L2与L1进一步理解
一、函数图形举例解析
函数极值判定定理
1)当该点导数存在,且该导数等于零时,则该点为极值点;
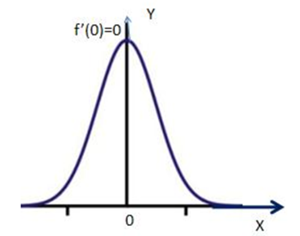
2)当该点导数不存在,左导数和右导数的符号相异时,则该点为极值点。

以一维函数为例,假设原损失函数L曲线如下图:
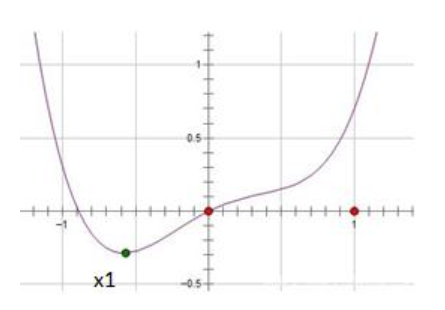
其中X1是函数的极值点,所以L`(x1)=0。
1、求含L2正则化的极值点
令:f(x)=L(x)+Cx2(C>0)
f`(x)=L`(X)+2Cx
∴f`(x1)=L`(x1)+2Cx1=0+2Cx1=2Cx1
又∵x1<0
∴f`(x1)<0
从上图可以得出,f`(0)>0
即:f(x)的导数在x1和0之间为异号
所以,f(x)的极值必然在(x1,0)之间。
结论:从上述分析,带L2正则项的损失函数,达到极值条件的时候,参数值比原损失函数要小。正则项部分在原点处的导数为0,只要原函数在原点处的导数不为0,这个时候f`(x)≠0,极值点就不会存在于原点,所以最优参数值不可能=0,这就解析了为什么L2不会稀疏参数的原因。
2、求含L1正则化的的极值点
令:f(x)=L(x)+C|x|
对f(x)分别两边求导:
x->0+:
f`(x)=L`(x)+C
x->0-:
f`(x)=L`(x)-C
当C>|L`(x)|的时候
f`(x->0+)*f`(x->0-)<0
这个时候极值点就位于0点
结论:只要C满足推论条件,则带L1正则化的损失函数在0点取极值,参数个数就减少了。所以相比L2,L1满足推论条件的概率更大一些,所以更容易参数稀疏化。
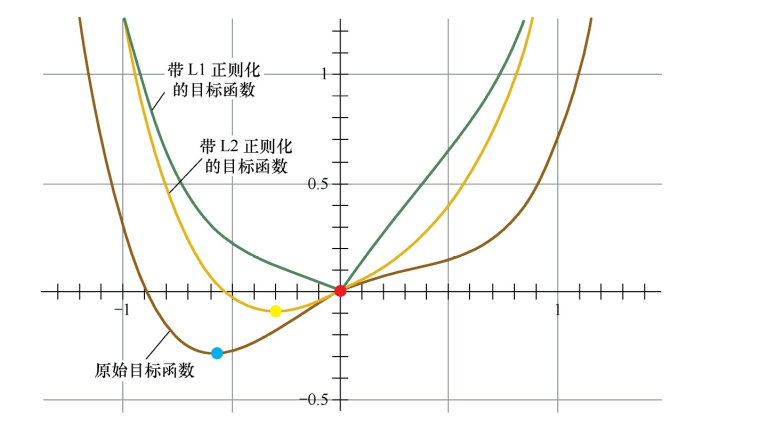
最终函数图形如下:
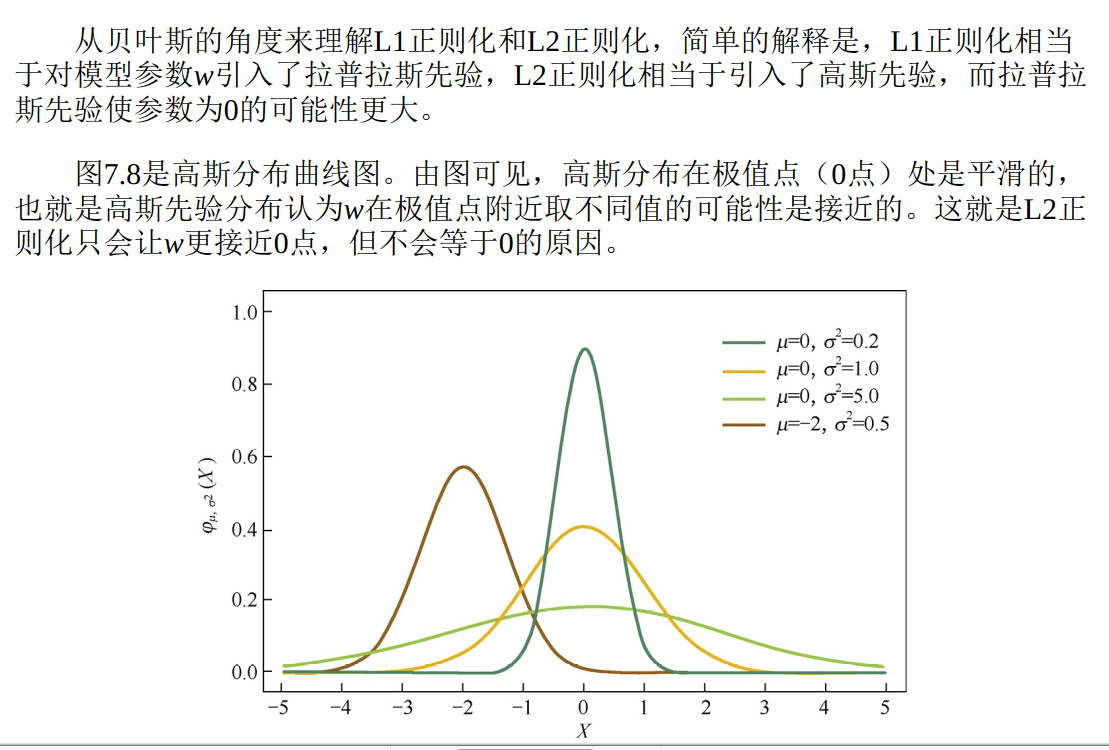
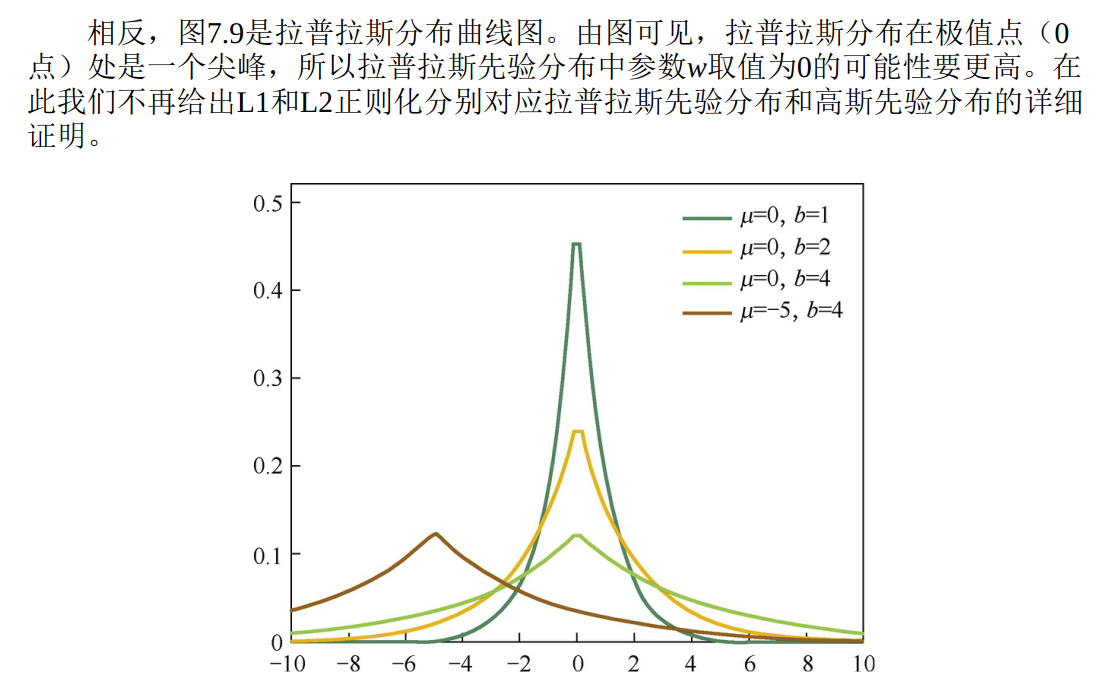
二、贝叶斯先验

 浙公网安备 33010602011771号
浙公网安备 33010602011771号