推荐算法之去重策略
一、背景
推荐系统中,有一个刚需就是去重,去重主要涉及两块:
1)内容源去重,即有些抓取的文章基本是讲的一件事。
2)给用户推荐的内容去重,即不能重复推荐。
对于第一种去重,可以采用Google公布的去重算法Simhash,该算法适合海量数据去重。对于常规的文本相似度计算,需要分词,组合成一个向量,不适合海里文本。
第二种去重可以采用BloomFilter算法,该算法与Bitmap位图算法有相似之处。
二、Simhash去重算法
simhash的核心思想是为每一篇文本生成一个整数表示的指纹,然后用这个指纹去进行去重或者相似度检测。对于一些主要内容不变,有一些不太重要的词句不同的文本,simhash仍然能够得到相似或者相同的指纹。
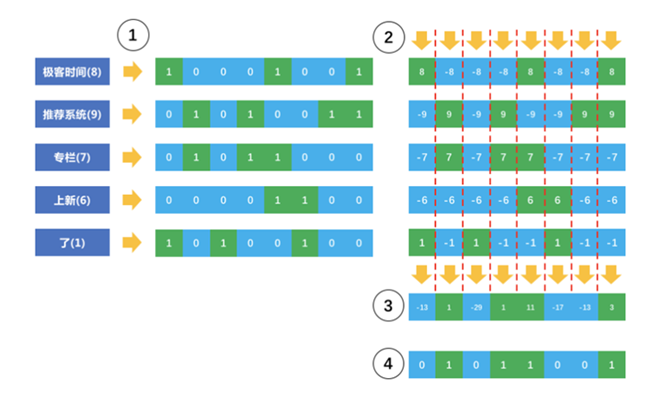
1、首先,对原始内容分词,得到每个词的权重
2、对每个词hash成一个整数,并且把这个整数对应的二进制中的0变成-1,1还是1。
3、每个词hash后的二进制向量乘以权重,形成新的加权向量。
4、把每个词的加权向量相加,得到最终的加权向量,这个向量中元素有正有负。
5、把最终的这个向量正值设置为1,负值设置为0,形成了一个二进制序列,也就最终变成了一个整数,就是该内容的指纹。
该算法的奇妙之处在于,最后加的一个无关紧要的词“了”,可以看出这个词很难改变最终生成的整数,因为其权重比较小,所以其在向量的每一位上,很难改变原有的正负值。所以不太重要的词,就不太影响内容之间的重复检测。
得到每个内容的simhash指纹值之后,可以两两计算之间的海明距离(一个二进制序列变成另外一个二进制序列需要翻转的次数),其实就是两个指纹的异或运算,异或运算结果包含3以下的1,则认为两条内容重复。
三、BloomFilter算法
对于用户量不大的场景,可以把用户推荐过的资讯ID,以K-V的形式存储起来;但是如果用户量巨大,这种做法的消耗不容小视。
该算法如下:

假如是3个hash函数,必须3个hash函数后对应的3个位置都为1,才表示在集合内,有一个是0,就说明元素不在集合内。
需要说明的是,BloomFilter不保证百分之百准确,有很小的概率会把原本不属于集合中的元素判断存在于集合中,当然概率会比较小,hash函数的个数k越多,这种概率就越低。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号