

深度学习激活函数比较
一、Sigmoid函数
1)表达式
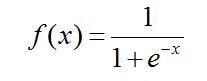

2)函数曲线

3)函数缺点
-
-
- 梯度饱和问题。先看一下反向传播计算过程:
-
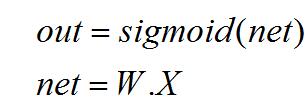
反向求导:
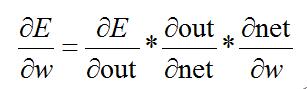
而其中:
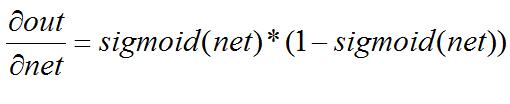
所以,由上述反向传播公式可以看出,当神经元数值无线接近1或者0的时候,在反向传播计算过程中,梯度也几乎为0,就导致模型参数几乎不更新了,对模型的学习贡献也几乎为零。也称为参数弥散问题或者梯度弥散问题。
同时,如果初始权重设置过大,会造成一开始就梯度接近为0,就导致模型从一开始就不会学习的严重问题。
-
-
- 函数不是关于原点中心对称的。
这个特性会导致后面网络层的输入也不是零中心的,也就是说经过sigmoid发出的值x只可能是正值,而不可能是负值,对于下一层的参数w的更新会有影响,因为下一层参数的更新需要用到这个值x,这个如果既可以为正值又可以为负值的话,那么参数w的更新就可以根据实际需要快速增大或者快速减小,很快收敛。如果激活函数是以零为中心,就可以既发出正值也可以发出负值。

- 函数不是关于原点中心对称的。
-
二、tanh函数
1)公式
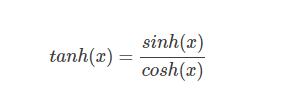
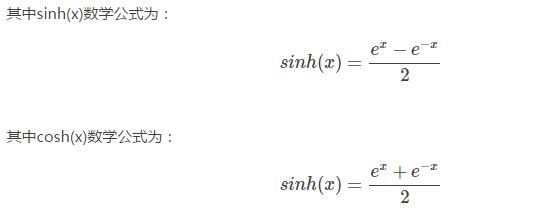
2) 导数
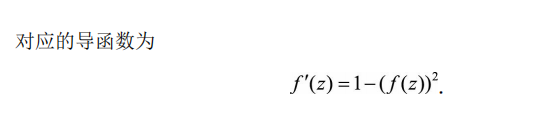
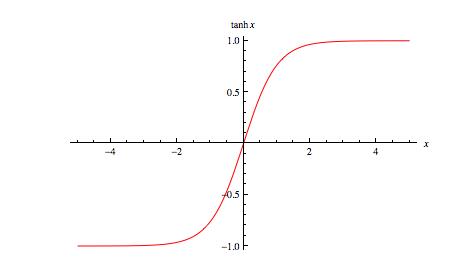
3)曲线
tanh(x)=2sigmoid(2x)-1
tanh 函数同样存在饱和问题,但它的输出是零中心的,因此实际中 tanh 比 sigmoid 更受欢迎。
三、ReLU函数
1)表达式
f(x)=max(0,x)
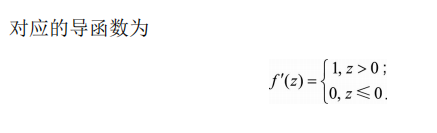
2)曲线
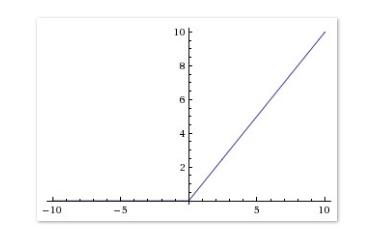
相较于 sigmoid 和 tanh 函数,ReLU 对于 SGD 的收敛有巨大的加速作用(Alex Krizhevsky 指出有 6 倍之多)。有人认为这是由它的线性、非饱和的公式导致的。我觉得最起码在右半轴ReLU函数的梯度是恒定的,不存在饱和情况,只是在左侧存在梯度硬饱和,sigmoid函数属于两端都软饱和,这可能是ReLU函数相对比较受欢迎的原因吧,最起码有一端比较完美了。
ReLU 的缺点是,它在训练时比较脆弱并且可能“死掉”,就是在梯度为0硬饱和的时候,容易出现这种死掉的情况。

局限性

3)改进


