
3循环与递归
循环设计中要注意算法的效率:
循环体的特点是:“以不变应万变”。
所谓“不变”是指循环体内运算的表现形式是不变的,而每次具体的执行内容却是不尽相同的。在循环体内用不变的运算表现形式去描述各种相似的重复运算。
【例1】求1/1!-1/3!+1/5!-1/7!+…+(-1)n+1/(2n-1)!
分析:此问题中既有累加又有累乘,准确地说累加的对象是累乘的结果。
数学模型1:Sn=Sn-1+(-1)n+1/(2n-1)!
算法设计1:多数初学者会直接利用题目中累加项通式,构造出循环体不变式为:
S=S+(-1)n+1/(2n-1)!
需要用二重循环来完成算法,算法1如下:
main( )
{int i,n,j,sign=1;
float s,t=1;
input(n);
s=1;
for(i=2;i<=n;i=i+1)
{t=1; \求阶乘\
for(j=1;j<=2*i-1;j=j+1)
t=t*j;
sign =1; \求(-1)n+1\
for(j=1;j<=i+1;j=j+1)
sign = sign *(-1);
s=s+ sign/t;
}
print(“Snm=”,s);
}
算法分析:
以上算法是二重循环来完成 ,但算法的效率却太低是O(n2)。
其原因是,当前一次循环已求出7!,当这次要想求9!时,没必要再从1去累乘到9,只需要充分利用前一次的结果,用7!*8*9即可得到9!,模型为An=An-1*1/((2*n-2)*(2*n-1)。另外运算sign = sign *(-1);总共也要进行n*(n-1)/2次乘法,这也是没有必要的。下面我们就进行改进。
数学模型2:Sn=Sn-1+(-1)n+1An;
An=An-1 *1/((2*n-2)*(2*n-1))
算法2如下:
main( )
{int i,n, sign;
float s,t=1;
input(n);
s=1;
sign=1;
for(i=2;i<=n;i=i+1) 或 for(i=1;i<=n-1;i=i+1)
{sign=-sign; { sign=-sign;
t= t*(2*i-2)*(2*i-1)} t= t*2*i*(2*i+1)};
s=s+sign/t; } s=s+ sign/t; }
print(“Sum=”,s);
}
算法说明2:
构造循环不变式时,一定要注意循环变量的意义,如当i不是项数序号时(右边的循环中)有关t的累乘式与i是项数序号时就不能相同。
算法分析:按照数学模型2,只需一重循环就能解决问题
算法的时间复杂性为O(n)。
【例2】编算法找出1000以内所有完数
例如,28的因子为1、2、4、7,14,而28=1+2+4+7+14。因此28是“完数”。编算法找出1000之内的所有完数,并按下面格式输出其因子:28 it’s factors are 1,2,4,7,14。
1)这里不是要质因数,所以找到因数后也无需将其从数据中“除掉”。
2)每个因数只记一次,如8的因数为1,2,4而不是1,2,2,2,4。(注:本题限定因数不包括这个数本身)
1)顶层算法
for(i=0;i<n;i=i+1)
{找第i行上最小的元素t及所在列minj;
检验t是否第minj 列的最大值,是则输出这个鞍点;}
2)找第i行上最小的元素t及所在列minj
t=a[i][0]; minj=1;
for(j=1;j<n;j=j+1)
if(a[i][j]<t)
{t=a[i][j];
minj=j;}
3)进一步细化——判断i是否“完数”算法
s=1
for(j=2;j<i;j=j+1)
if (i mod j=0) (j是i的因数) s=s+j;
if (s=i) i是“完数”;
4)考虑输出格式——判断i是否“完数”算法
考虑到要按格式输出结果,应该开辟数组存储数据i的所有因子,并记录其因子的个数,因此算法细化如下:
定义数组a,s=1; k=0;
for(j=2;j<i;j=j+1)
if (i mod j=0) (j是i的因素)
{s=s+j; a[k]=j;k=k+1;}
if (s=i)
{按格式输出结果}
算法如下:
main( )
{int i,k,j,s,a[20];
for(i=1;i<=1000;i++)
{s=1; /*两个赋初值语句s=1,k=0
k=0; 一定要位于外部循环的内部*/
for(j=2;j<i;j++)
if (i mod j)==0)
{s=s+j; a[k]=j; k++;}
if(i==s)
{print(s, “it’s factors are :”,1);
for(j=0;i<k;j++)
print(“,”,a[k]);
}
}
}
【例3】求一个矩阵的鞍点
(即在行上最小而在列上最大的点)。
算法设计:
1)在第一行找最小值,并记录其列号。
2)然后验证其是否为所在列的最大值,如果是,则找到问题的解;否则,则继续在下一行找最小值 …… 。
1)顶层算法
for(i=0;i<n;i=i+1)
{找第i行上最小的元素t及所在列minj;
检验t是否第minj 列的最大值,是则输出这个鞍点;}
2)找第i行上最小的元素t及所在列minj
t=a[i][0]; minj=1;
for(j=1;j<n;j=j+1)
if(a[i][j]<t)
{t=a[i][j];
minj=j;}
3)检验t是否第minj 列的最大值,是,则输出这个鞍点;
for(k=0;k<n;k=k+1)
if(a[k][minj]>t) break;
if(k<n) continue;
print(“the result is a[“,i ,“][” ,minj, “]=”,t);
考虑到会有无解的情况,设置标志量kz,kz=0代表无解,找到一个解后,kz被赋值为1,就不再继续找鞍点的工作。请读者考虑是否有多解的可能性吗?若有,请改写算法,找出矩阵中所有的鞍点。
算法如下:
buck( )
{int a[10][10]; int i,j,k,minj,t,n=10,kz=0;
/*minj代表当前行中最小值的列下标;设置标志量kz*/
readmtr(a,n);
prntmtr(a,n);
for(i=0;i<n;i++)
{t=a[i][0]; minj=1;
for(j=1;j<n;j++)
if(a[i][j]<t)
{t=a[i][j];minj=j;}
for(k=0;k<n;k++)
if(a[k][minj]>a[i][minj]) break;
if(k<n) continue;
print(“the result is a[“,i ,“][”,minj,“]=”,a[i][minj]);
kz=1;
break;
}
if(kz==0) print(“no solution!”);
}
由具体到抽象设计循环结构
对于不太熟悉的问题,其数学模型或“机械化操作步骤”的不易抽象,下面看一个由具体到抽象设计循环细节的例题。
【例4】编写算法:打印具有下面规律的图形。
1
5 2
8 6 3
10 9 7 4
算法设计:容易发现图形中自然数在矩阵中排列的规律,题目中1,2,3,4所在位置我们称为第1层(主对角线),例图中5,6,7所在位置我们称为第二层,……。一般地,第一层有n个元素,第二层有n-1个元素……
基于以上数据变化规律,以层号作为外层循环,循环变量为i(范围为1——n);以层内元素从左上到右下的序号作为内循环,循环变量为j(范围为1——n+1-i)。这样循环的执行过程正好与“摆放”自然数的顺序相同。用一个变量k模拟要“摆放”的数据,下面的问题就是怎么样将数据存储到对应的数组元素。
数组元素的存取,只能是按行、列号操作的。所以下面用由具体到抽象设计循环的“归纳法”,找出数组元素的行号、列号与层号i及层内序号j的关系:
1.每层内元素的列号都与其所在层内的序号j是相同的。因为每层的序号是从第一列开始向右下进行。
2.元素的行与其所在的层号及在层内的序号均有关系,具体地:
第一层行号1——n,行号与j同;
第二层行号2——n,行号比j大1;
第三层行号3——n,行号比j大2;
……
行号起点随层号i增加而增加,层内其它各行的行号又随层内序号j增加而增加,由于编号起始为1,i层第j个数据的列下标为i-1+j。
综合以上分析,i层第 j个数据对应的数组元素是a[i-1+j][j]。
算法如下:
main( )
{int i,j,a[100][100],n,k;
input(n);
k=1;
for(i=1;i<=n;i=i+1)
for( j=1;j<=n+1-i;j=j+1)
{a[i-1+j][j]=k;
k=k+1;}
for(i=1;i<=n;i=i+1)
{print( “换行符”);
for( j=1;j<=i;j=j+1)
print(a[i][j]);
}
}
递归设计要点
递归算法是一个模块(函数、过程)除了可调用其它模 块(函数、过程)外,还可以直接或间接地调用自身的算法。
递归是一种比迭代循环更强、更好用的循环结构。
只需要找出递归关系和最小问题的解。
递归方法只需少量的步骤就可描述出解题过程所需要的多次重复计算,大大地减少了算法的代码量。
递归的关键在于找出递归方程式和递归终止条件。
递归定义:使问题向边界条件转化的规则。递归定义必须能使问题越来越简单。
递归边界条件:也就是所描述问题的最简单情况,它本身不再使用递归的定义。
递归算法解题通常有三个步骤:
1)分析问题、寻找递归:找出大规模问题与小规模问题的关系,这样通过递归使问题的规模逐渐变小。
2)设置边界、控制递归:找出停止条件,即算法可解的最小规模问题。
3)设计函数、确定参数:和其它算法模块一样设计函数体中的操作及相关参数。
【例1】汉诺塔问题描述:
古代有一个梵塔,塔内有3个基座A、B、C,开始时A基座上有64个盘子,盘子大小不等,大的在下,小的在上。有一个老和尚想把这64个盘子从A座移到B座,但每次只允许移动一个盘子,且在移动过程中在3个基座上的盘子都始终保持大盘在下,小盘在上。在移动过程中可以利用C基座做辅助。请编程打印出移动过程 。
算法设计:
用归纳法解此题,约定盘子自上而下的编号为1,2,3,……,n。
首先看一下2阶汉诺塔问题的解,不难理解以下移动过程:
初始状态为 A(1,2) B() C()
第一步后 A(2) B() C(1)
第二步后 A() B(2) C(1)
第三步后 A() B(1,2) C()
如何找出大规模问题与小规模问题的关系,从而实现递归呢?
把n个盘子抽象地看作“两个盘子”,上面“一个”由1——n-1号组成,下面“一个”就是n号盘子。移动过程如下:
第一步:先把上面“一个”盘子以a基座为起点借助b基座移到c基座。
第二步:把下面“一个”盘子从a基座移到b基座。
第三步:再把c基座上的n-1盘子借助a基座移到b基座。
把n阶的汉诺塔问题的模块记作hanoi(n,a,b,c)
a代表每一次移动的起始基座,
b代表每一次移动的终点基座,
c代表每一次移动的辅助基座
则汉诺塔问题hanoi(n,a,b,c)等价于以下三步:
第一步,hanoi(n-1,a,c,b);
第二步,把下面“一个”盘子从a基座移到b基座;
第三步, hanoi(n-1,c,b,a)。
至此找出了大规模问题与小规模问题的关系。
算法如下:
hanoi (int n,char a,char b,char c)
/ a,b,c 初值为”A”,”B”,”C”/
1) if(n>0) /*0阶的汉诺塔问题当作停止条件*/
2) hanoi(n-1,a,c,b);
3) 输出 “ Move dise” ,n.”from pile”,a,” to”b);
4) haboi(n-1,c,b,a);
5) endif }
【例2】整数的分划问题
对于一个正整数n的分划就是把n写成一系列正整数之和的表达式。例如,对于正整数n=6,它可以分划为:
6
5+1
4+2, 4+1+1
3+3, 3+2+1, 3+1+1+1
2+2+2, 2+2+1+1, 2+1+1+1+1
1+1+1+1+1+1
根据例子发现“包括第一行以后的数据不超过6,包括第二行的数据不超过5,……,第六行的数据不超过1”。
因此,定义一个函数Q(n,m),表示整数n的“任何被加数都不超过m”的分划的数目,n的所有分划的数目P(n)=Q(n,n)。
模型建立:
一般地Q(n.m)有以下递归关系:
1)Q(n,n)=1+Q(n,n-1) (m=n)
Q(n,n-1)表示n的所有其他分划,即最大被加数m<=n-1的划分。
2)Q(n,m)=Q(n,m-1)+Q(n-m,m) (m<n)
Q(n,n-1)表示被加数中不包含m的分划的数目;
Q(n-m,m)表示被加数中包含(注意不是小于)m的分划的数目,
递归的停止条件:
1)Q(n,1)=1,表示当最大的被加数是1时,该整数n只有一种分划,即n个1相加;
2)Q(1,m)=1,表示整数n=1只有一个分划,不管最大被加数的上限m是多大。
算法如下:
Divinteger(n, m)
{if (n < 1 or m
< 1 or m > n )
Error(“输入参数错误”); /*n<m Q(n,m)是无意义的*/
else if (n = 1 or m = 1)
return(1);
else if ( n < m )
return Divinteger(n, n)
else if (n = m )
return(1 + Divinteger(n,
n-1))
else return(Divinteger(n,m-1)+Divinteger(n-m,m));
}
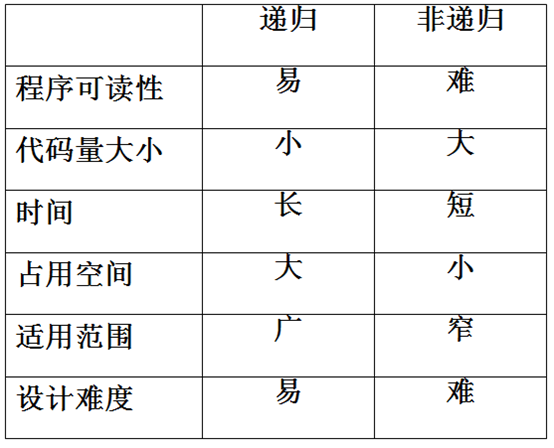
递归与循环的比较
◆递归与循环都是解决“重复操作”的机制。
◆递归使一些复杂的问题处理起来简单明了。
◆就效率而言,递归算法的实现往往要比迭代算法耗费更多的时间(调用和返回均需要额外的时间)与存贮空间(用来保存不同次调用情况下变量的当前值的栈栈空间),也限制了递归的深度。
◆每个迭代算法原则上总可以转换成与它等价的递归算法;反之不然 。
◆递归的层次是可以控制的,而循环嵌套的层次只能是固定的,因此递归是比循环更灵活的重复操作的机制。
下面通过几个具体的例子来说明循环和递归的差异和优劣。
【例1】任给十进制的正整数,请从低位到高位逐位输出各位数字。
循环算法设计:从题目中我们并不能获知正整数的位数,再看题目的要求,算法应该从低位到高位逐位求出各位数字并输出。详细设计如下:
1) 求个位数字的算式为
n mod 10
2) 为了保证循环体为“不变式”,求十位数字的算式仍旧为n mod 10,这就要通过算式n=n\10,将n的十位数变成个位数。
循环算法如下:
f1(n)
{while(n>=10)
{ print( n mod 10);
n=n\10;}
print(n);
}
递归算法设计:
1)同上,算法从低位到高位逐位求出各位数字并输出,求个位数字的算式为 n mod 10,下一步则是递归地求n\10的个位数字。
2)当n<10时,n为一位数停止递归。
递归算法如下:
f2(n)
{if(n<10)
print(n);
else
{ print( n mod 10);
f(n\10);}
}
【例2】任给十进制的正整数,请从高位到低位逐位输出各位数字。
循环算法设计:本题目中要求“从高位到低位”逐位输出各位数字,但由于我们并不知道正整数的位数,算法还是“从低位到高位”逐位求出各位数字比较方便。这样就不能边计算边输出,而需要用数组保存计算的结果,最后倒着输出。
循环算法如下:
f3(n)
{int j,i=0,a[16];
while(n>=10)
{ a[i]=n mod 10;
i=i+1;
n=n\10;}
a[i]=n;
for(j=i;j>=0;j=j-1)
print(a[j]);
}
递归算法设计:
与f2不同,递归算法是先递归地求n\10的个位数字,然后再求个位数字n的个位数字并输出。这样输出操作是在回溯时完成的。递归停止条件与f2相同为n<10。
递归算法如下:
f4(n)
{if(n<10)
print(n);
else
{ f(n\10);
print( n mod 10); }
}
由于递归算法的实现包括递归和回溯两步,当问题需要“后进先出”的操作时,还是用递归算法更有效。如数据结构课程中树各种遍历、图的深度优先等算法都是如此。所以不能仅仅从效率上评价两个控制重复机制的好坏。
事实上,无论把递归作为一种算法的策略,还是一种实现机制,对我们设计算法都有很好的帮助。看下面的例子:
【例3】找出n个自然数(1,2,3,…,n)中r个数的组合。
例如,当n=5,r=3时,所有组合为:
1 2 3
1 2 4
1 2 5
1 3 4
1 3 5
1 4 5
2 3 4
2 3 5
2 4 5
3 4 5
total=10 {组合的总数}
算法设计1:
1)n个数中r的组合,其中每r个数中,数不能相同;
2)任何两组组合的数,所包含的数也不应相同。
例如,5、4、3与3、4、5。为此,约定前一个数应小于后一个数。将上述两条作为约束条件;
3)当r=3时,可用三重循环进行枚举。
算法1如下:
constitute1()
{int n=5,i,j,k,t;
t=0;
for(i=1;i>=n;i--)
for(j=1;j>=n;j--)
for(k=1;k>=n;k--)
if(i<>j)and(i<>k)and(i<j)and(j<k)
{t=t+1;
print(i,j,k);}
print('total=',t);
}
或者
constitute2()
{int n=5,r=3,i,j,k,t;
t=0;
for(i=1;i<=n-r+1; i=i+1)
for(j=i+1;j<= n-r+2;j=j+1)
for(k=j+1;k<=n-r+3;k=k+1)
{t=t+1;
print(i,j,k);}
print('total=',t);
}
用递归法设计此题:
在循环算法设计中,对n=5的实例,每个组合中的数据从小到大排列或从大到小排列一样可以设计出相应的算法。但用递归思想进行设计时,每个组合中的数据从大到小排列却是必须的;因为递归算法设计是要找出大规模问题与小规模问题之间的关系。
例如,当n=5,r=3时,所有组合为:
5 4 3
5 4
2
5 4
1
5 3
2
5 3
1
5 2
1
4 3
2
4 3
1
4 2
1
3 2
1
total=10
分析n=5,r=3时的10组组合数。
1)首先固定第一个数5,其后就是n=4,r=2的组合数,共6个组合。
2)其次固定第一个数4,其后就是n=3,r=2的组合数,共3个组合。
3)最后固定第一个数3,其后就是n=2,r=2的组合数,共1个组合。
至此找到了“5个数中3个数的组合”与“4个数中2个数的组合、3个数中2个数的组合、2个数中2个数的组合”的递归关系。
则递归算法的三个步骤为:
1)一般地:n个数中r个数组合递推到“n-1个数中r-1个数有组合,n-2个数中r-1个数有组合,……,r-1个数中r-1个数有组合”,共n-r+1 次递归。
2)递归的边界条件是的r=1。
3)函数的主要操作就是输出,每当递归到r=1时就有一组新的组合产生,输出它们和一个换行符。
注意n=5,r=3的例子中的递归规律,先固定5,然后要进行多次递归也就是说,数字5要多次输出,所以要用数组存储以备每一次递归到r=1时输出。同样每次向下递归都要用到数组,所以将数组设置为全局变量 。
递归算法如下:
int a[100];
comb(int m,int k)
{ int i,j;
for (i=m;i>=k;i--)
{ a[k]=i;
if (k>1)
comb(i-1,k-1);
else
{ for (j=a[0];j>0;j--)
print(a[j]);
print(“换行符”);
}
}
}
comb(int m,int k)
{ int i,j;
for (i=m;i>=k;i--)
{ a[k]=i;
if (k>1)
comb(i-1,k-1);
else
{ for (j=a[0];j>0;j--)
print(a[j]);
print(“换行符”);
}
}
}
分析:算法2递归的深度是r,每个算法要递归m-k+1次,所以的时间复杂性是O(r*n)。
递归是一种强有力的算法设计方法。递归是一种比循环更强、更好用的实现“重复操作”的机制。因为递归不需要编程者(算法设计者)自己构造“循环不变式”,而只需要找出递归关系和最小问题的解。递归在很多算法策略中得以运用,如:分治策略、动态规划、图的搜索等算法策略。
综合以上讨论,可以得出以下结论:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号