Java应用程序远程提交FLink任务
1 解决问题
解决了flink任务提交依赖传统Jar提交的问题,改为Java应用程序获取RemoteEnvironment方式提交,便于维护管理等。
通过次提交方式,可以做进一步的延伸,通过Flink版本管理,Sql管理。只需要简单的存储版本信息,某个任务的Sql信息,就能快速实现任务提交,以此来摒弃传统的Jar任务提交。进一步来讲,Flink越来越重视FlinkSql,从Flink的更新,以及维护来看,Flink的未来将着重于SQL,以高级的SQL API取缔其他API。所以,总的来说Flink Sql有无限前景。
2 测试用例
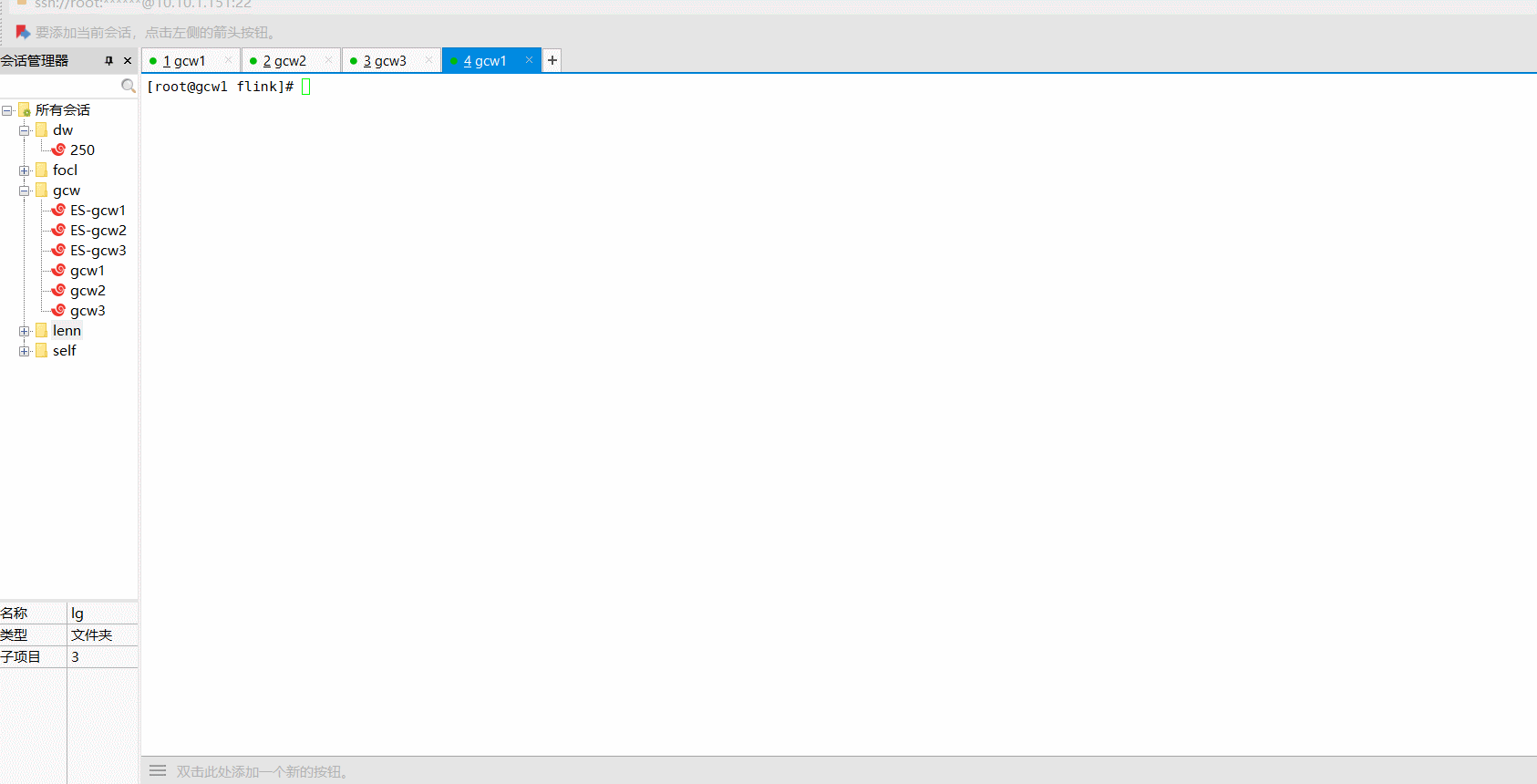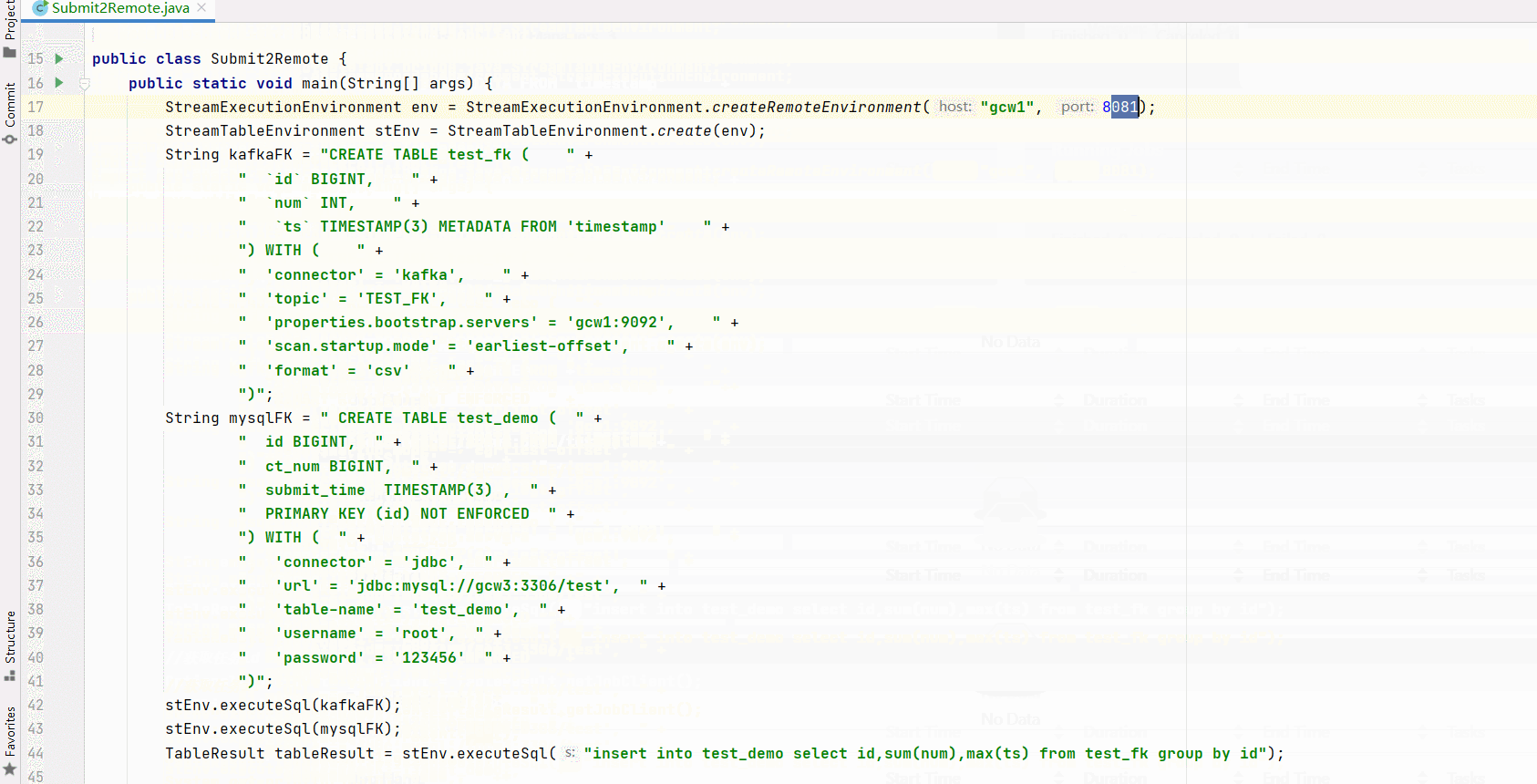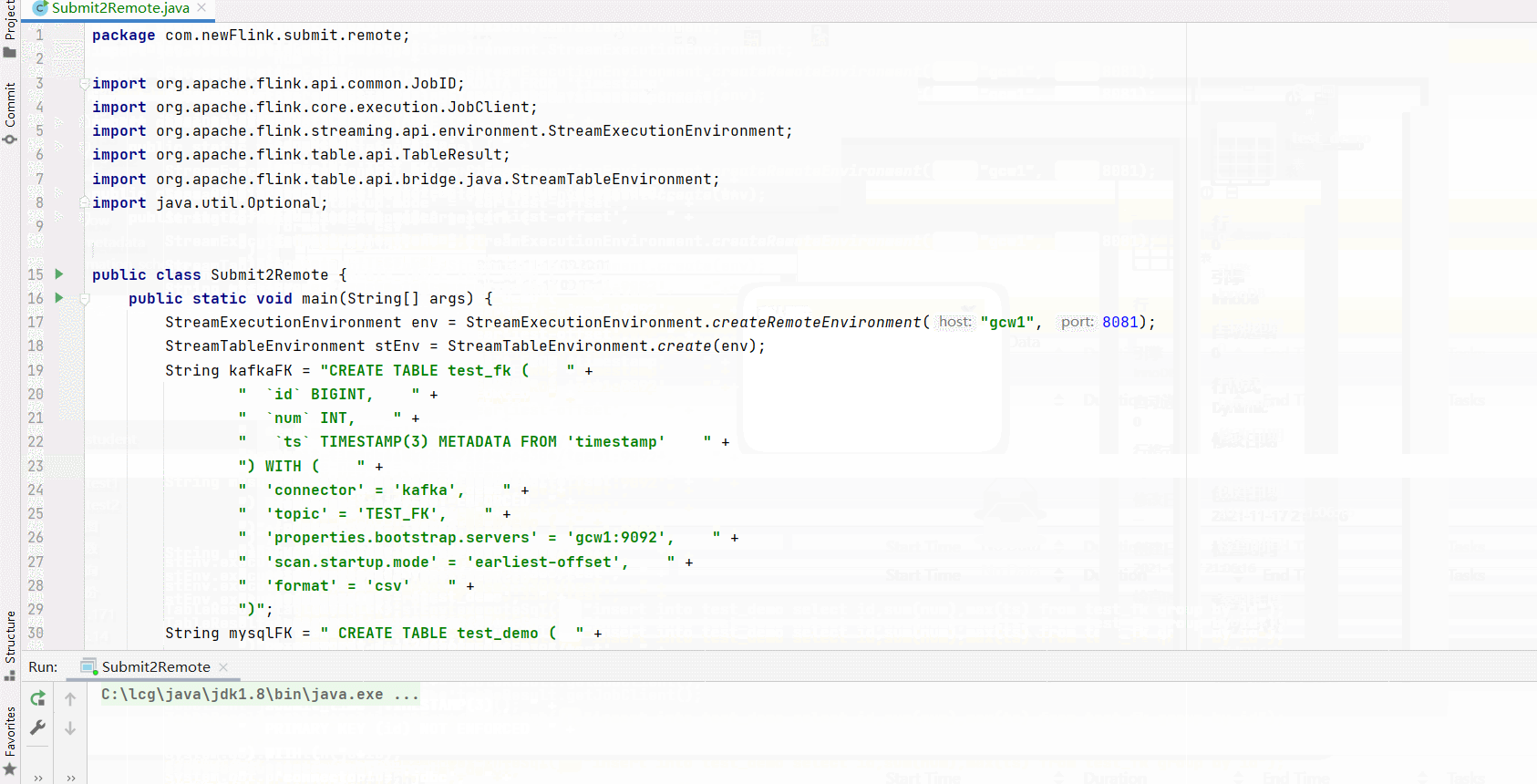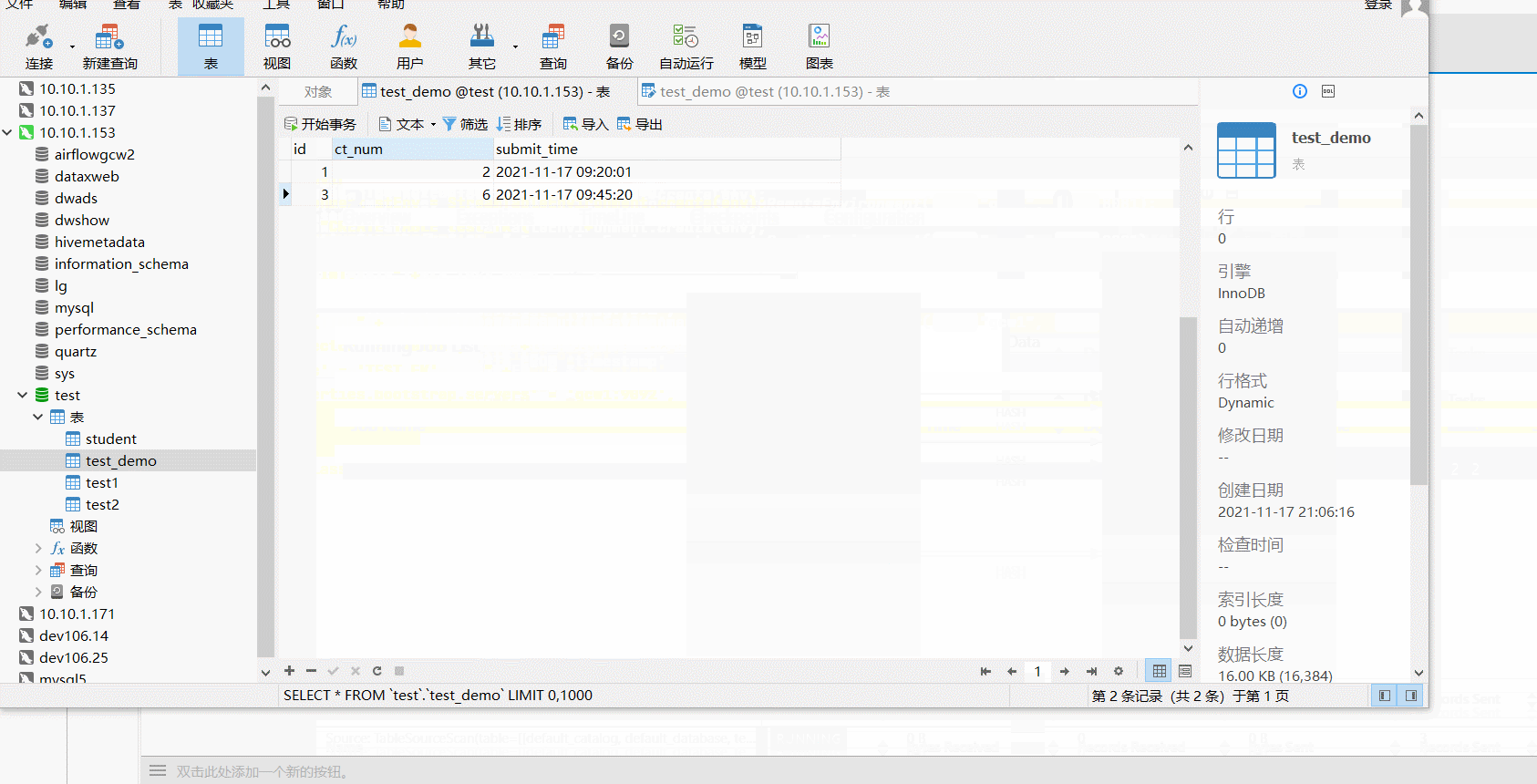
测试从kafka消费数据,保存到Mysql,此测试用例不涉及任何业务,且无实际意义,只是为了实现JavaAPI提交。
当然,你也可以实现Mysql -> Mysql
3 代码实现
StreamExecutionEnvironment env = StreamExecutionEnvironment.createRemoteEnvironment("gcw1", 8081);
StreamTableEnvironment stEnv = StreamTableEnvironment.create(env);
String kafkaFK = "CREATE TABLE test_fk ( " +
" `id` BIGINT, " +
" `num` INT, " +
" `ts` TIMESTAMP(3) METADATA FROM 'timestamp' " +
") WITH ( " +
" 'connector' = 'kafka', " +
" 'topic' = 'TEST_FK', " +
" 'properties.bootstrap.servers' = 'gcw1:9092', " +
" 'scan.startup.mode' = 'earliest-offset', " +
" 'format' = 'csv' " +
")";
String mysqlFK = " CREATE TABLE test_demo ( " +
" id BIGINT, " +
" ct_num BIGINT, " +
" submit_time TIMESTAMP(3) , " +
" PRIMARY KEY (id) NOT ENFORCED " +
") WITH ( " +
" 'connector' = 'jdbc', " +
" 'url' = 'jdbc:mysql://gcw3:3306/test', " +
" 'table-name' = 'test_demo', " +
" 'username' = 'root', " +
" 'password' = '123456' " +
")";
stEnv.executeSql(kafkaFK);
stEnv.executeSql(mysqlFK);
TableResult tableResult = stEnv.executeSql("insert into test_demo select id,sum(num),max(ts) from test_fk group by id");
//获取任务id
Optional<JobClient> jobClient = tableResult.getJobClient();
JobClient jobClient1 = jobClient.get();
JobID jobID = jobClient1.getJobID();
System.out.println(jobID);
4 实现演示
演示用到了kafka集群,flink的standalone模式,请确保flink节点中kafka可以使用
5 实现过程中遇到的问题
5.1 版本问题
- 确保应用程序与Flink集群版本一致,否则可能会有问题 😆
- kafka的连接器要选择sql-connector的
- 确保你的pom文件合适,下面提供了项目地址,你可查看我的pom
5.2 Flink集群节点问题
- 确保每个Flink的lib下有你需要的连接器,连接驱动等
- 确保Flink每个节点能使用Kafka(如果你不是用kafka可以略过)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号