
LSTM原理介绍及Keras调用接口
一、LSTM原理介绍
RNN虽然理论上也能循环处理长序列,但是由于其结构简单,单元里面只是一个基于tanh激活函数的前馈网络在循环,对于长序列中的哪些信息需要记忆、哪些序列需要忘记,RNN是无法处理的。序列越长,较早的信息就应该忘记,由新的信息来代替,因为上下文语境意境发生了变化,既然RNN无法处理该忘记的信息,那么RNN就不能应用倒长序列中。
而LSTM之所以能够处理长的序列,是因为它通过刻意的设计来处理长期依赖问题,记住该记住的信息、忘记该忘记的信息是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力。LSTM主要通过三个门来进行控制:
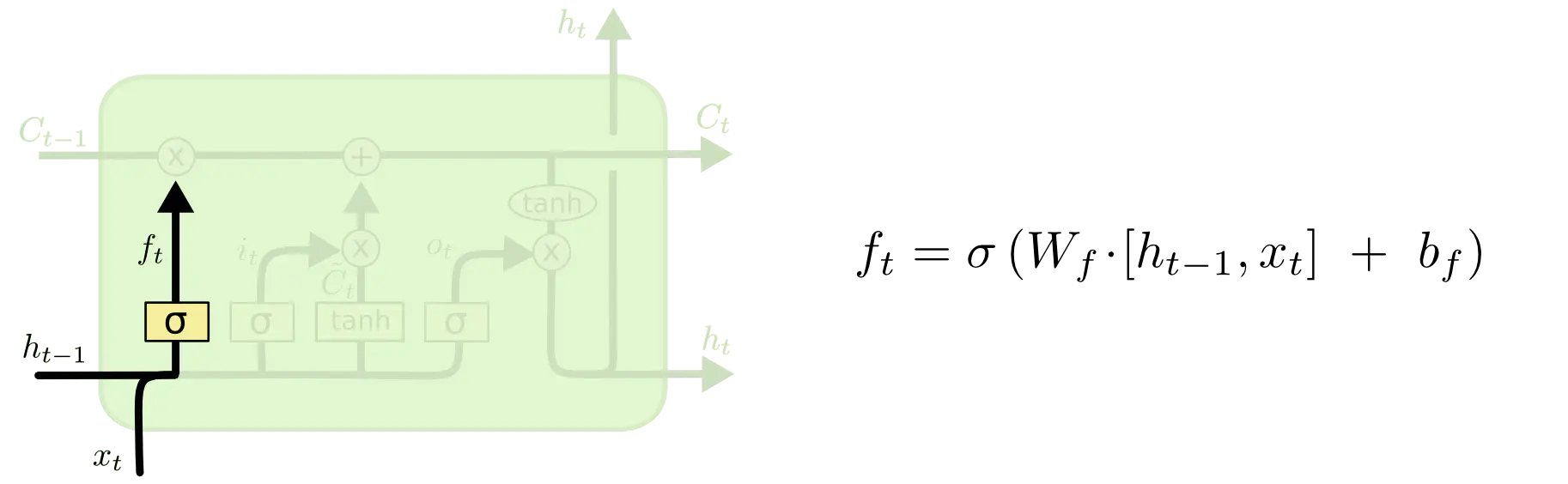
1)遗忘门
遗忘门就是随着语境的变化,忘记掉前面的需要忘记的信,遗忘门的输出是一个sigmoid函数,取值范围为0~1之间,与上一时刻的细胞状态进行按位相乘,0代表该位的信息彻底忘掉,1代表该位的信息完全保留:
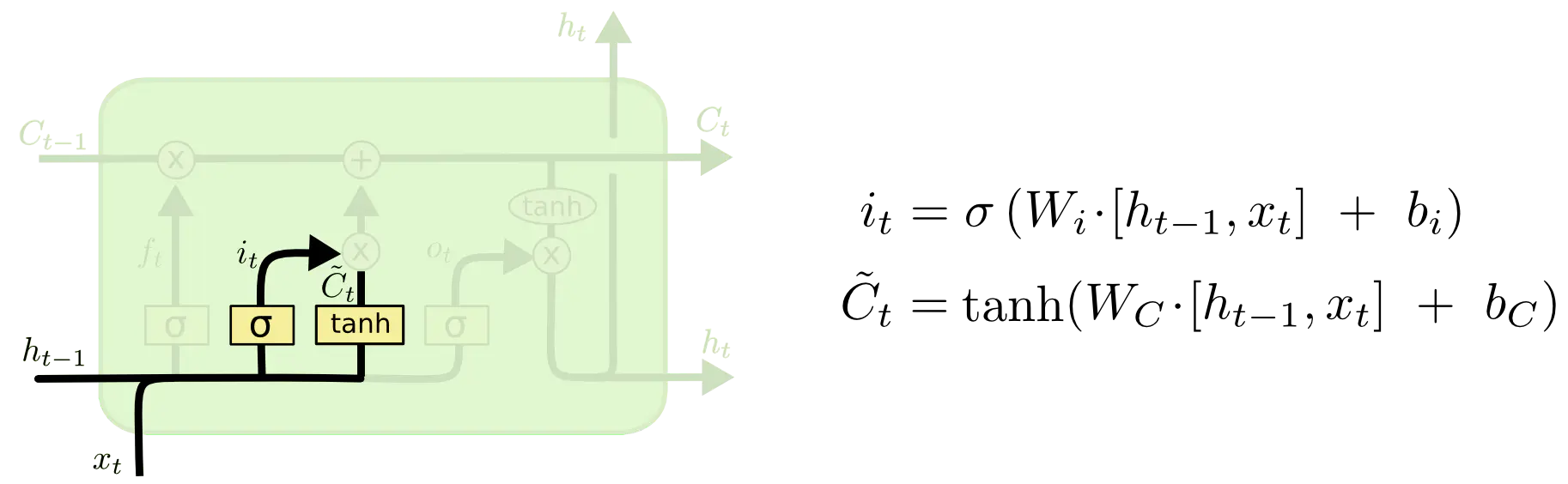
2) 输入门
遗忘门说的是上一个细胞状态的哪些信息需要忘记,而输入门要看的是新的细胞状态的信息哪些需要补充尽量,输入门也是sigmoid函数,取值范围为0~1之间,是与当前的细胞状态按位相乘:
接着新旧状态就可以合并一起了,形成最终新的细胞状态:
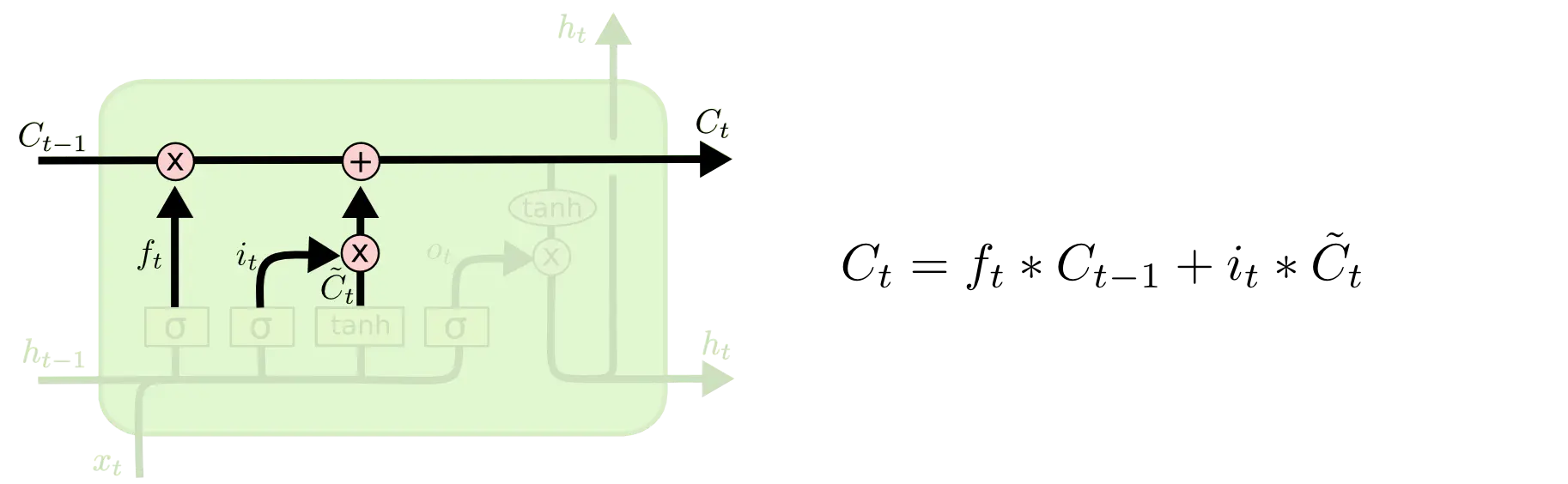
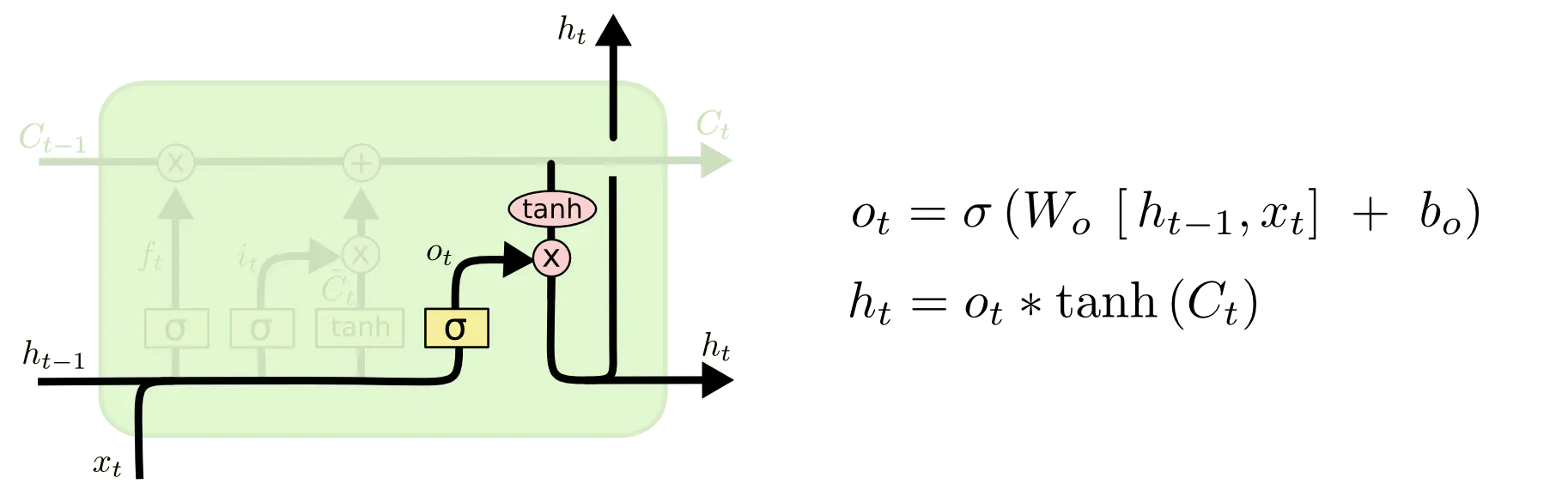
3)输出门
最终的细胞状态加上tanh函数就是输出,然后输出门同上是一个sigmoid的0~1取值,作用于输出,选择哪些信息可以输出:
参考连接:https://www.jianshu.com/p/9dc9f41f0b29
二、LSTM函数介绍(Keras)
keras.layers.LSTM(units, activation='tanh', recurrent_activation='hard_sigmoid', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', unit_forget_bias=True, kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0, implementation=1, return_sequences=False, return_state=False, go_backwards=False, stateful=False, unroll=False)
参数
- units: 正整数,也叫隐藏层,表示的是每个lstm单元里面前馈神经网络的输出维度,每一个门的计算都有一个前馈网络层。
- activation: 要使用的激活函数 ,如果传入
None,则不使用激活函数 (即 线性激活:a(x) = x)。 - recurrent_activation: 用于循环时间步的激活函数 。默认分段线性近似 sigmoid (
hard_sigmoid)。 如果传入None,则不使用激活函数 (即 线性激活:a(x) = x)。 - use_bias: 布尔值,该层是否使用偏置向量。
- kernel_initializer:
kernel权值矩阵的初始化器, 用于输入的线性转换。 - recurrent_initializer:
recurrent_kernel权值矩阵 的初始化器,用于循环层状态的线性转换 。 - bias_initializer:偏置向量的初始化器 .
- unit_forget_bias: 布尔值。 如果为 True,初始化时,将忘记门的偏置加 1。 将其设置为 True 同时还会强制
bias_initializer="zeros"。 这个建议来自 。 - kernel_regularizer: 运用到
kernel权值矩阵的正则化函数。 - recurrent_regularizer: 运用到
recurrent_kernel权值矩阵的正则化函数 。 - bias_regularizer: 运用到偏置向量的正则化函数 。
- activity_regularizer: 运用到层输出(它的激活值)的正则化函数。
- kernel_constraint: 运用到
kernel权值矩阵的约束函数。 - recurrent_constraint: 运用到
recurrent_kernel权值矩阵的约束函数。 - bias_constraint: 运用到偏置向量的约束函数。
- dropout: 在 0 和 1 之间的浮点数。 单元的丢弃比例,用于输入的线性转换。
- recurrent_dropout: 在 0 和 1 之间的浮点数。 单元的丢弃比例,用于循环层状态的线性转换。
- implementation: 实现模式,1 或 2。 模式 1 将把它的操作结构化为更多的小的点积和加法操作, 而模式 2 将把它们分批到更少,更大的操作中。 这些模式在不同的硬件和不同的应用中具有不同的性能配置文件。
- return_sequences: 布尔值。是返回输出序列中的最后一个输出,还是全部序列,True的话返回全部序列,False返回最后一个输出,默认为False。
- return_state: 布尔值。除了输出之外是否返回最后一个状态。
- go_backwards: 布尔值 (默认 False)。 如果为 True,则向后处理输入序列并返回相反的序列。
- stateful: 布尔值 (默认 False)。 如果为 True,则本批次中索引 i 处的每个样品的最后状态,将用作下一批次中索引 i 样品的初始状态。
- unroll: 布尔值 (默认 False)。 如果为 True,则网络将展开,否则将使用符号循环。 展开可以加速 RNN,但它往往会占用更多的内存。 展开只适用于短序列。

