推荐算法之E&E
一、定义
E&E就是探索(explore)和利用(exploit)。
Exploit:基于已知最好策略,开发利用已知具有较高回报的item(贪婪、短期回报),对于推荐来讲就是用户已经发现的兴趣,继续加以利用推荐。
优点:充分利用高回报item。
缺点:容易陷入局部最优,可能错过潜在最高回报的item。
Explore:挖掘未知的潜在可能高回报的的item(非贪婪、长期回报),对于推荐来讲,就是探索用户新的未知的兴趣点,防止推荐越来越窄。
优点:可以发现更高回报的item。
缺点:充分利用已有高回报的item机会减少(如果高回报item之前已经找到,再探索肯定就会浪费高回报的机会)
目标:要找到Exploit & Explore的trade-off,以达到累计回报最大化。
如果Exploit占比太高,那么推荐就会越来越窄,最终收益反倒下降;如果Explore占比过高的话,可能大多是用户不太感兴趣的,浪费的机会比较多,综合收益下降更快。
二、MAB(Multi-armed bandit)多臂赌博机问题
一个赌徒,要去摇赌博机,走进赌场一看,一排赌博机,外表一模一样,但是每个赌博机吐钱的概率可不一样,他不知道每个。他不知道每个赌博机吐钱的概率分布是什么,那么想最大化收益该怎么办?这就是MAB问题,又叫多臂赌博机问题。有很多相似问题都属于MAB问题:
1)假设一个用户对不同类别的内容兴趣程度也不同,当推荐系统初次见到这个用户,如何快速地知道用户对每类内容的感兴趣程度呢?这也是推荐系统常常要面对的冷启动问题。
2)假设系统中有若干个广告库存物料,该给用户展示哪个广告,才能获得最高的点击收益呢?是不是每次都挑选收益最高的哪个呢?
这些问题都是关于选择的问题,只要是选择的问题,都可以简化成一个MAB问题。
Bandit算法就是用来解决此类问题的。
三、Bandit算法
Bandit不是一个算法,而是指一类算法。Bandit算法家族如何衡量选择的好坏呢? 它们使用累计遗憾(collect regret)来衡量策略的优劣。
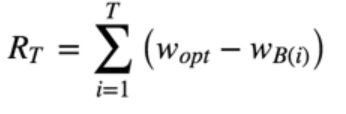
wB(i)是第i次试验时被选中item的回报, w_opt是所有item中的最佳选择item的回报。累计遗憾为T次的选择的遗憾累计,每次选择的遗憾为最优选择回报与本次选择回报之差。
为了简单起见,我们假设每台机器的收益为伯努利收益,即收益要么是0,要么是1。对应到推荐系统中,赌博机即对应我们的物品(item),每次摇臂即认为是该物品的一次展示,我们可以用是否点击来表示收益,点击(win)的收益就是1,没有点击(lose)的收益就是0
比较常用的且效果比较好的Bandit算法主要有Thompson(汤普森)采样算法、UCB(Upper Confidence Bound)算法,后面会单独开讲。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号