
LSTM之Keras中Stateful参数
一、Sateful参数介绍
在Keras调用LSTM的参数中,有一个stateful参数,默认是False,也就是无状态模式stateless,为True的话就是有状态模式stateful,所以这里我们就归为两种模式:
- 有状态模型(stateful LSTM)
- 无状态模型(stateless LSTM)
那两者到底是什么区别呢,怎么使用呢?
二、区别
- stateful LSTM
- 除了正常的单个sample内部时间步之间的状态互相传递外(这个是LSTM的基本功能),sample之间的状态还能互相传递。但是需要确定batch_size大小,传递的时候是前一个batch的第i个sample最终输出状态,传递给后一个batch的第i个sample,作为其状态的初始化值。以“解放军第72集团军某旅500名抗洪子弟兵撤离安徽铜陵枞阳县,赶赴合肥庐江县继续抗洪。当地百姓冒着大雨追着驶出的车辆,递上自家的莲蓬、葡萄、熟鸡蛋等食物,送别子弟兵。”为例子,第一句话为一个sample,第二句话为第二个sample,每个sample内部的word为一个时间步,很明显前后两个sample是相互关联的。如果设置batch_size=1,则第一句话最终输出状态(即最后一个word的状态输出),就可以传递给第二句话作为其初始状态值。
- 优点:后面的语句有了更合理的初始化状态值,显然会加快网络的收敛,所以需要更小的网络、更少的训练时间。
- 缺点:每一个epoch后,要重置一下状态,因为训练一遍了,状态不能循环使用,要从头开始。
- 使用注意事项:调用fit() 时指定 shuffle = False,要保证sample之间的前后顺序;可以使用 model.reset_states()来重置模型中所有层的状态,也可使用layer.reset_states()来重置指定有状态 RNN 层的状态。
- stateless LSTM
stateless就是与stateful相反了,就是sample之间没有前后状态传递的关系,输入samples后,默认就会shuffle,可以说是每个sample独立,适合输入一些没有关系的样本。
三、问答
1、在Keras中stateless LSTM中的stateless指的是?
注意,此文所说的stateful是指的在Keras中特有的,是batch之间的记忆cell状态传递。而非说的是LSTM论文模型中表示那些记忆门,遗忘门,c,h等等在同一sequence中不同timesteps时间步之间的状态传递。假定我们的输入X是一个三维矩阵,shape = (nb_samples, timesteps, input_dim),每一个row代表一个sample,每个sample都是一个sequence小序列。X[i]表示输入矩阵中第i个sample。步长啥的我们先不用管。当我们在默认状态stateless下,Keras会在训练每个sequence小序列(=sample)开始时,将LSTM网络中的记忆状态参数reset初始化(指的是c,h而并非权重w),即调用model.reset_states()。
2、为啥stateless LSTM每次训练都要初始化记忆参数?
因为Keras在训练时会默认地shuffle samples,所以导致sequence之间的依赖性消失,sample和sample之间就没有时序关系,顺序被打乱,这时记忆参数在batch、小序列之间进行传递就没意义了,所以Keras要把记忆参数初始化。
四、代码举例
通过对cos函数的预测来分别对比stateless和stateful的差别
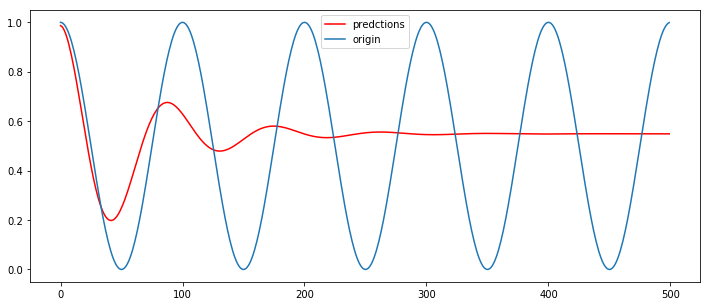
1、 单层无状态LSTM模型(序列长度为20)
import numpy as np from keras.models import Sequential from keras.layers import Dense, LSTM, Dropout import matplotlib.pyplot as plt # 创建数据集,每隔50个就是一个整Π,围绕Π的系数不断变化 dataset = np.cos(np.arange(1000)*(20*np.pi/1000))#dataset的值域再-1~1之间。 # 转换数据为LSTM输入格式: dataset matrix def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset)-look_back): dataX.append(dataset[i:(i+look_back)]) dataY.append(dataset[i + look_back]) return np.array(dataX), np.array(dataY) # 20长度的滑动窗口进行预测 look_back = 20 # 归一化,y值域为(0,1) dataset = (dataset+1) / 2. # split into train and test sets train_size = int(len(dataset) * 0.8) test_size = len(dataset) - train_size train, test = dataset[:train_size], dataset[train_size:] trainX, trainY = create_dataset(train, look_back) testX, testY = create_dataset(test, look_back) print(trainX.shape) print(trainY.shape) trainX = np.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1)) testX = np.reshape(testX, (testX.shape[0], testX.shape[1], 1)) ''' trainX.shape = (780, 20, 1) testX.shape = (180, 20, 1) trainY.shape = (780,) testY.shape = (180,) ''' #构建无状态LSTM模型 batch_size = 1 model = Sequential() model.add(LSTM(32, input_shape=(20, 1))) model.add(Dropout(0.2)) model.add(Dense(1)) model.compile(loss = 'mse', optimizer = 'adam') model.fit(trainX,trainY,batch_size = batch_size,epochs=30, verbose=2) #从训练集的最后一个sample样本截取后面的19个+y值得1个,构成一个新的sample(20,1),来预测一个值,其实这个值就是测试集的第一个值, x = np.vstack((trainX[-1][1:],(trainY[-1])))#vstack就是竖着拼起来 preds=[] pred_num = 500 for i in np.arange(pred_num): #重新转换成适合lstm的格式,并进行预测 pred = model.predict(x.reshape((1,-1,1)),batch_size = batch_size) preds.append(pred.squeeze()) x = np.vstack((x[1:],pred)) #横坐标就是1~500 plt.figure(figsize=(12,5)) plt.plot(np.arange(pred_num),np.array(preds),'r',label='predctions') cos_y = (np.cos(np.arange(pred_num)*(20*np.pi/1000))+1)/ 2. plt.plot(np.arange(pred_num),cos_y,label='origin') plt.legend() plt.show()
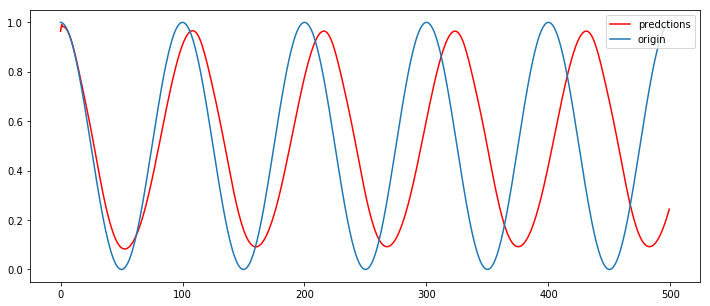
2、单层有状态LSTM模型(序列长度为40)
# 单层有状态 LSTM network # 创建数据集,每隔50个就是一个整Π,围绕Π的系数不断变化 dataset = np.cos(np.arange(1000)*(20*np.pi/1000))#dataset的值域再-1~1之间。 # 转换数据为LSTM输入格式: dataset matrix def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset)-look_back): dataX.append(dataset[i:(i+look_back)]) dataY.append(dataset[i + look_back]) return np.array(dataX), np.array(dataY) # 建立模型:双层stacked Stateful LSTM look_back =40 dataset = np.cos(np.arange(1000)*(20*np.pi/1000)) #归一化,y值域为(0,1) dataset = (dataset+1) / 2. # split into train and test sets train_size = int(len(dataset) * 0.8) test_size = len(dataset) - train_size train, test = dataset[:train_size], dataset[train_size:] trainX, trainY = create_dataset(train, look_back) testX, testY = create_dataset(test, look_back) trainX = np.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1)) testX = np.reshape(testX, (testX.shape[0], testX.shape[1], 1)) batch_size = 1 model2 = Sequential() model2.add(LSTM(32, batch_input_shape=(batch_size, look_back, 1), stateful=True)) model2.add(Dropout(0.2)) model2.add(Dense(1)) model2.compile(loss='mse', optimizer='adam') for i in range(30): model2.fit(trainX, trainY, epochs=1, batch_size=batch_size, shuffle=False) model2.reset_states() x = np.vstack((trainX[-1][1:],(trainY[-1]))) preds = [] pred_num = 500 for i in np.arange(pred_num): pred = model2.predict(x.reshape((1,-1,1)),batch_size = batch_size) preds.append(pred.squeeze()) x = np.vstack((x[1:],pred)) plt.figure(figsize=(12,5)) plt.plot(np.arange(pred_num),np.array(preds),'r',label='predctions') cos_y = (np.cos(np.arange(pred_num)*(20*np.pi/1000))+1)/ 2. plt.plot(np.arange(pred_num),cos_y,label='origin') plt.legend() plt.show()
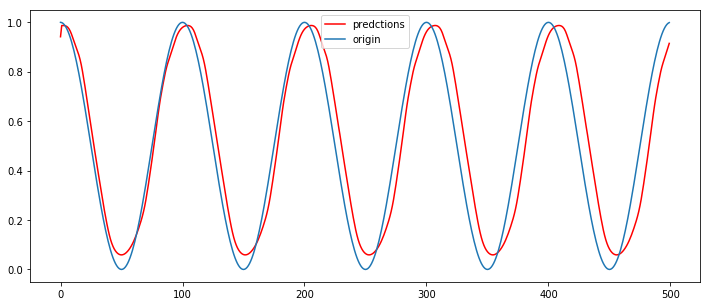
3、双层有状态LSTM模型(序列长度为40)
# 创建数据集,每隔50个就是一个整Π,围绕Π的系数不断变化 dataset = np.cos(np.arange(1000)*(20*np.pi/1000))#dataset的值域再-1~1之间。 # 转换数据为LSTM输入格式: dataset matrix def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset)-look_back): dataX.append(dataset[i:(i+look_back)]) dataY.append(dataset[i + look_back]) return np.array(dataX), np.array(dataY) # 建立模型:双层stacked Stateful LSTM look_back =40 dataset = np.cos(np.arange(1000)*(20*np.pi/1000)) #归一化,y值域为(0,1) dataset = (dataset+1) / 2. # split into train and test sets train_size = int(len(dataset) * 0.8) test_size = len(dataset) - train_size train, test = dataset[:train_size], dataset[train_size:] trainX, trainY = create_dataset(train, look_back) testX, testY = create_dataset(test, look_back) trainX = np.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1)) testX = np.reshape(testX, (testX.shape[0], testX.shape[1], 1)) # 建立模型:有状态 batch_size = 1 model3 = Sequential() model3.add(LSTM(32, batch_input_shape=(batch_size, look_back, 1), stateful=True, return_sequences=True)) model3.add(Dropout(0.3)) model3.add(LSTM(32, batch_input_shape=(batch_size, look_back, 1), stateful=True)) model3.add(Dropout(0.3)) model3.add(Dense(1)) model3.compile(loss='mean_squared_error', optimizer='adam') for i in range(100): print(i) model3.fit(trainX, trainY, epochs=1, batch_size=batch_size, verbose=0, shuffle=False) model3.reset_states() # 预测 x = np.vstack((trainX[-1][1:],(trainY[-1]))) preds = [] pred_num = 500 for i in np.arange(pred_num): pred = model3.predict(x.reshape((1,-1,1)),batch_size = batch_size) preds.append(pred.squeeze()) x = np.vstack((x[1:],pred)) # print(preds[:20]) # print(np.array(preds).shape) plt.figure(figsize=(12,5)) plt.plot(np.arange(pred_num),np.array(preds),'r',label='predctions') cos_y = (np.cos(np.arange(pred_num)*(20*np.pi/1000))+1)/ 2. plt.plot(np.arange(pred_num),cos_y,label='origin') plt.legend() plt.show()
参考连接:

