基于keras4bert的seq2seq机制的文章标题生成
一、任务背景介绍
本次训练实战参照的是该篇博客文章:https://kexue.fm/archives/6933
本次训练任务采用的是THUCNews的数据集,THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档,由多个类别的新闻标题和内容组成。本次任务的目标是利用bert结合Unilm模型的思想来训练seq2seq模型,输入由s1和s2两个segment组成,s1是文章内容,s2是文章标题,在输入的时候采用mask机制,可以参照之前的Unilm模型里的mask,如下(蓝色实框表示可见):

在输出计算loss的时候,根据segment id只计算生成标题的损失,也就是以标题部分OK为最大目标。
二、模型训练
1)训练逻辑示意图

2)计算损失示意图

在计算损失时,通过segment id=1控制,只有右侧那部分sequence参与损失计算,w1-w6是什么不关心。
三、预测并解码
1)解码逻辑示意图
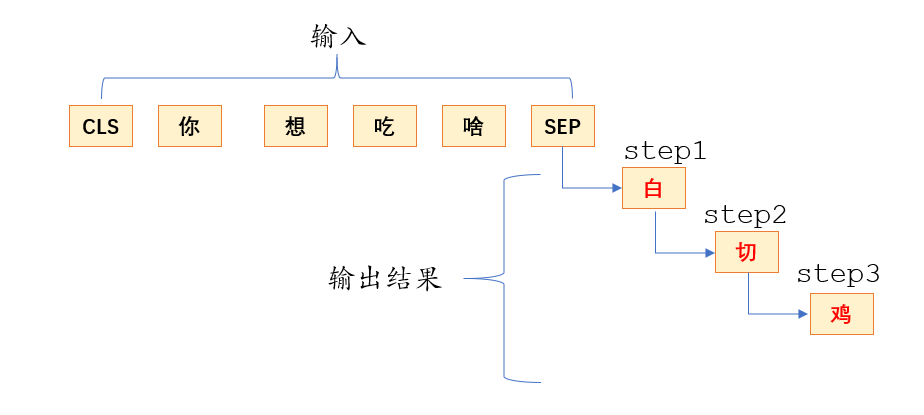
每次的输出都会和输入连接一起作为新的输入进行预测下一个word,直到遇到end符号或者满足最大输出max_len才结束。
2)代码实现(beam_search)
class AutoTitle(AutoRegressiveDecoder): """seq2seq解码器 """ def beam_search(self, inputs, topk): """beam search解码 说明:这里的topk即beam size; 返回:最优解码序列。 """ inputs = [np.array([i]) for i in inputs] output_ids, output_scores = self.first_output_ids, np.zeros(1) quasi_output, quasi_score = [], -np.inf for step in range(self.maxlen): scores = self.predict(inputs, output_ids, step, 'logits') # 计算当前得分,并把最新的output结果也加进去共同作为输入。 if step == 0: # 第1步预测后将输入重复topk次 inputs = [np.repeat(i, topk, axis=0) for i in inputs] scores = output_scores.reshape((-1, 1)) + scores # 计算累积得分,output_scores存的就是之前最大的累计概率,因为是log所以采用相加,相当于乘了 indices = scores.argpartition(-topk, axis=None)[-topk:] # 从最新的累积得分里面再找出tok最大的 indices_1 = indices // scores.shape[1] # 行索引 indices_2 = (indices % scores.shape[1]).reshape((-1, 1)) # 列索引 output_ids = np.concatenate([output_ids[indices_1], indices_2], 1) # 把最新找出来的最大的token_id存放到输出list里面中 output_scores = np.take_along_axis(scores, indices, axis=None) # 更新累积最大得分,每次存的就是累计的最大得分,也就是概率最大 best_one = output_scores.argmax() # 找出最优的序列,因为output_scores里面可能存多个序列,和tok有关,output_scores存的就是序列累计总概率分 if indices_2[best_one, 0] == self.end_id: # 判断是否可以输出 if output_scores[best_one] >= quasi_score: # 跟缓存比较 return output_ids[best_one] # 返回当前最优 else: return quasi_output # 返回缓存的准输出 else: flag = (indices_2[:, 0] == self.end_id) # 标记已完成序列 if flag.any(): idx = output_scores[flag].argmax() # 准最优序列 quasi_output = output_ids[idx] # 准最优序列 quasi_score = output_scores[idx] # 准最优得分 flag = (flag == False) # 标记未完成序列 inputs = [i[flag] for i in inputs] # 只保留未完成部分输入 output_ids = output_ids[flag] # 只保留未完成部分候选集 output_scores = output_scores[flag] # 只保留未完成部分候选得分 topk = flag.sum() # 更新topk的值 # 达到长度直接输出return output_ids[output_scores.argmax()] @AutoRegressiveDecoder.set_rtype('probas') def predict(self, inputs, output_ids, step): token_ids, segment_ids = inputs token_ids = np.concatenate([token_ids, output_ids], 1) segment_ids = np.concatenate([segment_ids, np.ones_like(output_ids)], 1) return model.predict([token_ids, segment_ids])[:, -1]#每次输出只留最后一个对应位输出结果,代表是由前面的输入生成的一个结果,一个个字生成 def generate(self, text, topk=2): max_c_len = maxlen - self.maxlen token_ids, segment_ids = tokenizer.encode(text, max_length=max_c_len) output_ids = self.beam_search([token_ids, segment_ids], topk) # 基于beam search return tokenizer.decode(output_ids) autotitle = AutoTitle(start_id=None, end_id=tokenizer._token_sep_id, maxlen=32) def just_show(): s1 = u'夏天来临,皮肤在强烈紫外线的照射下,晒伤不可避免,因此,晒后及时修复显得尤为重要,否则可能会造成长期伤害。专家表示,选择晒后护肤品要慎重,芦荟凝胶是最安全,有效的一种选择,晒伤严重者,还请及 时 就医 。' s2 = u'8月28日,网络爆料称,华住集团旗下连锁酒店用户数据疑似发生泄露。从卖家发布的内容看,数据包含华住旗下汉庭、禧玥、桔子、宜必思等10余个品牌酒店的住客信息。泄露的信息包括华住官网注册资料、酒店入住登记的身份信息及酒店开房记录,住客姓名、手机号、邮箱、身份证号、登录账号密码等。卖家对这个约5亿条数据打包出售。第三方安全平台威胁猎人对信息出售者提供的三万条数据进行验证,认为数据真实性非常高。当天下午 ,华 住集 团发声明称,已在内部迅速开展核查,并第一时间报警。当晚,上海警方消息称,接到华住集团报案,警方已经介入调查。' s1 = u'夏天' for s in [s1]: print(u'生成标题:', autotitle.generate(s)) print() just_show()
3) numpy其它辅助函数
#求索引位置的函数
Array.argpartition a = np.array([[7,16,15,90],[6,7,91,9]]) #先对原来的数组进行了排序,输出的是排序后值得索引位置,比如6最小,所以第一个就是6的索引位置4 a.argpartition(-2, axis=None) #找出top2的索引位置,里面两个list认为是一个长list构建索引位置的,[-2:]就是取后面最大的两位 a.argpartition(-2, axis=None)[-2:]
OUT:
array([4, 0, 5, 7, 2, 1, 3, 6], dtype=int64)
array([3, 6], dtype=int64)
#数组合并函数 numpy.concatenate a=np.array([[1,2,3],[4,5,6]]) b=np.array([[6]]).reshape((-1, 1)) c=np.array([0]) #将b合并到a的第c个list里面,1表示按列添加,0表示按行添加 np.concatenate([a[c], b], 1)
OUT:
array([[1, 2, 3, 6]])
#根据索引位置提取值 numpy.take_along_axis a=np.array([[7,8,9,10],[99,100,88,87]]) c=np.array([2,5]) #根据c的值作为索引位置在a中进行查找,a中的两个list合并为一个长list构建索引位置的 np.take_along_axis(a,c,axis=None) OUT: array([ 9, 100])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号