
22图的遍历
图的遍历
图的遍历:搜索属于图的基本运算。树的先序遍历和按层遍历的推广。图的遍历也称搜索,主要有:
先深搜索(depth-first search)——深度优先搜索——dfs搜索
先广搜索(breadth-first search)——广度优先搜索——bfs搜索
遍历目的——完成图运算(求子图或路径):生成树,连通分量,无向图的双连通分量,有向图的强连通分量,有向图顶点的拓扑排序,判断有向图是否有回路,求解迷宫问题。
搜索应用:找出图的生成树、图的连通分量等。
1.先深搜索:
按一定的规律沿着图中的边访问每个顶点恰一次的运算称为对图的遍历(和二叉树遍历相仿)。
其实就是利用递归的思想。比如先访问A结点,而A结点与B相连,就访问B结点,若B与D相连,就接着访问D结点。。。。。。
先深搜索算法
(1)原始描述形式
步骤1)将图G中所有顶点作“未访问过”标记。
步骤2)任选某个未访问过的顶点v作搜索起点。
步骤3)访问v。
步骤4)选择v的每一个未访问过的邻接点w作起点,递归的搜索图G。
步骤5)若所有顶点均已访问过,则搜索结束;否则,转步骤2。
描述形式:
分成主控函数和递归的搜索函数
主控函数
步骤1)将图中每个顶点置未访问标记;
步骤2)检查每个顶点v,如果v未访问过,则dfs(v);递归的搜索函数dfs(v)
步骤3)访问v,并对v作“已访问”标记;
步骤4)检查v的每个邻接点w,如果w未访问过,则调用dfs(w);
步骤5)返回上一次调用点;
示例:
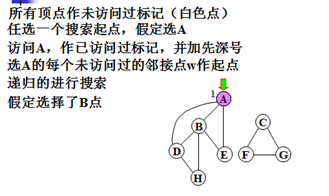

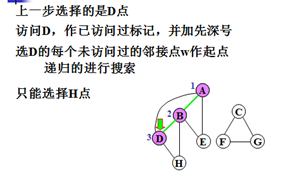
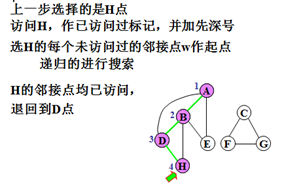
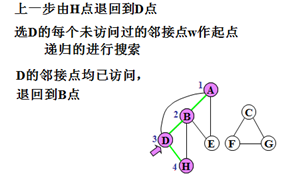

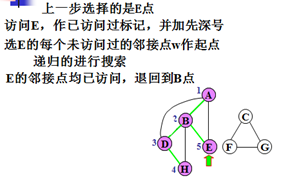
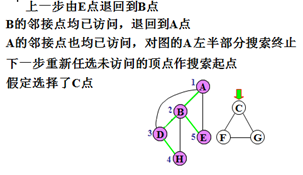
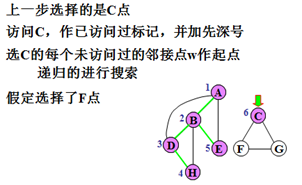

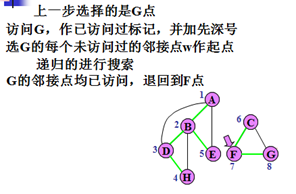
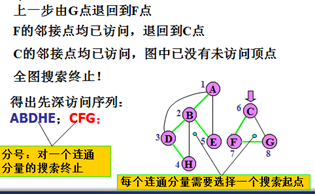
对无向图搜索的特点:
1)若连通,搜索路线构成先深生成树。
2)引起递归的边:树边(tree edge)和回边,或余边(back edge)将E划分成树边集T和回边集B 。

3)若步骤2和4中,如有多个顶点可选,可任选其一搜索路线不唯一,生成树不唯一。
4)若不连通图,产生先深生成森林。
5)不同的子生成树之间不可能有回边相连。
6)祖先的先深号必小于子孙的先深号,对子孙的搜索先终止,而对祖先的搜索后终止。
对有向图搜索的特点:
1)若强连通,可得到先深生成树。
2)非强连通,也不一定不能到先深生成树。
3)可将边集E划分成:树边T、回边B、向前边F和交叉边C 。
注意以下几个术语:
树边:引起递归调用的边。
回边:由子孙射向祖先的边。
向前边F(forward edges):由祖先射向子孙的边。
交叉边C(cross edges):无祖孙关系顶点之间的边。
4)先访问的顶点(先深号小)在上、在左,后访问的顶点在下、在右交叉边:由右射向左,而不会由左射向右。
5)树边和向前边:小号射向大号。
回边和交叉边:大号射向小号。

先深搜索的实现:
由主控函数和递归搜索函数dfs两部分共同完成
图的存储形式:邻接表。
顶点结点含有访问否标志域mark。
未访问点,mark值为0;已访问点,mark值为1。
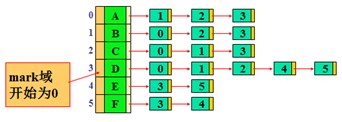
主控函数的功能:
1.对顶点作未访问标记(即初始化)
2.检查是否存在未访问过的顶点
3.选择一个未访问过的顶点作为搜索起点
4.通过搜索起点调用递归的搜索函数dfs
搜索函数dfs(v)的功能:
1.置顶点v已访问标记,使其mark域为1
2.沿v的邻接表检查其各邻接点是否访问过
3.对未访问过的邻接点w,递归调用dfs(w)
4.当v的邻接表“走”完后,对v的搜索终止,退回到dfs(v)的调用点
主控函数
void main_1( )
{ int v;
for (v=0;v<n;v++) L[v].mark=0; //置未访问标记
for (v=0;v<n;v++) //检查各顶点是否访问过
if(L[v].mark= =0) //如果v未访问过
dfs(v); //选v作搜索起点,调用搜索函数
………… // 其他处理操作
}
搜索函数
void dfs (int v) //递归的搜索函数,v是顶点编号
{ Eptr p; int w;
visit(v); // 访问v
L[v].mark=1; // 作访问标记
p=L[v].firstedge; //p指向v的邻接表首结点
while (p!=NULL) //检查v的所有邻接点
{ w=p->adjacent; //w是v的邻接点
if (!L[w].mark)dfs(w); //若w未访问过,递归调用dfs
p=p->next; //递归返回后,再查看v的下一个邻接点
}
}
先深搜索的应用:
对无向图的先深搜索,可以
1.判断是否连通
2.找出连通分量、双连通分量
3.找出生成树或生成林
对有向图的先深搜索,可以
1.判断图中是否存在回路
2.找出强连通分量
3.对顶点进行柘朴排序
求无向图的连通分量算法(这里只给出修改后的主控函数)
void dfsmain()
{ int v,k=0;
for(v=0;v<n;v++)L[v].mark=0;
for(v=0;v<n;v++)
if(L[v].mark==0)
{ k++;
printf("第 %d 个连通分量:\n {",k);
dfs(v);
printf(" }\n");
}
}
求无向图的先深生成树(林)算法(这里只给出修改说明)
主控函数不变
将搜索函数中的:
if(!L[w].mark)dfs(w);
改为 :
if (!L[w].mark)
{ 将(v,w)加进树边集; L[w].father=v; dfs(w); }
判断有向图是否存在回路原理:
执行dfs(v) 期间,区分:T、B、F、C
<v,w>是T,v是w父,w未访问过,dfs(v)未终止
<v,w>是F,v是w祖,dfs(w)已终止
<v,w>是C,v在w之右,dfs(w)已终止
<v,w>是B,w是v祖,w已访问过,dfs(w)未终止
结论:如果w已访问过,但dfs(w)尚未终止,
则<v,w>必是回边
该标记mark的作用:
L[v].mark=0,表示v尚未访问过
L[v].mark=1,表示v已经访问过,但dfs(v)尚未终止
L[v].mark=2,表示v已经访问过,且dfs(v)已经终止
在进入dfs(v)之前,程序置L[v].mark=0
在进入dfs(v)之后,程序置L[v].mark=1
dfs(v)结束处,置L[v].mark=2
判断有向图是否存在回路算法:
主控函数
void dfsmain( )
{ int v;
cycle=0; //cycle是整体量
for(v=0;v<n;v++)L[v].mark=0;
for(v=0;v<n;v++)
if(L[v].mark==0)dfs(v);
if(cycle) printf("图中有回路\n");
else printf("图中没有回路\n");
}
void dfs (int v) //递归的搜索函数,v是顶点编号
{ Eptr p; int w;
visit(v); // 访问v
L[v].mark=1; // 作访问标记
p=L[v].firstedge; //p指向v的邻接表首结点
while (p!=NULL) //检查v的所有邻接点
{ w=p->adjacent; //w是v的邻接点
if(L[w].mark==0)
dfs(w);
elseif(L[w].mark==1)
cycle=1;
//dfs(w)尚未终止,置有回路标记
p=p->next;
}
L[v].mark=2; //置dfs(v)终止标记
}
2.先广搜索
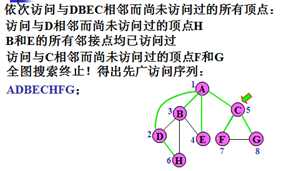
优先选择广度,比如A与C、D、E、D,访问A结点后,依次访问C、D、E、D,不会继续递归访问与C相连接的结点。
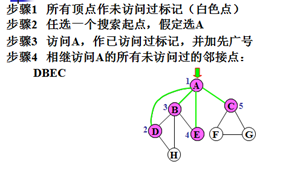
是二叉树按层遍历的推广,算法描述:
步骤1)将图中所有顶点作“未访问过”标记。
步骤2)任选图中一个尚未访问过的顶点v作搜索起点。
步骤3)访问v。
步骤4)相继地访问与v相邻而尚未访问的所有顶点
w1,w2……,并依次访问与这些顶点相邻而尚未访问过的所有顶点。
反复如此,直到找不到这样的顶点。
步骤5)若图中尚有未访问过的顶点,则转步骤2;否则,搜索结束。
示例
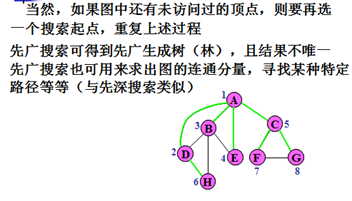
先广搜索的实现:
图存储形式:邻接表
用一个队存放等待访问的顶点。
顶点结点含有进队否标志域mark。
未进队,mark值为0;已进过队,mark值为1。
注意点:使用队结构记录搜索路线(存放着等待访问的顶点)

图的先广搜索算法:
void bfs( )
{ Eptr p; int u,v,w,first,last,q[n];
1. first=last=0; //队列初始化
2. for(u=0;u<n;u++) L[u].mark=0; //初始化
3. for(u=0;u<n;u++) //找未进过队的顶点
4. if(!L[u].mark) //若u未进队
5. { q[last++]=u; //u进队
6. L[u].mark=1; //置u进队标记
7. while(first!=last) //当队列不空时循环
8. { v=q[first++]; //v出队
9. visit(v); //访问v
10. p=L[v].firstedge; //检查v的邻接点
11. while(p!=NULL)
12. { w=p->adjacent; // w是v的邻接点
13. if (!L[w].mark) //若w未进过队
14. { q[last++]=w; L[w].mark=1; } w进队
15. p=p->next; //找v的下一个邻接点
} // 与句12对应
} // 与句8对应,到队空
} // 与句5对应,以u为起点的搜索结束
}
两种搜索算法对照:
1.先深搜索算法比先广搜索算法结构好。
2.先深搜索可写成递归形式,而先广搜索无法写成递归形式
3.先深搜索更常用

