Coursera在线学习---第九节(1).异常数据检测(Anomaly Detection)
一、如何构建Anomaly Detection模型?

二、如何评估Anomaly Detection系统?
1)将样本分为6:2:2比例
2)利用交叉验证集计算出F1值,可以用F1值选取概率阈值ξ,选取使得F1值最大的那个ξ。
3)同时也可以根据训练集、交叉验证集、测试集来同样选取使用哪些特征变量更好。方法就是不断更换特征组合构建模型,利用交叉验证集计算F1值,并看测试集的效果等等。

三、什么时候用异常数据检测法,什么时候用有监督的分类方法?
1)一般来讲,当样本中有大量正常样本数据,而仅仅有少量异常点数据时,这个时候建议构建Anomaly Detection模型。因为异常样本太少,无法进行有效的监督训练;而此时因为有大量的正样本数据,可以有效的拟合高斯模型。当正样本与负样本数量都比较大的时候,可以采用有监督的学习方法,这就是两种方法的不同之处。
2)另一种不同在于,异常数据点的出现情况往往是多种多样、不可预测的。所以,这个时候只对正常数据样本拟合模型即可,不符合该模型的数据均可视为异常数据点。而有监督的学习方法需要有明确的正样本与负样本标签,让机器明白无误的去训练学习。
四、应用举例
网络欺骗登陆检测。如果收集了大量的网站欺骗行为数据,可以选择用监督方法来实现检测。如果少量欺骗行为数据,还是用Anomaly Detection方法比较好。
五、样本数据的分布转换
如果原始样本数据符合高斯分布(也叫正态分布),则可以直接拟合高斯模型。如果原始样本不符合高斯分布,则可以采用log(x)、log(x+c)、X^(1/2)、X^(1/3)等方法对原始样本进行转换,使其符合高斯分布。可以采用hist(x)画直方图看分布状态。


六、如何筛选特征变量?
尽量选取一些浮动不是特别大的变量,如果浮动大了,必然是异常数据了。也可以新增一些组合特征变量,比如:x1/x2,x1^2/x2等。
七、拟合多元高斯分布模型。
有这样一种情况,比如:x1与x2正常情况下是正相关的,但是出现了一个异常数据,就是x1突然变得很大,而x2则不是特别大。这种情况如果采用上述方法单独拟合模型,则检测不出该异常点,因为两个变量数据在各自分布中都是正常的。所以,一种方法就是新增特征组合x1/x2,另一种方法就是采用多元高斯分布。
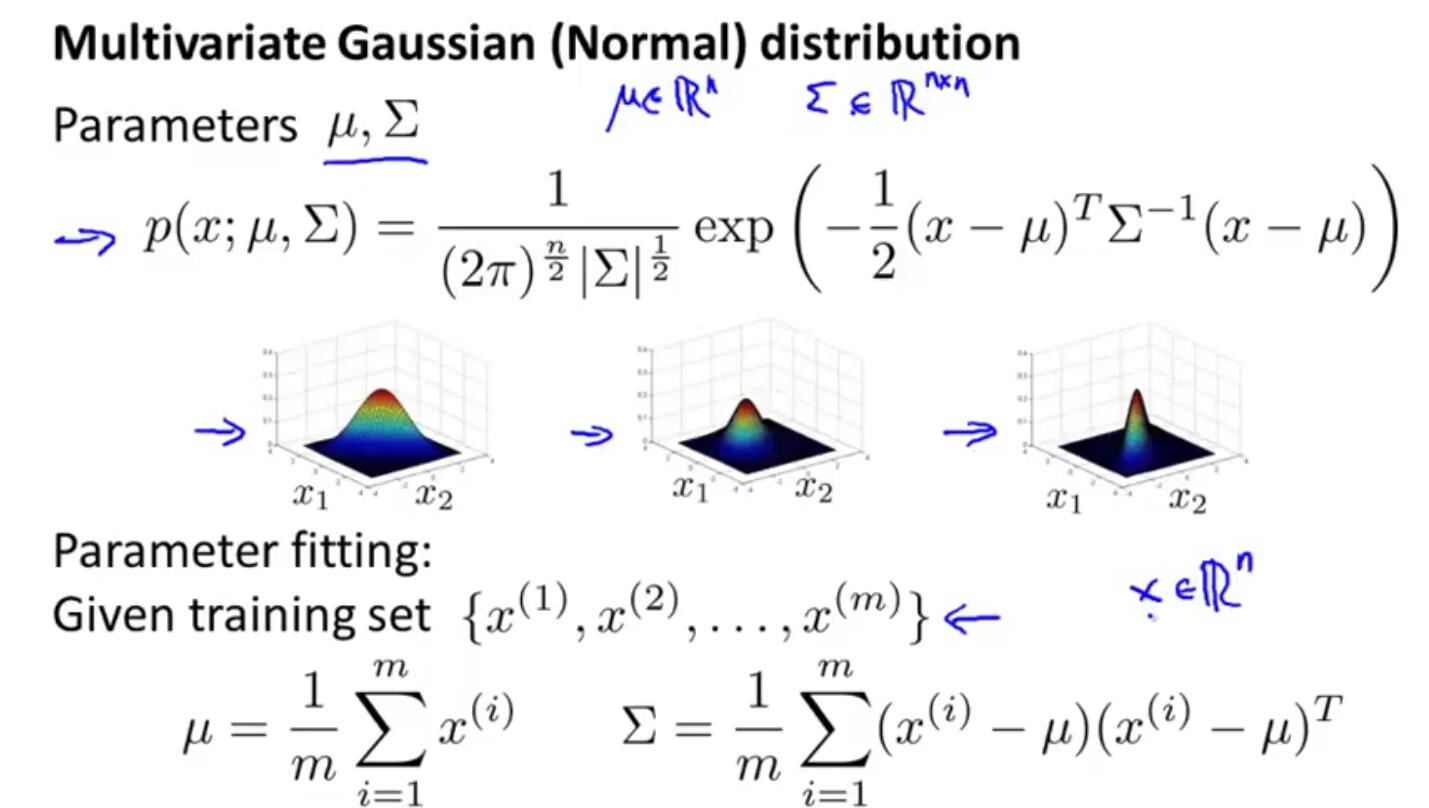
八、什么时候用一元高斯模型,什么时候用多元高斯模型?
一般来说,一元高斯模型用的较多,而多元高斯模型用的不多。但是,对于特征变量x1,x2的一些异常组合情况,多元高斯模型能够检测出来。一元高斯模型如果也想检测出该异常数据,需要增加新的特征组合。
综合来说,一元高斯模型计算量小一些,当特征维度n较大时,采用一元模型较好。而多元高斯模型需要计算矩阵,代价太大,而且还要求m>n(m为样本数量),否则矩阵为不可逆矩阵。当m约等于10倍n的数量之上时,用多元模型较好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号