paper阅读:UniLM(Unified Language Model Pre-training for Natural Language Understanding and Generation)
概述:
UniLM是微软研究院在Bert的基础上,最新产出的预训练语言模型,被称为统一预训练语言模型。它可以完成单向、序列到序列和双向预测任务,可以说是结合了AR和AE两种语言模型的优点,Unilm在抽象摘要、生成式问题回答和语言生成数据集的抽样领域取得了最优秀的成绩。
一、AR与AE语言模型
AR: Aotoregressive Lanuage Modeling,又叫自回归语言模型。它指的是,依据前面(或后面)出现的tokens来预测当前时刻的token,代表模型有ELMO、GTP等。

AE:Autoencoding Language Modeling,又叫自编码语言。通过上下文信息来预测当前被mask的token,代表有BERT ,Word2Vec(CBOW)。
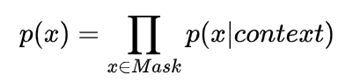
AR 语言模型:
- 缺点:它只能利用单向语义而不能同时利用上下文信息。 ELMO 通过双向都做AR 模型,然后进行拼接,但从结果来看,效果并不是太好。
- 优点: 对自然语言生成任务(NLG)友好,天然符合生成式任务的生成过程。这也是为什么 GPT 能够编故事的原因。
AE 语言模型:
- 缺点: 由于训练中采用了 [MASK] 标记,导致预训练与微调阶段不一致的问题。 此外对于生成式问题, AE 模型也显得捉襟见肘,这也是目前 BERT 为数不多实现大的突破的领域。
- 优点: 能够很好的编码上下文语义信息, 在自然语言理解(NLU)相关的下游任务上表现突出。
二、UniLM介绍
预训练语言模型利用大量的无监督数据,结合上下文语境来预测缺失的文字或者单词,进而使模型学习到上下文相关的文本特征表示。当前已经存在多种预训练模型,但它们的预测任务和训练目标不尽相同。

1)ELMO
ELMO学习的是两个单向的语言模型,由一个前向(从左到右学习)和一个后向(从右向左学习)语言模型构成,其主干网络是LSTM组成,目标函数就是取这两个方向语言模型的最大似然。
前向LSTM:
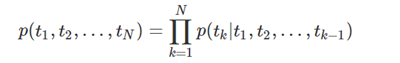
后向LSTM:

最大似然函数:
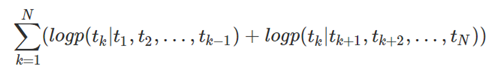
2)GPT
GPT是由Transformer组成的语言模型,采用从左到右一个一个学习word的方式,其实相当于利用了Transformer的解码器,因为解码器是从左到右一个个来的,左边的word看不到右边的信息,右边的word可以看到左边的信息。通过最大化以下似然函数来训练语言模型:
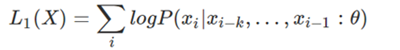
3)BERT
BERT也是由Transformer组成的语言模型,采用的是双向的学习的模式。为什么是双向呢?因为BERT利用的是Transformer的编码器,Transformer的编码器可以同时看到左右的信息。bert的双向学习使得其在NLU任务上有非常出色的表现,但是它在NLG任务上的表现就没有那么优越了。
4)UniLM
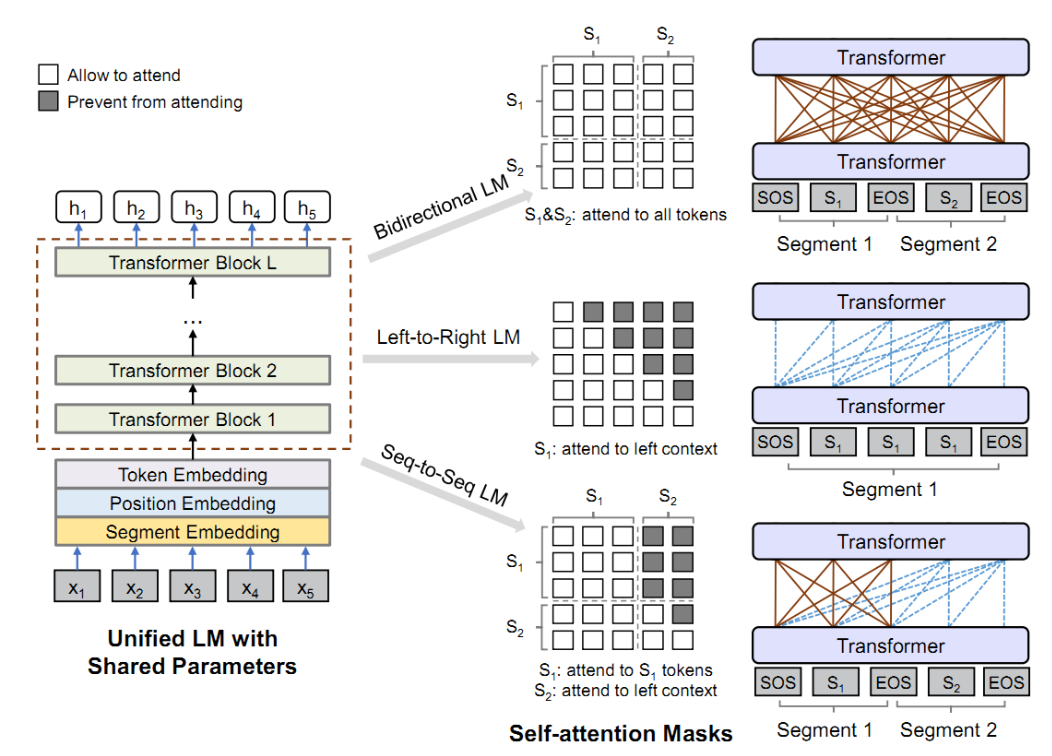
UniLM也是一个多层Transformer网络,跟bert类似,但是UniLM能够同时完成三种预训练目标,如上述表格所示,几乎囊括了上述模型的几种预训练方式,而且新增了sequence-to-sequence训练方式,所以其在NLU和NLG任务上都有很好的表现。UniLM模型基于mask词的语境来完成对mask词的预测,也是完形填空任务。对于不同的训练目标,其语境是不同的。
- 单向训练语言模型,mask词的语境就是其单侧的words,左边或者右边。
- 双向训练语言模型,mask词的语境就是左右两侧的words。
- Seq-to-Seq语言模型,左边的seq我们称source sequence,右边的seq我们称为target sequence,我们要预测的就是target sequence,所以其语境就是所有的source sequence和其左侧已经预测出来的target sequence。
三大优势:
- 三种不同的训练目标,网络参数共享。
- 正是因为网络参数共享,使得模型避免了过拟合于某单一的语言模型,使得学习出来的模型更加general,更具普适性。
- 因为采用了Seq-to-Seq语言模型,使得其在能够完成NLU任务的同时,也能够完成NLG任务,例如:抽象文摘,问答生成。
三、模型架构与实验设置
网络设置:24层Transformer,1024个hidden size,16个attention heads。
参数大小:340M
初始化:直接采用Bert-Large的参数初始化。
激活函数:GELU,与bert一样
dropout比例:0.1
权重衰减因子:0.01
batch size:330
混合训练方式:对于一个batch,1/3时间采用双向(bidirectional)语言模型的目标,1/3的时间采用seq-to-seq语言模型目标,最后1/3平均分配给两种单向学习的语言模型,也就是left-to-right和right-to-left方式各占1/6时间。
masking 方式:总体比例15%,其中80%的情况下直接用[MASK]替代,10%的情况下随机选择一个词替代,最后10%的情况用真实值。还有就是80%的情况是每次只mask一个词,另外20%的情况是mask掉bigram或者trigram。
Attention 控制:不同的训练方式,其关注的语境是不一样的,上面也有介绍,如上图所示,灰色的方格就是不能看到的信息,白色的就是需要attention的信息。如何实现这种控制呢?不让当前预测词看掉的信息就采用掩码隐藏掉,只留下能让当前词可看的信息,换句话说,论文使用了掩码来控制在计算基于上下文的表征时 token 应该关注的上下文的量。下面有详细实现方式。
四、模型输入与骨干网络
模型输入X是一串word序列,该序列要么是用于单向语言模型的一段文本片段,要么是一对文本片段,主要用于双向或者seq-to-seq语言模型 。在输入的起始处会添加一个[SOS]标记,结尾处添加[EOS]标记。[EOS]一方面可以作为NLU任务中的边界标识,另一方面还能在NLG任务中让模型学到何时终止解码过程。其输入表征方式与 BERT 的一样,包括token embedding,position embedding,segment embedding,同时segment embedding还可以作为模型采取何种训练方式(单向,双向,序列到序列)的一种标识。
骨干网络由24层Transformer组成,输入向量 {xi}首先会被转换成H0=[x1,...,x|x|] ,然后送入该24层Transformer网络,每一层编码输出如下:

在每一层通过掩码矩阵M来控制每个词的注意力范围,0表示可以关注,负无穷表示不能关注,会被掩码掉。对于第 l个 Transformer 层,自注意头 AI 的输出的计算方式为:

五、预训练的目标
针对不同语言模型的训练目标,文章设计了四种完形填空任务。在某个完形填空任务中,会随机选择一些WordPiece替换为[MASK],然后通过Transformer网络计算得到相应的输出向量,再把输出向量喂到softmax分类器中,预测被[MASK]的word。UniLM参数优化的目标就是最小化被[MASK] token的预测值和真实值之间的交叉熵。值得注意的是,由于使用的是完形填空任务,所以可以为所有语言模型(无论是单向还是双向)都使用同样的训练流程。
单向语言模型:
单向语言模型,分别采取从左到右和从右到左的训练目标。以从左到右为例子,例如去预测序列"X1X2[MASK]X4"中的掩码,仅仅只有X1,X2和它自己的信息可用,X4的信息是不可用的。这通过上文提到的掩码M矩阵来控制,结合结构图可以看出,主要是上三角的信息不可见,所以在掩码矩阵M中将上三角矩阵的值置为-∞。
双向语言模型:
双向语言模型,还以"X1X2[MASK]X4"为例子,其中X1,X2,X4及自己的信息都可用,所以相比单向语言模型,能够生成更好的与上下文相关token表征。这也是通过掩码矩阵M来控制,都可见,将M的值都置为0即可。
序列到序列语言模型:
左侧的序列其实就是我们的已知序列,叫source sequence,右侧的序列就是我们想要的序列,叫target sequence。左侧的序列属于编码阶段,所以相互的上下文信息都能看到;右侧的序列属于解码阶段,能看到source sequence的信息、target sequence中其左侧的信息及自己的信息。以T1T2->T3T4T5举例说明,我们的输入就变成[SOS]T1T2[EOS]T3T4T5[EOS],T1和T2相互都能看到,并能看到两边的[SOS]和[EOS];而T4能看到[SOS]、T1、T2、[EOS]、T3及自己的信息。
在训练的时候,source sequence和target sequence中的token都会被随机替换为[MASK],以达到模型学习训练的目的。在预测[MASK]的同时,因为这两个语句对被打包在一起了,其实模型也无形中学到了两个语句之间存在的紧密关系。这在NLG任务中,比如抽象文摘,非常有用。
六、下游任务NLU和NLG的Fine-tuning方法
对于NLU任务而言,做fine-tuning的时候,直接微调为双向的transformer编码器,跟bert一样。以文本分类为例子,使用 [SOS] 的编码向量作为输入的编码,表示为![]() ,也就是将UniLM骨干网络的最后一层的[SOS]编码位置输出,作为分类器的初始输入,然后将其输入一个随机初始化的 softmax 分类器(即特定于任务的输出层),其中类别概率的计算方式为
,也就是将UniLM骨干网络的最后一层的[SOS]编码位置输出,作为分类器的初始输入,然后将其输入一个随机初始化的 softmax 分类器(即特定于任务的输出层),其中类别概率的计算方式为 ![]() ,其中
,其中 ![]() 是参数矩阵,C 是类别数量。后面微调的时候,可以同时调整UniLM模型参数及分类器的Wc参数即可。
是参数矩阵,C 是类别数量。后面微调的时候,可以同时调整UniLM模型参数及分类器的Wc参数即可。
对于 NLG 任务,以seq-to-seq任务为例,微调过程类似于使用自注意掩码进行预训练。令 S1 和 S2 分别表示源序列和目标序列,构建出输入[SOS] S1 [EOS] S2 [EOS]。该模型的微调是通过随机掩盖target序列中一定比例的 token,让模型学习恢复被掩盖的词,其训练目标是基于上下文最大化被掩盖 token 的似然度。这点与预训练中略有不同,预训练的时候是随机掩盖掉source序列和target序列的token,也就是两端都参与了训练,而微调的时候只有target参与,因为微调更多关注的是target端。值得注意的是,fine-tuning的时候,target端的结束标识[EOS]也可以被掩盖掉,让模型学习预测,这样模型就可以学习出来自动结束NLG任务了。
七、结合实例具体分析下游Fine-tuning任务
NLU的任务有抽取式问答,NLG的任务主要有抽象文摘、问题生成、生成问题答案和对话响应生成。
1、抽象式文摘(abstractive summarization)
抽象文摘就是根据机器的理解自动生成文摘内容。本实验利用UniLM的sequence-to-sequence模型来完成,在 CNN/DailyMail 数据集上完成摘要任务,在训练集上fine-tuning 30个epochs,微调的超参数与预训练的时候一致,target token被mask的比例为0.7,batch size设置为32,最大长度768,标签平滑设置为0.1。
标签平滑:假设多分类的原label=[0,1,0],经过骨干网络+softmax之后输出预测值=[0.15,0.7,0.15],根据交叉熵公式会得到一个loss,其实这个时候从预测标签中就能看出哪个类别概率大了,但是基于loss函数的导向,会继续减少损失,让中间的0.7越来越靠近1,这样再学习就容易过拟合了,所以引入了标签平滑。标签平滑就是把原label修正一下,相互之间差别不要那么大,例如修改为[0.1,0.8,0.1],这样模型就不至于过分学习了。可以参考标签平滑Label Smoothing和深度学习面试题28:标签平滑(Label smoothing)。
解码的时候,采用集束搜索策略,束宽设置为5。集束搜索详细过程可以参考之前的文章“deeplearning.ai学习seq2seq模型”。
2、生成式问答(Generative QA)
该实验是给一段文本和一个问题,生成形式自由的答案,这也是一个NLG任务,我们这里也是利用sequence-to-sequence模型来完成。soure序列就是一段文本和问题,target序列就是答案。在CoQA数据集上完成实验,共进行10个epochs。target token被mask的比例为0.5,batch size设置为32,最大长度为512,标签平滑设置为0.1。解码的时候束宽设置为3。对于文本特别长的情况下,会利用一个滑动窗口,将文本分成几段,最后把与问答重合度最高的片段送入模型。
3、问题生成(Question Generation)
该任务是给定一个输入段落和一个答案范围,目标是生成一个询问该答案的问题。该任务同样可以转化为一个sequence-to-sequence问题来解决。oure序列就是一段文本和答案,target序列就是问题。target token被mask的比例为0.7,batch size设置为32。
4、多轮对话响应生成(Response Generation)
给定一段多轮对话历史,并将网络文档作为知识源,系统需要生成适合对话并且能反映网络文档内容的自然语言响应。该任务依然采用sequence-to-sequence语言模型来解决。源序列S1=对话历史+知识源,目标序列S2=响应的对话。在DSTC7数据集上进行实验,进行20个epochs,batch size=64,target token被mask的比例为0.5。
未来展望:
(1)继续训练模型到极限,并在多种语言上进行尝试。
(2)目前仅在单语种上进行预训练,后期将会尝试跨语言任务。
(3)在自然语言理解和生成任务上进行多任务的微调学习,对MT-DNN进行拓展。MT-DNN的主要思想就是用BERT初始化,多任务完成微调,BERT没有学出来的,在MT-DNN上微调学习出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号