命名实体识别(NER)
一、任务
Named Entity Recognition,简称NER。主要用于提取时间、地点、人物、组织机构名。
二、应用
知识图谱、情感分析、机器翻译、对话问答系统都有应用。比如,需要利用命名实体识别技术自动识别用户的查询,然后将查询中的实体链接到知识图谱对应的结点上,其识别的准确率将会直接影响到后续的一系列工作。
三、流程图
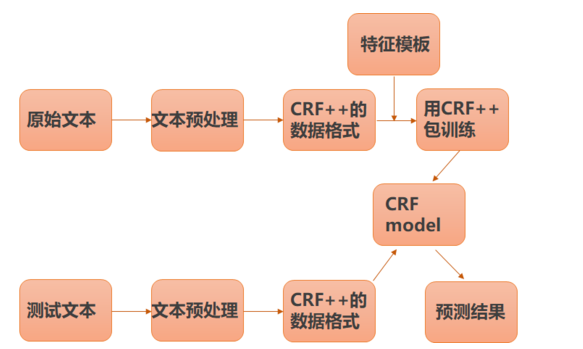
四、标注集
采用BMEWO标注体系进行标注
BME分别代表实体的首部、中部、尾部。W代表单独是一个实体,O代表非实体。
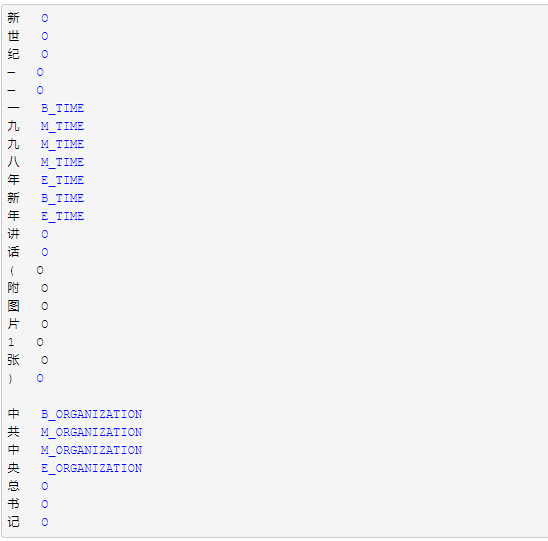
五、NER的难点
1)不同场景不同领域下差异较大,比如新闻领域训练出来的模型,应用到社交领域,效果就非常差劲。但是当前标注的数据集主要集中于新闻领域。
2)目前NER的标注语料较少,标注成本较大,如何从现有较少的语料中学习到更好的模型,或者能从大量未标记语料进行学习,给NER带来了新的挑战。
3)随着时间的推移,出现大量未登录词。
六、用CRF进行识别效果不好怎么办?
可以通过构建更多的特征,比如词性、命名实体的指示代词等,也就是训练样本集中添加更多的列,将词与词的前后关系更明白的告诉特征,模型就学习的更好,说白了就是多做一些特征工程,把隐藏的关系都展开。有了更多的特征列,特征模板也要相应更改一下,可以参照下面的第二个参考文献。
例如:增加特征后,训练语料变成如下形式(汉字、词性、分词边界、地名指示代词、组织名指示代词、人名指示代词,标注tag):

相应模板如下:
# Unigram U00:%x[-2,0] U01:%x[-1,0] U02:%x[0,0] U03:%x[1,0] U04:%x[2,0] U05:%x[-2,1] U06:%x[-1,1] U07:%x[0,1] U08:%x[1,1] U09:%x[2,1] U10:%x[0,0]/%x[0,1] U11:%x[0,0]/%x[1,0] U12:%x[0,0]/%x[-1,0] U13:%x[-1,0]/%x[0,1] U14:%x[0,0]/%x[1,1] U15:%x[-1,0]/%x[-1,1] U16:%x[-1,0]/%x[-2,0] U17:%x[-2,0]/%x[-2,1] U18:%x[1,0]/%x[2,0] U19:%x[-1,1]/%x[1,0] U20:%x[0,1]/%x[1,0] U21:%x[-2,1]/%x[-1,1] U22:%x[0,1]/%x[-2,1] U23:%x[-1,1]/%x[0,1] U24:%x[-1,1]/%x[1,1] U25:%x[0,1]/%x[1,1] U26:%x[0,1]/%x[2,1] U27:%x[1,1]/%x[2,1] U28:%x[-1,2] U29:%x[-2,2] U30:%x[-1,2]/%x[-2,2] U31:%x[0,1]/%x[-1,2] U32:%x[0,1]/%x[-2,2] U33:%x[0,1]/%x[1,2] U34:%x[0,0]/%x[-1,2] U35:%x[0,0]/%x[-2,2] U36:%x[0,0]/%x[1,2] U37:%x[0,1]/%x[-1,2]/%x[-2,2] U38:%x[-1,2]/%x[0,1]/%x[1,1] U39:%x[-1,2]/%x[-1,1]/%x[0,1] U40:%x[-1,2]/%x[0,1]/%x[0,0] U41:%x[-2,2]/%x[-1,2]/%x[0,1] U42:%x[-2,3]/%x[-1,3]/%x[1,3]%x[2,3] U43:%x[-2,4]/%x[-1,4]/%x[1,4]%x[2,4] U44:%x[-2,5]/%x[-1,5]/%x[1,5]%x[2,5] # Bigram B
参考文献:https://www.cnblogs.com/lookfor404/p/9189429.html
参考文献:https://www.jianshu.com/p/235d3aaf0929(该文是上述参考文献的第二篇,里面详细介绍了通过构建命名实体的指示代词来提高模型的学习效果)
参考文献:https://www.zybuluo.com/lianjizhe/note/1205311(该文是上述参考文献的第三篇,里面又新加了常用词特征,效果不错)
参考文献:https://www.jianshu.com/p/495c23aa5560 (BiLSTM+CRF)
参考文献:https://www.jianshu.com/p/34a5c6b9bb3e (中文命名实体识别全总结,包括BiLSTM+CRF)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号