20189221 2018-2019-2 《密码与安全新技术专题》第四周作业
20189221 2018-2019-2 《密码与安全新技术专题》第四周作业
课程:《密码与安全新技术专题》
班级: 201892
学号:20189221
上课教师:谢四江
上课日期:2019年4月10日
必修/选修: 选修
1.本次讲座的学习总结
讲座主题:信息隐藏
信息隐藏是将消息隐蔽的藏于载体中,实现隐蔽通信,内容认证或内容保护等。
- 信息隐藏基本概念
- 隐写/隐写分析的基础知识、研究进展
- CNNs在该领域的应用
信息隐藏技术
- 鲁棒水印 RobustWatermaking
- 可视密码 Visual Cryptography
- 隐写 Steganography
隐写
- LSB嵌入
- 矩阵嵌入
- 自适应隐写
- 隐写分析
- 高维特征
- 隐写选择信道
隐写术是关于信息隐藏,即不让计划的接收者之外的任何人知道信息的传递事件(而不只是信息的内容)的一门技巧与科学。隐写术英文作“Steganography”,来源于约翰尼斯·特里特米乌斯一本看上去是有关黑魔法,实际上是讲密码学与隐写术的一本书Steganographia中。此书书名来源于希腊语,意为“隐秘书写”。
有两种办法可用来隐藏明文信息。隐写术,它可以隐藏信息的存在;而密码学则是通过对文本信息的不同转换而实现信息的对外不可读。
在数字隐写术中,人们通常会使用某种程序将消息或文件嵌入到一个载体文件中,然后把这个载体文件直接传给接收者或者发布到网站上供接收者下载。接收者获取载体文件后,再用同样的程序把隐藏的消息或文件恢复。有些隐藏程序会使用密码来保护隐藏消息,还有些程序隐藏程序用密码保护隐藏消息,有些还加入了密码隐藏保护。
隐写方法:
最常用的隐写修改方法是修改文中一个或者多个字节的最低有效位,基本上就是把0改成1,或者把1改成0。这样修改后生成的图像就有渲染效果,把这些比特位重组还原后才可以看到原始的隐藏消息,而人们仅靠视觉或听觉是不可能发现这些改动的。
例如,LSB(最低有效位)修改法:利用24位调色板。调色板中有红、绿、蓝三原色组成,一个原色由8位二进制位表示,即265个色调,三原色混合可以指定24位图像中的每个像素点,如题3.5。而这个是我们修改每个字节分组的最低位,图片在显示时的区别,肉眼是无法辨别的,进而可以达到隐藏数据的目的。如图3.6和3.7,修改后的每八个字节组的最后一位可以构成一个字节,表示一个ASCII码,这是隐藏的数据。类似的原理还可应用在协议通信隐藏数据、文档信息隐藏等地方。
隐写术的优缺点:
需要许多额外的付出来隐藏相对较少的信息。
尽管采用一些诸如上述方案也许很有效;但是一旦被破解,整个方案就毫无价值。(改进:具体的加入方法由秘钥决定;先加密再隐写)
隐写术适合:通信双方宁愿内容丢失,也不愿意它们进行秘密通信的事物被人发现。加密标志信息也是重要和秘密的,通过它可以找出想进行消息隐藏的发送方或接收方。
隐写分析:
数字隐写分析就是通过隐写技术或软件对隐藏的数据进行检测和取证的过程,可能的话,还会提取出被隐藏的载荷。如果被隐藏的载荷是加过密的,那么隐写分析就要对其进行破解。
值得注意的是,使用工具进行隐藏的载体文件都会留下一些与软件有关的特征,我们可以将这些特征提取出来并构成特征库,进而可以成文检测隐写信息的一个突破口。
这里主要会采用以下两个手段:
- 异常分析:异常分析会用到检测相似文件的对比技术,如果没有文件可以用于对照,还会采用一些分析技术来发现文件的其他异常特征。
- 隐写分析工具:这些工具具有相同的工作原理:首先检测文件的某些信息,根据判断其中包含隐藏内容的,就标记为可疑文件。然后,将可疑文件寄存起来以便后续进行深度分析;第二步分析环节可以是半自动半手工的,大多数先进的工具都允许人工查看数据进而分析发现异常特征。
免费软件:StegSpy,Stegdetect。
2.学习中遇到的问题及解决
问题1:深入学习几种隐写技术
问题1解决:JPEG图像格式的Jphide隐写、LSB隐写
Jphide隐写
JPEG图像
JPEG文件交换格式的JPEG图片的图像开始标记SOI(Start of Image)和应用程序保留标记APP0(Application 0),JPEG文件交换格式的JPEG图片开始前2个字节是图像开始标记为0xFFD8,之后2个字节接着便是应用程序保留标记为0xFFE0,应用程序保留标记APP0包含9个具体字段,这里介绍前三个字段,第一个字段是数据长度占2个字节,表示包括本字段但不包括标记代码的总长度,这里为10个字节,第二个字段是标识符占5个字节0x4A46494600表示“JFIF0”字符串,第三个字段是版本号占2个字节,这里是0X0101,表示JFIF的版本号为1.1,但也可能为其它数值,从而代表了其它版本号。

隐写原理
Jphide是基于最低有效位LSB的JPEG格式图像隐写算法,使用JPEG图像作为载体是因为相比其他图像格式更不容易发现隐藏信息,因为JPEG图像在DCT变换域上进行隐藏比空间域隐藏更难检测,并且鲁棒性更强,同时Blowfish算法有较强的抗统计检测能力。
由于JPEG图像格式使用离散余弦变换(Discrete Cosine Transform,DCT)函数来压缩图像,而这个图像压缩方法的核心是:通过识别每个8×8像素块中相邻像素中的重复像素来减少显示图像所需的位数,并使用近似估算法降低其冗余度。因此,我们可以把DCT看作一个用于执行压缩的近似计算方法。因为丢失了部分数据,所以DCT是一种有损压缩(Loss Compression)技术,但一般不会影响图像的视觉效果。
隐写过程
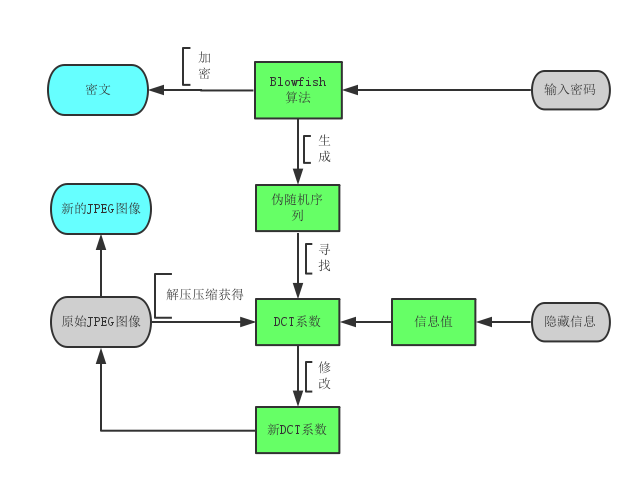
Jphide隐写过程大致为:先解压压缩JPEG图像,得到DCT系数;然后对隐藏信息用户给定的密码进行Blowfish加密;再利用Blowfish算法生成伪随机序列,并据此找到需要改变的DCT系数,将其末位变为需要隐藏的信息的值。最后把DCT系数重新压回成JPEG图片,下面是个人对隐写过程理解画出的大致流程图。
隐写实现
- Stegdetect
实现JPEG图像Jphide隐写算法工具有多个,比如由Neils Provos开发通过统计分析技术评估JPEG文件的DCT频率系数的隐写工具Stegdetect,它可以检测到通过JSteg、JPHide、OutGuess、Invisible Secrets、F5、appendX和Camouflage等这些隐写工具隐藏的信息,并且还具有基于字典暴力破解密码方法提取通过Jphide、outguess和jsteg-shell方式嵌入的隐藏信息。
Stegdetect的主要选项:
-q 仅显示可能包含隐藏内容的图像。
-n 启用检查JPEG文件头功能,以降低误报率。如果启用,所有带有批注区域的文件将被视为没有被嵌入信息。如果JPEG文件的JFIF标识符中的版本号不是1.1,则禁用OutGuess检测。
-s 修改检测算法的敏感度,该值的默认值为1。检测结果的匹配度与检测算法的敏感度成正比,算法敏感度的值越大,检测出的可疑文件包含敏感信息的可能性越大。
-d 打印带行号的调试信息。
-t 设置要检测哪些隐写工具(默认检测jopi),可设置的选项如下:
j 检测图像中的信息是否是用jsteg嵌入的。
o 检测图像中的信息是否是用outguess嵌入的。
p 检测图像中的信息是否是用jphide嵌入的。
i 检测图像中的信息是否是用invisible secrets嵌入的。
-V 显示软件版本号。
如果检测结果显示该文件可能包含隐藏信息,那么Stegdetect会在检测结果后面使用1~3颗星来标识
隐藏信息存在的可能性大小,3颗星表示隐藏信息存在的可能性最大。
- JPHS
另一款JPEG图像的信息隐藏软件JPHS,它是由Allan Latham开发设计实现在Windows和Linux系统平台针对有损压缩JPEG文件进行信息加密隐藏和探测提取的工具。软件里面主要包含了两个程序JPHIDE和JPSEEK, JPHIDE程序主要是实现将信息文件加密隐藏到JPEG图像功能,而JPSEEK程序主要实现从用JPHIDE程序加密隐藏得到的JPEG图像探测提取信息文件,Windows版本的JPHS里的JPHSWIN程序具有图形化操作界面且具备JPHIDE和JPSEEK的功能。Windows可下载JPHS-05 for Windows,同时也提供下载Linux版本。
LSB隐写
LSB隐写是最基础、最简单的隐写方法,具有容量大、嵌入速度快、对载体图像质量影响小的特点。
LSB的大意就是最低比特位隐写。我们将深度为8的BMP图像,分为8个二值平面(位平面),我们将待嵌入的信息(info)直接写到最低的位平面上。换句话说,如果秘密信息与最低比特位相同,则不改动;如果秘密信息与最低比特位不同,则使用秘密信息值代替最低比特位。
python代码实现:
from PIL import Image
import math
class LSB:
def __init__(self):
self.im=None
def load_bmp(self,bmp_file):
self.im=Image.open(bmp_file)
self.w,self.h=self.im.size
self.available_info_len=self.w*self.h # 不是绝对可靠的
print ("Load>> 可嵌入",self.available_info_len,"bits的信息")
def write(self,info):
"""先嵌入信息的长度,然后嵌入信息"""
info=self._set_info_len(info)
info_len=len(info)
info_index=0
im_index=0
while True:
if info_index>=info_len:
break
data=info[info_index]
x,y=self._get_xy(im_index)
self._write(x,y,data)
info_index+=1
im_index+=1
def save(self,filename):
self.im.save(filename)
def read(self):
"""先读出信息的长度,然后读出信息"""
_len,im_index=self._get_info_len()
info=[]
for i in range(im_index,im_index+_len):
x,y=self._get_xy(i)
data=self._read(x,y)
info.append(data)
return info
#===============================================================#
def _get_xy(self,l):
return l%self.w,int(l/self.w)
def _set_info_len(self,info):
l=int(math.log(self.available_info_len,2))+1
info_len=[0]*l
_len=len(info)
info_len[-len(bin(_len))+2:]=[int(i) for i in bin(_len)[2:]]
return info_len+info
def _get_info_len(self):
l=int(math.log(self.w*self.h,2))+1
len_list=[]
for i in range(l):
x,y=self._get_xy(i)
_d=self._read(x,y)
len_list.append(str(_d))
_len=''.join(len_list)
_len=int(_len,2)
return _len,l
def _write(self,x,y,data):
origin=self.im.getpixel((x,y))
lower_bit=origin%2
if lower_bit==data:
pass
elif (lower_bit,data) == (0,1):
self.im.putpixel((x,y),origin+1)
elif (lower_bit,data) == (1,0):
self.im.putpixel((x,y),origin-1)
def _read(self,x,y):
data=self.im.getpixel((x,y))
return data%2
if __name__=="__main__":
lsb=LSB()
# 写
lsb.load_bmp('test.bmp')
info1=[0,1,0,1,1,0,1,0]
lsb.write(info1)
lsb.save('lsb.bmp')
# 读
lsb.load_bmp('lsb.bmp')
info2=lsb.read()
print (info2)
问题2:隐写术的应用
问题2解决:Powload及压缩包类隐写
Powload
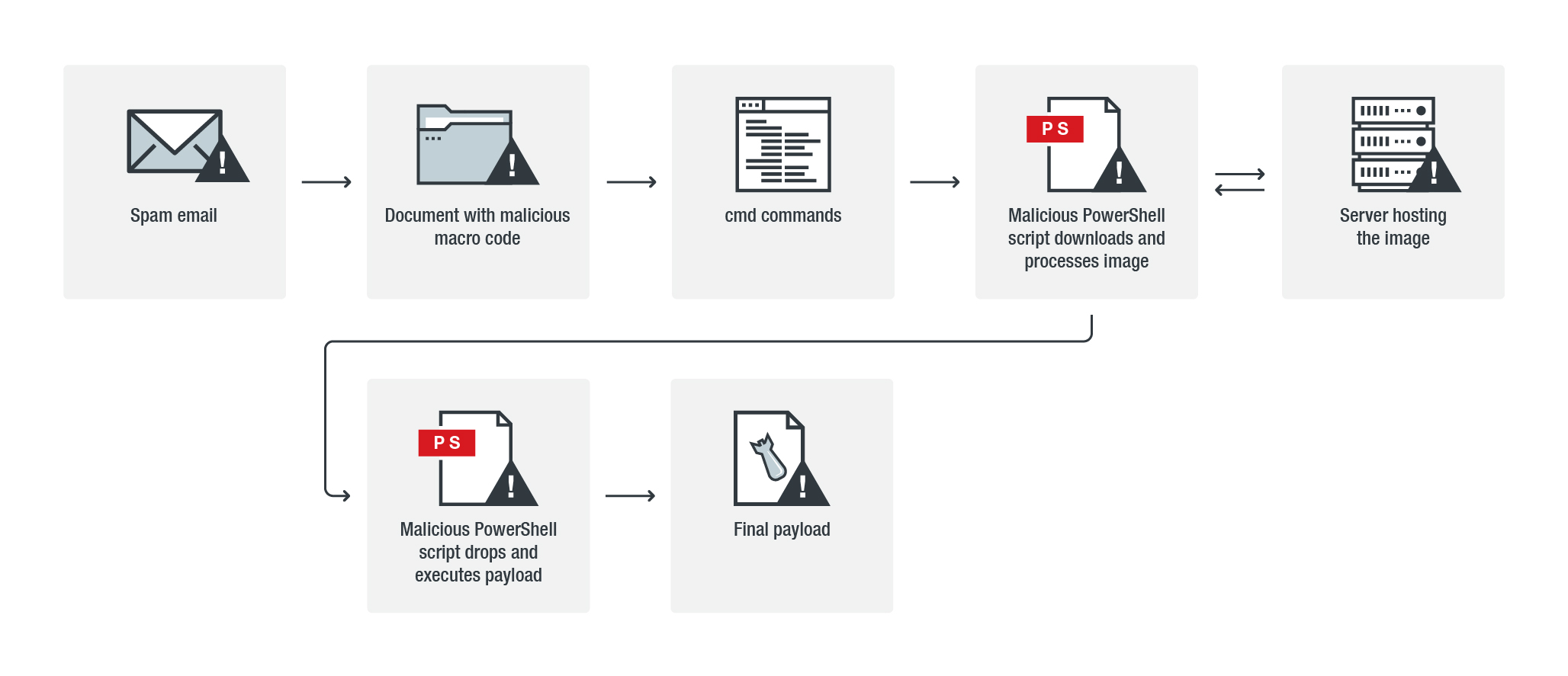
Powload是通过垃圾邮件发送的恶意软件,2018年上半年宏观恶意软件的上升是由Powload引起的,利用各种技术提供有效载荷,例如信息窃取Emotet,Bebloh和Ursnif。虽然它使用垃圾邮件作为分发方法可能是不变的,但它采用了不同的方式来提供有效载荷,从绕过文件预览模式等缓解措施到使用无文件技术和劫持电子邮件帐户。
使用隐写术
在图像中隐藏代码,黑客组织使用隐写技术来检索他们的后门。漏洞利用工具包使用这种方式来隐藏恶意广告流量,而其他威胁使用这种方式来隐藏其命令和控制(C&C)通信。
在Powload的案例中,使用隐写术来检索包含恶意代码的图像。基于趋势科技分析的Powload变体的代码提取案例程序,Powload滥用公开可用的脚本(Invoke-PSImage)来创建包含其恶意代码的图像。
垃圾邮件中的附件具有嵌入在文档中的恶意宏代码,该代码执行PowerShell脚本,该脚本下载在线托管的图像。然后处理下载的图像以获取隐藏在图像内的代码。


压缩包类隐写
压缩包是我们日常使用当中经常接触的,常见的格式: .rar .zip .7z
压缩包是可以加密的我们都知道,关于怎么解密有几种方法:
-
爆力破解,俗称爆破,使用对应的暴力破解软件,通过软件的解密算法实现,有时候CTF会出这类的题,根据加密的复杂程度,破解出来的所需要的时间是不一样的。
-
伪加密:通过修改压缩包的16进制文件中的数据,使压缩包显示有密码(其实是没有加密的,这时候爆破一万年也出不来啊_(:з)∠)_ )
1.可以使用使用ZipCenOp.jar(需要java环境),在cmd中使用(进入目标目录下)
命令:java -jar ZipCenOp.jar r xxx.zip
2.使用winRAR的修复(可能不好使)
3.一格zip文件有三个部分组成:压缩源文件数据区+压缩源文件目录区+压缩源文件目录结束标志
这是三个头标记,主要看第二个
压缩源文件数据区:50 4B 03 04:这是头文件标记
压缩源文件目录区:
50 4B 01 02:目录中文件文件头标记
3F 00:压缩使用的 pkware 版本
14 00:解压文件所需 pkware 版本
00 00:全局方式位标记(有无加密,这个更改这里进行伪加密,改为09 00打开就会提示有密码了) -
明文攻击 (软件Advanced Zip Password Recovery)所谓明文攻击就是已经通过其他手段知道zip加密文件中的某些内容,比如在某些网站上发现它的readme.txt文件,或者其他文件,这时就可以尝试破解了
3.本次讲座的学习感悟、思考等
夏超老师在讲座的最后给了我们四点建议:
- 看好论文 (顶会)
- 学好英语(写作、听说)
- 练好编程(工作、科研、GitHub)
- 放好心态(运气)
去年9月为期一周的入学教育中,基本上每个老师都对我们提出了类似的要求,研一即将结束,对这些建议的感受又多了几分。
归根结底,我即将成为一名IT从业者,即使是成为公务员,也一样是技术型岗位,学术能力及项目能力是基础能力也是选择的底气。在近一周对自己的反思中,惊觉自己之前将路越走越窄,失了许多平常心与选择自由。
夏老师的这几点建议,确是肺腑之言,更多的是以研究生师兄的身份给我们这些后来者提出的建议。
我将无我,奋斗终身。
4.隐写技术及隐写分析的研究现状
因为对隐写技术不够了解,所以阅读的论文集中于夏老师上课介绍的行业大牛Jessica Fridrich
Jessica Fridrich是宾厄姆顿大学电子与计算机工程系的教授,专门研究数字水印和取证。[2] [3] [1]她于1987年获得布拉格捷克技术大学应用数学硕士学位,1995年获得宾厄姆顿大学系统科学博士学位。[2]
杰西卡弗里德里希杰出教授
纽约州立大学宾汉姆顿
*电气与计算机工程系T. J. Watson应用科学与工程学院宾厄姆顿,纽约州13902-6000 **
电话:(607)777-6177
传真:(607)777-4464
网址:http://www.ws.binghamton .edu / fridrich
 期刊和会议出版物 期刊和会议出版物 |
|---|
| 个人简历 |
| 研究代码 |
| 当前和过去的研究项目 |
| 媒体 |
Deep Residual Network for Steganalysis of Digital Images
作者:Mehdi Boroumand ; Mo Chen ; Jessica Fridrich
投稿:IEEE Transactions on Information Forensics and Security (Volume: 14 , Issue: 5 , May 2019 )
年份:24 September 2018
主题:SRNet用于图像隐写分析
构建为深度卷积神经网络的隐写检测器已经确立了优于先前检测范式 - 基于富媒体模型的分类器。然而,现有的网络体系结构仍然包含手工设计的元素,例如固定或约束卷积核,内核的启发式初始化,模拟丰富模型中截断的阈值线性单元,特征映射的量化以及JPEG阶段的感知。在这项工作中,作者描述了一种深度剩余架构,旨在最大限度地减少启发式和外部强制元素的使用,因为它为空间域和JPEG隐写术提供了最先进的检测精度。所提出的架构的关键部分是探测器的显着扩展的前部,其“计算噪声残余”,其中已经禁用合并以防止对隐秘信号的抑制。大量实验表明,该网络的卓越性能得到了显着改善,尤其是在JPEG领域。通过将选择信道提供为第二信道,观察到进一步的性能提升。
一个干净的端到端设计,可用于更广泛的应用,并且可以很好地用于空间和JPEG域中的隐写分析。作者让自己受到深度学习的最新进展以及相当一般的原则和见解的指导,以最大限度地减少外部强制约束或启发式的使用。初始化为SRM滤波器或DCT基站的固定或约束的预处理内核或内核实际上可能对整体网络性能有害,这取决于隐秘信号的特性。高通滤波器,例如流行的KV滤波器,抑制由JPEG隐写术引入的大部分隐秘信号,因为嵌入修改应用于量化DCT系数。作者在第一卷积层中引入了额外的固定滤波器,以改进JPEG隐写术的检测。然而,理想情况下,最好的过滤器也应该被学习而不是强制执行,因为手工设计的过滤器或非随机内核初始化不太可能是所选架构的最佳选择。
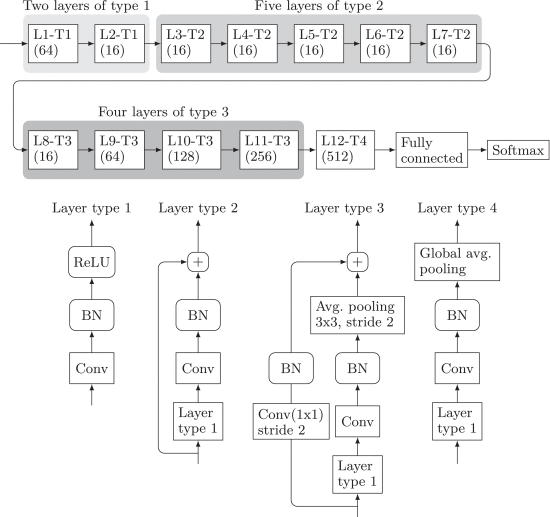
整体设计由四种不同类型的层组成,其中两层涉及残留捷径,以改善收敛性并帮助学习深层网络上层的参数,这通常是最难学的。在功能上,网络由三个串联连接的段组成 - 前段,其作用是学习有效的“噪声残差”,中间段使特征图紧凑,最后一段是简单的线性分类器。前段由七层组成,其中汇集已被禁用以防止由于在平均合并期间对特征图中的相邻样本求平均而抑制隐秘信号。由于平均合并是一个低通滤波器,它通过平均相邻的嵌入变化来增强内容并抑制类似噪声的隐秘信号。虽然这在用于分类内容的典型计算机视觉应用中是期望的,但是对于隐写分析是有害的,其中感兴趣的信号是隐秘噪声而“噪声”是图像内容。在这种洞察力的指导下,SRNet直到第8层才使用汇集,以避免降低隐秘信号的能量,并允许其针对各种类型的选择信道和隐写嵌入变化优化噪声残差提取过程。
SRNet中的所有过滤器都是通过端到端的培训过程随机初始化和学习的。这允许网络适应更多种类的隐秘信号,因为嵌入变化之间的极性和依赖性在不同的隐写方法尤其是域之间显着变化。嵌入通过最小化加性失真的空间域嵌入方法引入的修改.
-
1)激活: 除了ReLU,作者还尝试了TanH激活,泄漏的ReLU,ELU [11]和SELU [36],但它们没有带来任何性能提升。为避免额外的复杂性并以简单性为指导,作者为网络中的所有激活功能选择了ReLU。
请注意,在快捷方式连接后,类型2和3的图层不使用ReLU。虽然原始残留网络[26],[27]在添加快捷连接后确实包含了ReLU,但删除了这些激活后,作者观察到检测精度高达1%的小增益。
-
2)剩余快捷方式: 为了评估SRNet中快捷连接的重要性,作者将它们从类型2和3的层中移除,并观察了检测准确度的变化。例如,对于0.1和0.2 bpp的HILL,分类精度的损失约为0.5%,对于J-UNIWARD,0.4bpzzac,质量因子95,损失为1.5%。虽然这些情况下的性能仍然具有竞争力,但检测能力的损失随着类别可分离性的降低而增加,例如,对于小有效载荷和较大的JPEG质量。
-
3)密集连接和开始: 引入了深度学习中的密集连接,其目标与残留层类似 - 有助于梯度传播和收敛,特征重用,以及减少要学习的参数数量[32]。作者调查了SRNet第二部分中引入的密集连接的影响 - 未解密的第3-7层。在嵌入算法HILL和S-UNIWARD为0.4 bpp的实验中,具有密集连接的SRNet没有像具有残余连接的SRNet那样提供统计上显着更好的结果(统计显着性是基于检测到的快照的检测精度的统计分布来评估的对于最终的探测器)。但是,密集连接可能比SRNet对更深层的体系结构产生更大的影响。
“开始”背后的主要思想是每个层连接不同大小的滤波器的输出,这使人联想到融合图像处理中的多分辨率表示[51]。SRNet中的类型3层(参见图1)总结了有效的输出[ 数学处理错误] 在主分支中过滤(就感受野而言)和a [ 数学处理错误] 过滤器(快捷方式分支)。作者为此图层类型添加了一个额外的分支[ 数学处理错误] 过滤器后跟批量标准化。这需要架构中的其他更改以使修改后的SRNet适合GPU内存 - 作者将类型3层中的要素图数量减少到一半。以这种方式修改的SRNet在HILL和S-UNIWARD上测得的检测精度略差(0.5-1%),测试值为0.4 bpp。由于GPU内存有限,对SRNet内的初始模块的正确研究需要进行全面的研究,这超出了本文的范围。
-
4)未组合的图层: 作者现在评论未聚合层的数量及其对检测的影响。将数量从7减少到6或5,同时保持架构的其余部分不变会导致精度的小幅度逐渐降低。例如,对于0.4-bpnzac的J-UNIWARD(每非零AC DCT系数的比特)和JPEG质量75,检测错误[ 数学处理错误] 当未散化层的数量从7变为5和4时,从0.0670增加到0.0701和0.0748。随着有效载荷的减少,这种损失 此外,作者观察到这种损失通常在空间域中较小而在JPEG域中较大。在两个域中的测试算法中,检测精度趋向于在5-6个未计算的层处平稳。作者在作者提出的设计中选择了7个,以避免对更多样化的封面和隐秘来源的潜在检测丢失。
为了评估在1-7层中禁用池的重要性,作者进行了其他实验,其中在第7,6,5和4层逐步启用了池。请注意,启用多于四层的池将需要从中删除层第3组因为输出图层之前的要素图的大小减小了 [ 数学处理错误] 至 [ 数学处理错误] ,最终 [ 数学处理错误] 在四层中启用池时。
对0.4bpp的HILL和0.4bpzzac的J-UNIWARD进行实验以覆盖两个嵌入结构域。通过在第7层中启用平均池,从第7层开始,HILL的检测误差从0.1414(使用原始SRNet)迅速增加到0.1528,0.1823,0.2202和0.3697。对于J-UNIWARD,检测误差从0.0670增加到0.0755,0.0886,0.1263和0.1710。
-
5)过滤器数量: 第一层中的滤波器数量的影响在JPEG域中比在空间域中具有更大的影响。虽然检测错误,[ 数学处理错误] ,对于0.4 bpp的HILL,在第一层仅使用32和16个滤波器而不是64个(对于64,32和16个滤波器为0.1414,0.1432和0.1438)时,可忽略不计,J-UNIWARD为0.1 bpzzac,JPEG质量为75 ,将过滤器的数量从64减少到32导致增加 [ 数学处理错误] 大约1%。增加超过64的过滤器数量似乎不会导致检测方面的任何改进。
-
6)优化器: 最后,作者尝试了几个优化器,包括AdaDelta [66],Adam [35],Adamax [35]和一个简单的随机梯度下降[23,Ch。8.3.1,第286-288页]。最后,作者选择了Adamax,因为它提供了最可靠和最快速的融合。
![]()
Applications of Explicit Non-Linear Feature Maps in Steganalysis
作者:Mehdi Boroumand ; Jessica Fridrich
投稿:IEEE Transactions on Information Forensics and Security (Volume: 13 , Issue: 4 , April 2018 )
年份: 25 October 2017
主题:内容自适应图像隐写检测器
本论文描述了一种通过在训练低复杂度分类器/回归器之前转换特征来提高检测器性能的简单方法。该方法借鉴了文献中提出的近似半正定核的近似进展。该映射源自对称的Ali-Silvey距离(核)并使用Nyström近似估计。该方法通过分别为每个子模型学习变换来应用于丰富模型,以便保持较低的计算复杂度。需要一小组固定的覆盖特征来训练变换,这仅取决于少数覆盖特征而不依赖于隐写方案或嵌入的有效载荷。
与集合分类器相结合,对于具有用于灰度图像的选择通道感知maxSRMd2特征的二元分类器以及用于彩色图像的隐写分析的Spatio-Color Rich模型,观察到2-4%的检测精度的一致增益。对于定量检测器(有效载荷回归器),以MSE估计测量的有效载荷大小估计的统计分布的减少的增益在线性回归器的范围为18-28%,对于回归树为8-17%。
所提出的方法通过简单地保留较少的变换维度,自然有助于无监督降维。特别地,可以使富描述符紧凑10倍而不会丢失原始(未变换的)特征向量的检测性能。对于定量检测器,可以将特征压缩60%,同时进一步降低有效载荷估计的统计分布。这种降维可能对无监督的通用隐写分析探测器有用。
四种隐写方案的线性回归和回归树的平均绝对和均方误差,具有SRMQ1,其平方根版本,以及在BOSSbase上使用指数Hellinger内核进行转换后

Practical strategies for content-adaptive batch steganography and pooled steganalysis
作者:Rémi Cogranne ; Vahid Sedighi ; Jessica Fridrich
投稿:2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
年份: 19 June 2017
主题:内容自适应隐写术在图像上分配有效载荷
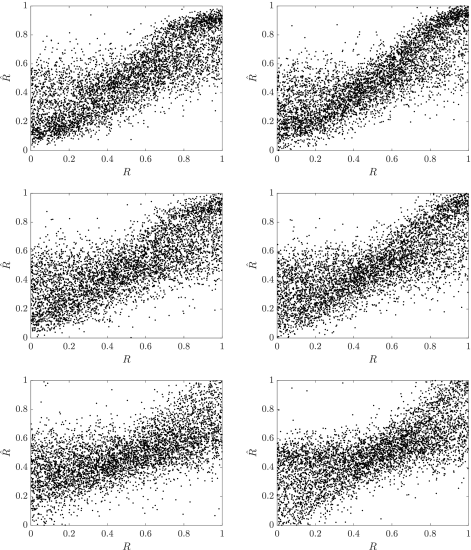
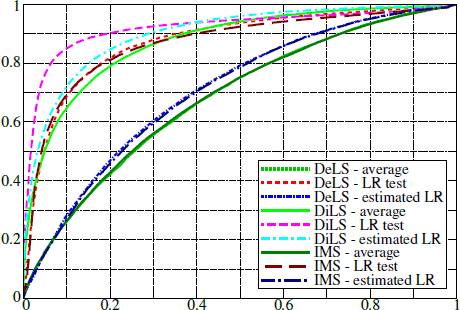
论文研究了内容自适应批量隐写和汇集隐写分析的问题,这是一个无所不知的Warden,意识到有效载荷传播策略,并配备了单一图像检测器,作为封面和隐秘源之间的分类器。通过对单图像检测器的输出采用统计模型,我们推导出最优合并函数作为匹配滤波器形式的似然比,并且其近似值在实践中可实现。我们还考虑了几种可以在实践中有效实施并进行测试的批量策略,以及最先进的隐写术的汇集策略,为隐写术的实践者以及隐写者绘制了许多有趣的结论
使用ROC曲线评估S-UNIWARD的批策略和汇集方法 [R¯¯¯¯= 0.2 BPP:
三种提议的批次策略中基于BOSS的图像的有效载荷大小的经验分布:

Steganography with two JPEGs of the same scene
作者:Tomáš Denemark ; Jessica Fridrich
投稿:2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
年份:5-9 March 2017
主题:同一场景的两个JPEG图像形式的替代形式的边信
在本文中,作者使用JPEG格式采集的多个图像,因为我们期望量化DCT系数对于采集期间的小缺陷自然更加鲁棒。由于我们的目的是设计一种实用的方法,作者避免了模拟采集之间差异的困难且可能非常耗时的任务,并且即使只有两个图像可用,寄件人。特别是,作者调整了J-UNIWARD的嵌入成本[7]基于从同一场景的两个JPEG图像推断的优选方向。该方法在使用安装有三脚架的数码相机获得的实际多次曝光中进行测试。所提出的嵌入两个JPEG图像比仅有一个JPEG可供隐写者使用时更安全。
作者用相同场景的第二个JPEG图像的形式在发送者处研究带有边信息的隐写术,用于推断隐写嵌入变化的首选方向。通过减少(调制)这种优选变化的嵌入成本,将该信息结合到嵌入算法中。实际多次采集的实验显示,对于具有单个覆盖图像的隐写术(J-UNIWARD),经验安全性显着增加。经验安全性的提升似乎对两次采集之间的微小差异相当不敏感,这使得所提出的方法实用并且开启了使用手持相机获得的多次曝光或从短视频剪辑获取多次曝光的可能性。
由于采集噪声幅度取决于亮度,因此可以通过优化每个DCT模式的嵌入成本调制,量化步长和DCT块的平均灰度来进一步改进。最后,我们计划研究如何利用两个以上(量化和非量化)的收购。
Steganography With Multiple JPEG Images of the Same Scene
作者:Tomáš Denemark ; Jessica Fridrich
投稿: IEEE Transactions on Information Forensics and Security (Volume: 12 , Issue: 10 , Oct. 2017 )
年份:18 May 2017
主题:具有多个JPEG的隐写术
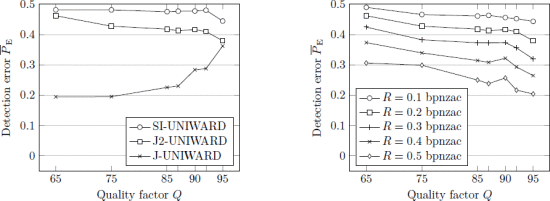
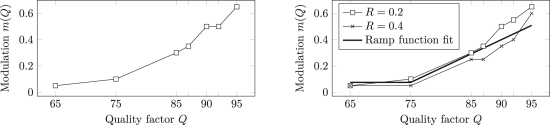
目前,大多数侧知方案利用高质量的“预先”图像,该图像随后被处理,然后联合量化并嵌入秘密。在本文中,我们研究了另一种形式的辅助信息 - 一组同一场景的多个JPEG图像 - 当发送者无法访问预备时。附加的JPEG图像用于确定嵌入变化的优选极性,以调制在现有嵌入方案中改变各个DCT系数的成本。利用合成的采集噪声和使用安装在三脚架上的手持式数码相机获得的实际多次采集对真实图像的测试显示出对于利用单个JPEG图像的隐写术的经验安全性的相当显着的改进。使用蒙特卡罗模拟,通过显示定性相同的调制最小化覆盖的量化广义高斯模型和由AWG采集噪声破坏的隐秘DCT系数之间的Bhattacharyya距离来证明所提出的经验确定的嵌入成本调制是合理的。
简要概述了现有的侧知隐写术,并提供了高质量的预备。在第IV节中,描述了在发送方使用两个或更多JPEG图像的新隐写方法。从现有基于成本的JPEG隐写术的嵌入成本开始,基于从同一场景的第二JPEG图像推导出的优选方向来调制它们。首先对第B部分中的模拟采集噪声对BOSSbase图像进行测试,以便在理想情况下通过简单的采集噪声来查看增益。为了深入了解拟议方案在现实条件下的安全性,请参阅第六节作者描述了两个名为BURSTbase和BURSTbaseH的新数据集,分别用三脚架安装和手持数码相机获得图像。有证据表明BURSTbase中两个最接近的曝光之间的差异是由于异方差的采集噪声。在第七节中,作者首先报告了BURSTbase上J-UNIWARD成本的实验结果跨越广泛的质量因素和有效载荷,并与J-UNIWARD和SI-UNIWARD形成对比,仅使用单个JPEG图像和与其他类型的边信息的比较来查看增益。作者还研究了安全性增益如何随着曝光之间的差异增加而降低。本节继续在J-UNIWARD和UED-JC上使用手持摄像头对BURSTbaseH图像进行实验总结。虽然安全性增益小于BURSTbase,但当隐写员拒绝不良突发时,仍然可以通过单个JPEG的隐写术观察到显着的安全性增益。最后,附录包含解释实验确定的成本调整的形状的分析。该文件在第八节中得出结论。
最佳调制因子 m (Q ) 作为JPEG品质因数的函数 Q 。左图:带有模拟采集噪声的BOSSbase 1.01图像。右:BURSTbase。
参考资料
- 1、生物:宾厄姆顿大学杰西卡弗里德里希
- 2、 跳起来:一 b “杰西卡·弗雷德里奇”。Hindawi出版公司。2002年2月14日。检索2012 年4月19日。
- 3、 Jessica Fridrich,在Youtube上谈话
- Jphide原理剖析及检测
- 基于二次加密的JPhide隐写检测方法
- http://www.ws.binghamton.edu/fridrich/
- Deep Residual Network for Steganalysis of Digital Images
- Applications of Explicit Non-Linear Feature Maps in Steganalysis
- Practical strategies for content-adaptive batch steganography and pooled steganalysis
- Steganography with two JPEGs of the same scene
- Steganography with two JPEGs of the same scene

 浙公网安备 33010602011771号
浙公网安备 33010602011771号