大量漏洞的原因。从CWE的角度来看,这是由于CWE中的一个或多个弱点,它在CVE中形成了漏洞。因此,CWE的重要性是显而易见的。
出于不同的目的,CWE设计了两种观点:发展和研究。开发视图根据软件开发经常遇到的概念来组织弱点。研究视图是为了促进弱点研究而产生的,它包含弱点与脆弱性弱点的作用之间的相互依赖关系。以下是从CWE数据库中的弱点中选择的部分属性值
数据预处理
选择目标数据库后,挖掘工作无法立即启动,因为目标数据库的数据格式不适用于数据挖掘工具,因此需要将原始数据格式转换为适合挖掘工具的格式。此外,目标数据库包含大量数据,这不是我们所关心的,因此有必要消除数据库中的无关数据。最后,数据库中的一些数据不是标准化的,如果直接用于挖掘,很难获得高质量的结果,因此有必要对这些非标准数据进行标准化。简而言之,需要高质量的数据来获得高质量的采矿结果。本文中的数据预处理包括以下过程:
- 数据恢复:数据库可以从CWE网站[6]下载,数据格式为xml。
- 数据提取:获取CWE数据库信息后,分析弱点中包含的信息,并根据文件格式和编写规范提取所需的属性。
- 数据清理:某些弱点可能在结果数据库中缺少某些属性值,因此需要将缺省数据添加到缺少的属性值。另外,对于相同的属性值,不同的弱点可能有不同的表达式,在CWE中,最常见的是同一个词,一个开头是大写,另一个不是,所以我们需要修改类似的不一致数据。最后,CWE中存在属性值错误,例如应该用于描述“语言名称”的属性值,该属性值用于描述需要修改此类数据的“语言类”。
- 数据转换:这是数据格式的转换,因为数据挖掘工具有其特定的格式要求,因此有必要将原始xml格式转换为相应的数据格式。
- 数据缩减:包括降维和数据压缩。降维基于数据提取,并进一步删除不相关的属性。数据压缩是为了消除一些不必要的数据项。
构建特征空间
除了诸如“引入时间”和“适用平台”之类的结构化数据之外,还存在一些没有诸如“描述”之类的结构的信息。我们可以使用scikit-learn工具[8]的Countvectorizer模块来提取常用单词和n-gram。
n-gram是在文档中同时出现的字段元组。每个CWE描述可以形成文档,并且所有文档形成语料库。
每个CWE描述都可以进行矢量化,并且根据哪个描述包含n-gram,可以将其转换为一组特征事件,这是利用文档中的信息的最简单方法。更高级的方法是使用自然语言处理算法。
我们在本文中没有处理这部分非结构化信息,这是未来的工作。
实验结果
-
每个实验的过程基本相同,首先使用数据预处理工具CWE_exact提取所需的属性值,并将其转换为数据挖掘格式,然后在Weka中使用FP-growth算法,将CWE_exact生成的文件挖掘到获得关联规则。
使用FP-growth算法基于两个原因:FP-growth比Apriori快,而FP-growth消耗更少的内存。
-
根据不同弱点之间的层次关系,将所有弱点抽象为最高级别的11种类型,并在此级别的粒度下,探讨CWE类型与内部属性之间的关系。
“语言名称”和“引入时间”之间的关联规则:

“引入时间”和“后果范围”之间的关联规则:
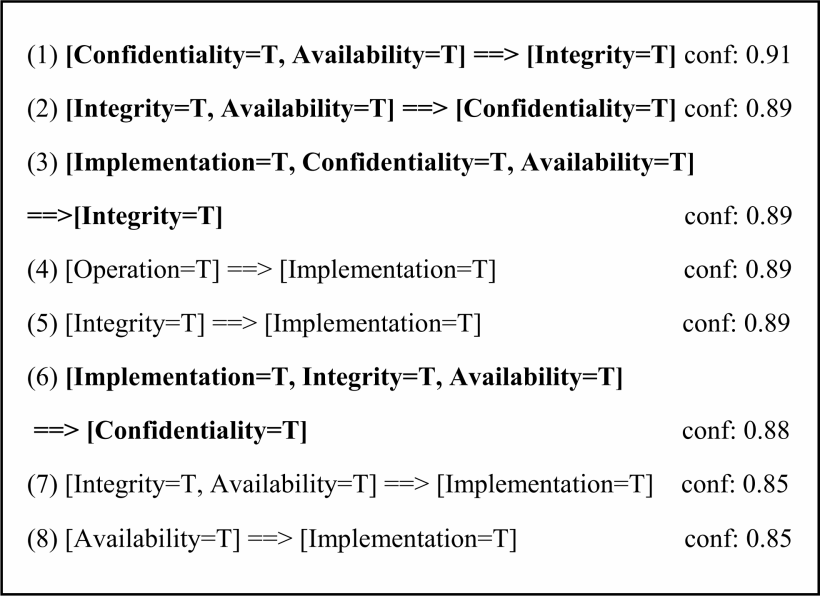
弱点类型与“引入时间”之间的关联规则:

弱点类型与“后果范围”之间的关联规则;

漏洞挖掘学习总结
在之前查阅资料学习时,看到了一个很有意思的形容:
从某个角度来讲,可以将漏洞挖掘工作比作玩迷宫游戏,不同的是,这个迷宫与平时所见的游戏中的迷宫略有不同:
1. 无法立即看到它整体的外观
2. 随着漏洞挖掘工作的深入,这个迷宫的形状逐渐扩大
3. 攻击者将会拥有多个起点及终点,但是无法确定这些点具体在哪里
4. 最终这个迷宫可能永远也无法100%的完整,但是却能够弄清楚A点至B点的一条完整路径
具体一点的描述,可以将漏洞挖掘工作归结为三个步骤:
1. 枚举程序入口点(例如:与程序交互的接口)
2. 思考可能出现的不安全状态(即漏洞)
3. 设法使用识别的入口点到达不安全状态
即是说,在这个过程中,迷宫是研究的应用程序,地图是堆程序的理解程度,起点是的入口点(交互接口),终点为程序的不安全状态。
所谓入口点,既可以是UI界面上直观可见的交互接口,也可以是非常模糊与透明的交互接口(例如IPC),以下是部分安全研究员较为感兴趣的关注点:
1. 应用程序中比较古老的代码段,并且这一部分随着时间的推移并没有太大的变化。
2. 应用程序中用于连接由不同开发团队或者开发者开发的程序模块的接口部分
3. 应用程序中那些调试和测试的部分代码,这部分代码本应在形成Release版本时去除,但由于某些原因不小心遗留在程序中。
4. C-S模式(带客户端和服务端)的应用中客户端及服务端调用API的差异部分(例如网页表单中的hide属性字段)
5. 不受终端用户直接影响的内部请求(如IPC)
认为从攻击面上来划分可以讲漏洞分为两大类,通用漏洞(General)和上下文漏洞(contextual)。通用型漏洞是指在对应用的业务逻辑不是非常熟悉的情况下能够找出的漏洞,例如一些RCE(远程代码执行)、SQLi(sql注入)、XSS(跨站)等。上下文漏洞是指需要在对应用的业务逻辑、认证方式等非常熟悉的情况下才能找到的漏洞,例如权限绕过等。
在漏洞挖掘的过程中,首先会根据经验优先考虑研究测试那些
首先假设攻击者的目标web应用是一个单页面应用(single-page-application SPA),攻击者已经获得合法验证去访问这个应用,但是攻击者没有任何关于服务端的源代码或者二进制文件。在这种情况下,当攻击者枚举入口点时,可以通过探寻该应用的不同功能来进一步了解其业务逻辑及功能,可以通过抓包分析看HTTP请求内容,也可以分析客户端的网页代码获取需要提交表单的列表,但是最终的限制还是攻击者无法具体知悉客户端和服务端调用的API之间的区别,不过通过以上方法,攻击者可以找到一些入口点,
接着就是操作这些入口点,以试图达到攻击者预期的不安全状态。由于漏洞的形态很多,攻击者通常需要构建一个适用于该测试应用程序的业务功能漏洞的测试集,以求达到最高效的寻找漏洞。如果不那样做的话,攻击者就将会在一些无用的测试集上花费大量时间,并且看不到任何效果(举个例子,当后台的数据库为Postgresql时,攻击者用xp_cmdshell去测试,测试再多次都无济于事)。所以在构造测试集时,需对应用程序的逻辑有较深的理解。
参考资料
- 《模糊测试——强制发掘安全漏洞的利器》
- Research of Industrial Control System Device Firmware Vulnerability Mining Technology Based on Taint Analysis
- A Mining Approach to Obtain the Software VulnerabilityCharacteristics
- Data mining for web vulnerability detection: A critical review
- An integration testing framework and evaluation metric for vulnerability mining methods
- A study on software vulnerability prediction model
- Machine Learning in Vulnerability Databases

 浙公网安备 33010602011771号
浙公网安备 33010602011771号