deeplearning.ai学习seq2seq模型
一、seq2seq架构图
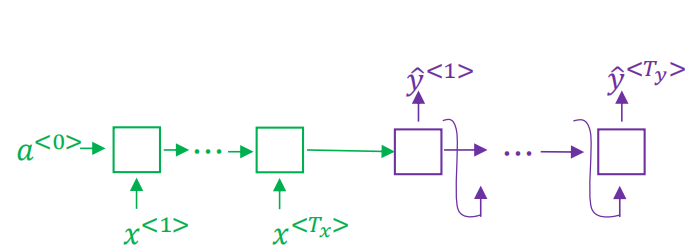
seq2seq模型左边绿色的部分我们称之为encoder,左边的循环输入最终生成一个固定向量作为右侧的输入,右边紫色的部分我们称之为decoder。单看右侧这个结构跟我们之前学习的语言模型非常相似,如下:
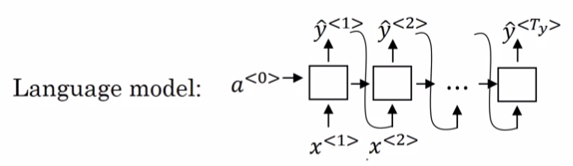
唯一不同的是,语言模型的输入a<0>是一个零向量,而seq2seq模型decoder部分的输入是由encoder编码得到的一个固定向量。所以可以称seq2seq模型为条件语言模型p(y|x)。
语言模型生成的序列y是可以随机生成的,而seq2seq模型用于到机器翻译中,我们是要找到概率最大的序列y,即最可能或者说最好的翻译结果,max p(y|x)。
seq2seq模型如何寻找到最可能的序列y呢?
是不是可以采用贪心算法呢?如果采用贪心算法找的结果不一定是最优的,只能说是其中一个结果。因为贪心算法的思路是先找到第一个最好的y<1>,第一个输出结果y<1>再找到第二个最好的y<2>,以此类推。这种方式的最终结果是每一个元素可能是最优的,但是整个句子却未必是最好的。例如下面的句子:

采用贪心算法,最可能的结果就是第二句,因为如果前两个是Jane is ,第三个最可能的是going,而不是visiting,这是因为is going在英语中大量存在。但是最好的结果却是第一个句子。
二、beam search(集束搜索)
还是以上述机器翻译的例子来解释集束搜索算法流程,第一步如下:

第一步就是先根据左侧的输入,生成第一个输出y<1>,y<1>是softmax转换后的概率输出。集束搜索需要设置集束宽度,本次设置B(beam width)=3,也就是每次仅保留概率最大的top3个。所以,第一步就是选择y<1>中概率最大的前三个词,假设本例子中是in,jane,september,就保留这三个词在内存中。
第二步:
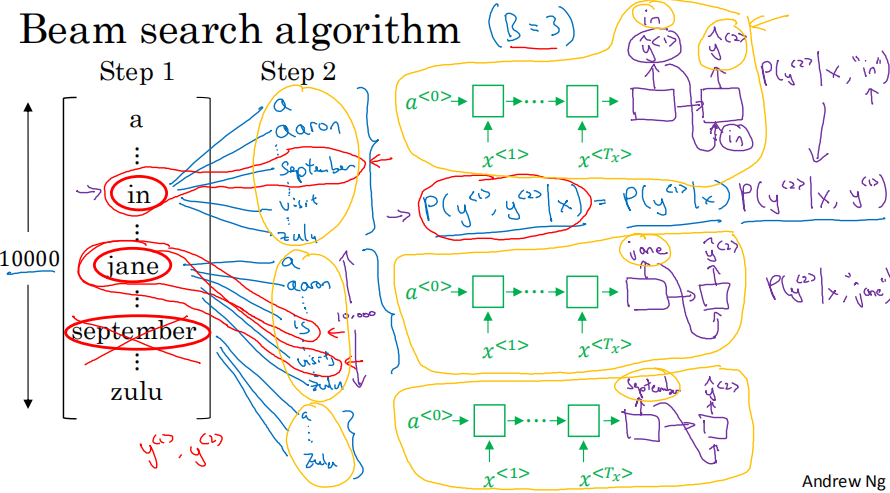
第二步就是在y<1>为in,jane,September的情况下,分别计算第二个词的概率,如上图所示套入三个seq2seq模型中去各自寻找。因为词典维度|v|=10000,所以三个词最终会计算出30000个后面衔接第二个词的概率,最终从这30000个里面选出概率最大的top3个即可,因为集束宽度依然为3。假设第二步筛选出来的结果是in september, jane is,jane visits;September开头的因为连接后面的词后概率偏低,已经被去掉了。
第三步:
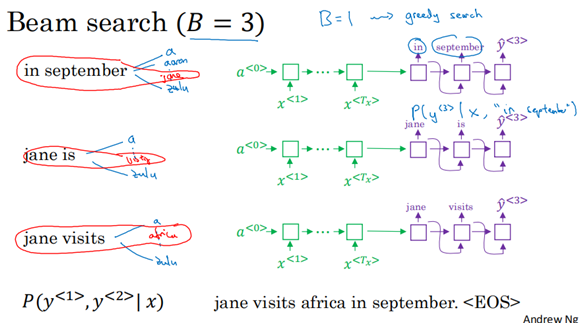
第三步其实是跟第二步一样,直到最后选出EOS结束。
三、beam search的优化
优化一:
将概率的乘积转化成为概率的对数求和。
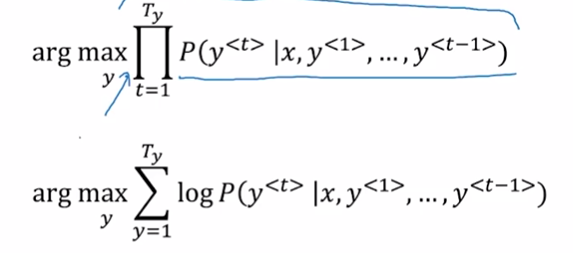
因为乘积的话,会越乘越小,甚至会导致数值的下溢问题。取对数后就变成了连加,就基本解决了这个问题,而且对数后的目标函数与原目标函数解是一致的。
优化二:
归一化目标函数,除以翻译结果的单词数量,减少了对长的结果的惩罚。因为从上述目标函数可以看出,无论原目标函数还是对数目标函数,都不利于长的结果的输出,因为结果越长,连乘或者连加(每个元素取对数后都是负数)都使得概率越来越小。
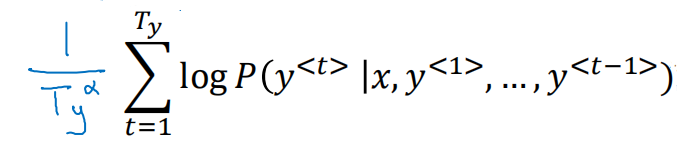
这里的Ty就是翻译结果的单词数量,α是一个超参数,可以设置0(相当于不做归一化),0.7,1,需要根据实际情况调整得到一个最优的结果。
集束宽度B的选择:
large B:效果好,计算代价大,运行慢。
small B:效果差,计算代价小,运行快。
工业中,B=10,往往是一个不错的选择;科研中,为了充分实验,可以尝试100,1000,3000.
B从1~10,性能提升比较明显,但是B从1000~3000,提升就没有那么明显了。
总结,相比于BFS(广度优先搜索)、DFS,beam search不能保证一定能找到arg max 的准确最大值,是一个近似的最大值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号